Wie viele von Ihnen bereits wissen, ist DoiT International die Engineering-Power hinter reOptimize (heute Teil von DoiT Cloud Intelligence™) – dem SaaS für Cost Discovery und Kostenoptimierung auf der Google Cloud Platform.
Mit reOptimize erhalten Sie unmittelbare Einblicke in Ihre Abrechnung der Google Cloud Platform, verwalten Budgets, richten Kostenzuordnungen ein und probieren unterschiedliche Strategien zur Kostenoptimierung aus.
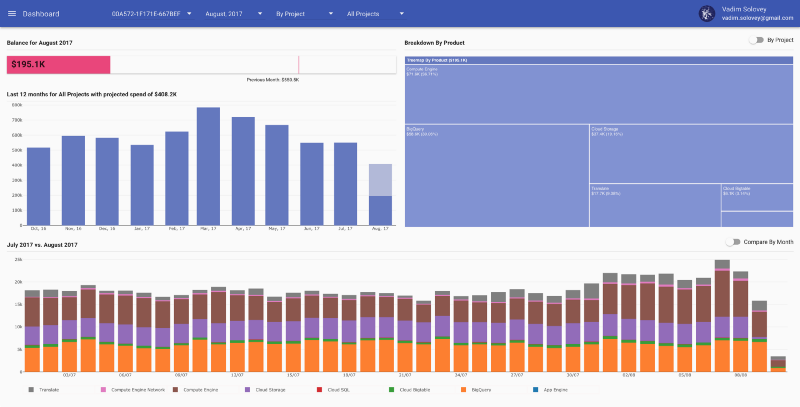
reOptimize Dashboard
Eines der Features, das von Anfang an dabei war, ist eine Schätzung, wie Ihre Monatsrechnung am Monatsende ausfallen wird. So sieht das im Dashboard von reOptimize aus:
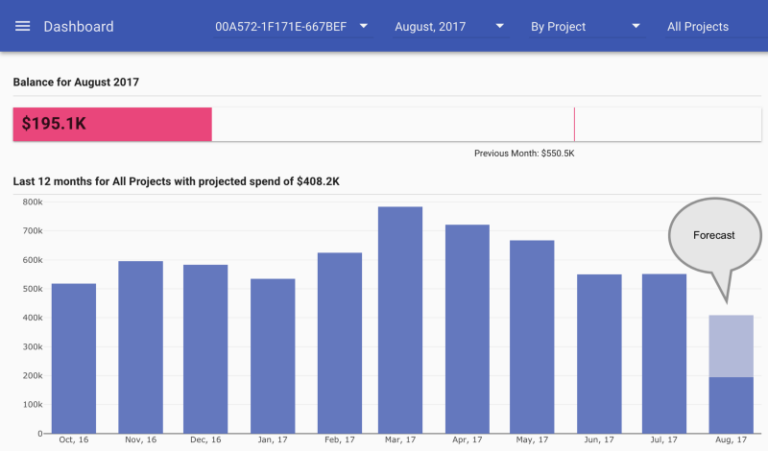
Google Cloud Platform Billing Forecast
Anfangs setzte unser Schätzmodell auf eine sehr simple lineare Regression: Wir nahmen die bisherigen Ausgaben sowie den aktuellen Tag des Monats und extrapolierten den Wert unter der Annahme, dass die Ausgaben linear weiterwachsen. Wir haben zwar einige Anpassungen vorgenommen, etwa die Sustained Discounts der Google Compute Engine berücksichtigt und ein paar weitere Details, aber im Kern blieb das Verfahren naiv und simpel.
Cloud-Services sind leider kumulativ, und Cloud-Ausgaben verhalten sich grundsätzlich überhaupt nicht linear. Es gibt saisonale Muster wie längere oder kürzere Monate, Feiertagsphasen, Marketingkampagnen und vieles mehr! Die Schätzung dieses Modells lag in der Regel ziemlich daneben. Wir haben dafür eine Wurzel der mittleren quadratischen Abweichung (RMSE) von ~900 ermittelt.
Da viele unserer Kunden auf reOptimize setzen, um ihre Ausgaben in der Google Cloud Platform zu prognostizieren, haben wir begonnen, an einem Machine-Learning-basierten Modell zu arbeiten, um die Genauigkeit unserer Schätzungen zu erhöhen.
