TensorFlow Extendedは、本番運用レベルのMLパイプラインを構築するためのエンドツーエンドプラットフォームです。

MLパイプラインを動かすには、それを実行するオーケストレーターが必要です。本記事ではオーケストレーターとしてKubeflowを使います。
読み終える頃には、KubeflowとTensorFlow Extendedがいかに相性抜群かを実感していただけるはずです ❤️。
本記事では、TensorFlow Extendedパイプラインの作成方法を解説したうえで、TensorFlow Extendedの組み込み機能を使ってKubeflow Pipelinesにデプロイし、最後にCI/CDで自動化する方法まで掘り下げていきます。
これまでのおさらい
前回の記事「TensorFlow Extended 101」では、TFXパイプラインを作成するために知っておきたい内容をひととおり解説しました。本記事では、そこからさらに一歩踏み込みます。
AI Platform Pipelinesとは何か、なぜ使うのか
AI Platform Pipelinesを語ることは、すなわちKubeflowを語ることでもあります。
Kubeflowは、Notebook、Pipelines、Feature Store、Servingなど、さまざまな機能で構成されています。
Google AI Platform Pipelinesは、その中のKubeflow Pipelinesを「サービス」として提供するものです。
必要なのがPipelinesだけで、ほかの機能は不要というケースであれば、AI Platform Pipelinesを選びましょう。
本記事では、AI Platform PipelinesとKubeflow Pipelinesを区別せずに使います。ここで紹介するアプローチは、特別な変更を加えなくてもKubeflowにそのまま適用できます。
AI Platform Pipelinesを使えば、Kubeflowのセットアップにかかる時間を大幅に短縮できます。
ノートブックとコードをすぐに見たい方へ
機械学習も他のコードと同じ基準に従うべきだと考えています。たとえ便利でも、本番運用のパイプラインがノートブック上に存在することがあってはなりません。
Kubeflow Pipelineを作成する方法
Kubeflow向けのパイプラインは、いくつかの方法で構築できます。本記事では最初のアプローチを中心に取り上げますが、それ以外の方法もあわせて紹介しておきます。
- TensorFlow Extendedを使う方法 すでにTensorFlowを使っているなら、これが最適です。TFXパイプラインがKubeflowの解釈できる形式にコンパイルされます。
- Kubeflow Componentsを使う方法
- TensorFlow ExtendedコンポーネントをKubeflow Componentsとして実装する方法
最後の方法は、TFXとほかのコンポーネントや機能を組み合わせて使いたい場合に有効です。以前は非公式にサポートされていましたが、TFX SDKに置き換える形で2020年5月に非推奨となりました。それでもこのアーキテクチャに関心がある方は、https://github.com/kubeflow/pipelines/issues/3853のディスカッションをご覧ください。
AI Platform Pipelinesのインストール
セットアップは、ボタン2クリックとインフラ起動までの数分の待ち時間だけで完了します。
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
Kubeflowパイプラインの実行に必要なKubernetesクラスターのセットアップは、Google側で行ってくれます。既存のKubernetesクラスター上にKubeflow Pipelinesをインストールすることも可能です。
Kubernetesの管理・運用に慣れているなら、既存のKubernetesクラスターにKubeflow Pipelinesまたはフル版のKubeflowをインストールしましょう。
Kubeflow Pipelines SDK
Kubeflow用のパイプラインを作成するには、Kubeflow Pipelines SDKがインストールされていることを確認してください。
pip install kfp
CLIでパイプラインを作成中に次のエラーが出た場合は、SDKが正しくインストールされているかを確認しましょう。
error Kubeflow not found
パイプラインの作成