Naheliegenderweise haben wir uns für TensorFlow entschieden – eine Open-Source-Softwarebibliothek für Machine Intelligence – und konkret für Google CloudML, den Managed Service von Google für TensorFlow. So mussten wir uns nicht um Skalierung, Deployment, Monitoring und andere wenig spannende Betriebsthemen kümmern ;-)
Unser Projekt besteht aus drei wesentlichen Teilen:
- Aufbereitung der historischen Daten zum Training unseres Modells
- Training eines Vorhersagemodells
- Deployment des Modells für die Nutzung durch reOptimize
All diese Schritte müssen automatisch und iterativ ablaufen, da täglich neue Abrechnungsdaten eintreffen.
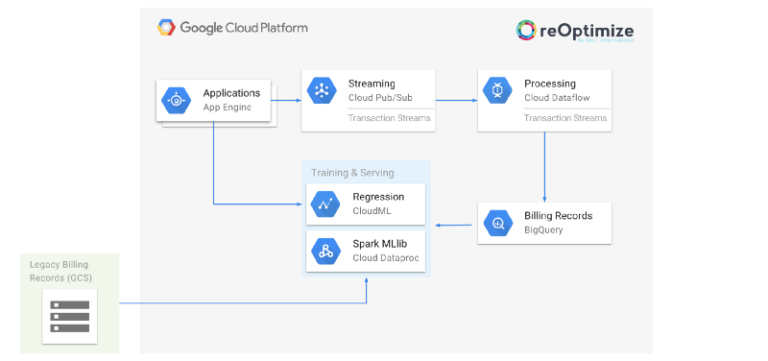
reOptimize Machine Learning Based Prediction Architecture
Trainingsdaten vorbereiten
Die Google Cloud Billing API kann Abrechnungsdaten in verschiedene Ziele exportieren – eines davon ist Google BigQuery. Wir nutzen eine BigQuery-Tabelle als Datenquelle, um unser Vorhersagemodell zu trainieren.
Die Tabelle enthält folgende Spalten:
project.id - Die GCP-Projekt-IDproduct - Der GCP-Servicename (z. B. BigQuery, Compute Engine, etc.)start_time - Datum und Uhrzeit dieser Abrechnungszeilecost - Kosten in US-Dollarcredits.name - Ein wiederholtes Feld mit Namen relevanter Creditscredits.amount - Ein wiederholtes Feld mit Beträgen relevanter CreditsUm den Trainingsprozess zu optimieren, möchten wir die Rohdaten in ein für TensorFlow besser geeignetes Format überführen. Das betrifft sowohl das Format selbst als auch die Semantik der Daten.
TensorFlow unterstützt mehrere Formate, das Standardformat heißt jedoch TFRecords. Es gibt zahlreiche integrierte Hilfsfunktionen, um Daten in diesem Format zu lesen und zu schreiben.
Auch die Semantik der Daten sollte in Werte überführt werden, die für ein DNN am besten geeignet sind. Ein DNN bzw. Deep Neural Network ist ein mathematisches Modell, das im Machine Learning eingesetzt wird und sich an der Funktionsweise des menschlichen Gehirns orientiert.
Ein DNN funktioniert nicht gut mit Eingaben, die keine Zahlen sind – idealerweise Zahlen mit echter Bedeutung. Produkt- und Projektnamen etwa sagen für sich genommen wenig aus, ebenso Jahres- oder Monatswerte. Der numerische Tageswert dagegen hat eine solche Bedeutung, ebenso wie die Kosten. Auch die rohen Kostenzeilen einfach einzuspeisen, wäre wenig zielführend, da wir pro Sample einen Zielwert benötigen.
Wir transformieren die Daten aus BigQuery in eine Form, die besser zu unserem DNN-Modell passt.
Am sinnvollsten erschien uns, unsere Samples folgendermaßen zu definieren: eine tägliche Aggregation pro Produkt und Projekt sowie die Summe der Kosten vom Monatsanfang bis zu diesem Tag. Außerdem benötigen wir die Gesamtkosten für dieses Produkt und Projekt im jeweiligen Monat als Zielwert für das Training. Schließlich müssen die Produkt- und Projektnamen zunächst auf Ganzzahlen abgebildet werden.
In unserem Fall enthält jedes Sample also Projekt, Produkt, Tag, Teilkosten (seit Monatsbeginn) und Gesamtkosten. Damit das DNN die Daten besser verstehen kann, möchten wir das Sample um zusätzliche Informationen anreichern, die hilfreich sein dürften, vom DNN selbst aber nur schwer zu berechnen sind.
Die Anzahl der Tage im aktuellen Monat ist eine willkürliche Konstante, die die Gesamtkosten beeinflussen kann. Diesen Wert können wir für das DNN "vorberechnen" und sparen so Zeit und Komplexität. Ebenso lässt sich das Verhältnis der Kosten pro Tag berechnen, indem wir die Teilkosten durch den aktuellen Tag teilen.
Ein weiterer nützlicher Wert wäre das durchschnittliche Verhältnis sowie die durchschnittlichen Gesamtkosten für Produkt und Projekt – Werte, die vermutlich auch ein Mensch heranziehen würde, um die Monatsrechnung zu prognostizieren. Über BigQuery lässt sich problemlos eine Mapping-Tabelle erzeugen, die diese Mittelwerte pro Projekt und Produkt liefert; daraus haben wir eine statische Lookup-Tabelle gebaut, mit der die Samples angereichert werden.
Einige weitere Verhältnisse haben wir berechnet, um dem DNN zusätzliche Informationen bereitzustellen, etwa die geschätzten linearen Gesamtkosten (also Verhältnis * Tage im Monat).
Mit den Daten in der Hand speisen wir die Samples nun nacheinander zusammen mit dem Label-Wert ein. Wir trainieren das Modell darauf, aus den Eingabewerten eines Samples die Gesamtkosten vorherzusagen. Später können wir das Modell so nutzen, dass wir die aktuellen Ausgaben und das Datum pro Projekt und Produkt einspeisen und die Gesamtkosten zum Monatsende vorhersagen.
Mit den fertig aufbereiteten Daten wollten wir eine Möglichkeit haben, unser Modell gegen den aktuellen Stand zu bewerten. Dazu haben wir mit den transformierten Daten die einfache lineare Regression nachgerechnet, die unser heutiger Code durchführt. Für jedes Sample haben wir die erwarteten Gesamtkosten von der Vorhersage abgezogen, den Wert quadriert und anschließend den Durchschnitt über alle Samples gebildet. Die Wurzel daraus ist der RMSE. Wir kamen auf einen RMSE von ~900.
Beim Blick auf die Daten zu diesem Zeitpunkt war offensichtlich, dass sie sich keineswegs linear verhielten. Ein DNN zu bauen, das solche Daten vorhersagen kann, wäre sehr schwierig – wir können den Aufbau eines einfacheren DNN aber erleichtern, indem wir das Netz mit berechneten Werten füttern, von denen wir bereits wissen, dass sie relevant sind. Dazu möchten wir die Daten nicht nur transformieren, sondern auch anreichern.
Hilfreich erscheint zum Beispiel, einen Wert mit dem Verhältnis zwischen den aktuellen Kosten seit Monatsbeginn und den Tagen seit Monatsbeginn einzuspeisen. Dieser Wert lässt sich auch pro Monat oder global mitteln und liefert zusätzliche Hinweise auf das Ausgabeverhalten.
Und natürlich kann es dem DNN helfen, die historischen Gesamtkosten der vergangenen Monate zu kennen – daher ergänzen wir die durchschnittlichen Gesamtkosten je Monat sowie einen globalen Durchschnitt der Gesamtkosten.
So sieht die Preprocessing-Funktion aus, die wir gebaut haben:
Anschließend wollen wir alles im TFRecord-Format zusammenpacken, bereit fürs Training. Glücklicherweise gibt es bereits ein Paket, das uns dabei unterstützt. Das Python-Paket tensorflow-transform nutzt eine Kombination aus TensorFlow und Apache Beam, um große Datenmengen zu verarbeiten, zu transformieren und in TFRecord-Dateien zu schreiben.
Ein weiterer Vorteil von tensorflow-transform: Es erzeugt einen TensorFlow-Graphen für die Datenverarbeitung und führt diesen über eine Beam-Pipeline aus. Dadurch lässt sich derselbe Graph später auch für die Vorhersage verwenden – sämtliche Datentransformationen erledigt er für Sie, sodass Sie die Daten vor der Vorhersage nicht erneut aufbereiten müssen.
Im Kern des Preprocessing-Skripts läuft die Apache-Beam-Pipeline:
Die Funktion get_data_from_bq liest die BigQuery-Daten über die oben gezeigte SQL-Abfrage.
Anschließend nutzt sie AnalyzeAndTransformDataset für die eigentliche Verarbeitung. AnalyzeAndTransformDataset benötigt eine Preprocessing-Funktion, die den Transformationsgraphen definiert. Die transformierten Daten werden im TFRecord-Format in zwei Datei-Sets für Training und Test geschrieben.
Zusätzlich zu den Daten speichert die Pipeline die Metadaten für das Modell, einschließlich der Roh-Eingabe-Metadaten, der Metadaten der transformierten Daten und des Graphen der Transformationsfunktion. Diese werden später für das Training des Modells verwendet.
Das Modell trainieren
Sobald die Daten bereitstehen, geht es im nächsten Schritt darum, mit den eben aufbereiteten Daten ein Modell zu trainieren.
Wir haben uns für ein einfaches DNN entschieden und trainieren es mit der TensorFlow-Klasse DNNRegressor. Die im Preprocessing-Schritt von tensorflow-transform erzeugten Metadaten dienen nun dazu, Input-Funktionen für Training, Test und Serving zu erstellen.
Schließlich nutzen wir TensorFlows contrib.learn.Experiment, um Training und Evaluation zu koordinieren.
Dazu definieren wir eine Funktion, die das Experiment erzeugt:
Und nutzen sie dann, um das Experiment auszuführen:
Das Ergebnis dieses Prozesses ist ein Verzeichnis mit dem gespeicherten Modell, das wir später auf Google CloudML deployen können, um echte Vorhersagen zu treffen.
Das Modell deployen
Damit reOptimize die Vorhersagen nutzen kann, brauchen wir natürlich eine Infrastruktur, die API-Anfragen aus der Anwendung beantwortet und die Modellausgabe zurückliefert.
Genau das leistet Google CloudML mit TensorFlow Serving. TensorFlow Serving lädt ein trainiertes Modell von einer lokalen Festplatte oder aus einem GCS-Bucket, führt es aus und liefert die Ausgabe zurück. Es stellt eine RESTful-API bereit, die sich von beliebigen Web- oder Mobile-Clients aus ansprechen lässt. Google CloudML geht noch einen Schritt weiter und liefert eine serverlose, vollständig verwaltete Serving-Infrastruktur für Ihr Modell – Sie müssen weder Maschinen aufsetzen noch Autoscaling einrichten.
Nachdem unser Modell trainiert und gespeichert ist, deployen wir es über die gcloud-Kommandozeile.
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeDaraus entsteht eine URL, über die Vorhersagen mit unserem Modell möglich sind. Sie verweist auf einen vollständig verwalteten Backend-API-Service von Google CloudML.
Sie nimmt sowohl REST-Aufrufe entgegen als auch Aufrufe über das gcloud-Kommandozeilentool wie hier:
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsonDie Datei data/predict.json enthält Informationen wie diese:
Und die Ergebnisse sehen etwa so aus:
Fazit
Durch den Einsatz von Machine Learning zur Vorhersage der Rechnungen für die Google Cloud Platform sind unsere Prognosen heute deutlich genauer. Sie berücksichtigen (indirekt) eine enorme Menge an Signalen wie Saisonalität, Änderungen an Preismodellen, Marketingkampagnen und vieles mehr.
Unser RMSE ist von ~900 auf nur noch ~100 gesunken. Unsere Vorhersagen sind dadurch deutlich belastbarer, und unsere Kunden können sich darauf verlassen.
Mit Google CloudML, Dataflow und BigQuery konnten wir die Machine-Learning-Infrastruktur in reOptimize in nur wenigen Wochen umsetzen – und dabei mehr Zeit ins Engineering statt in Betrieb oder Wartung investieren.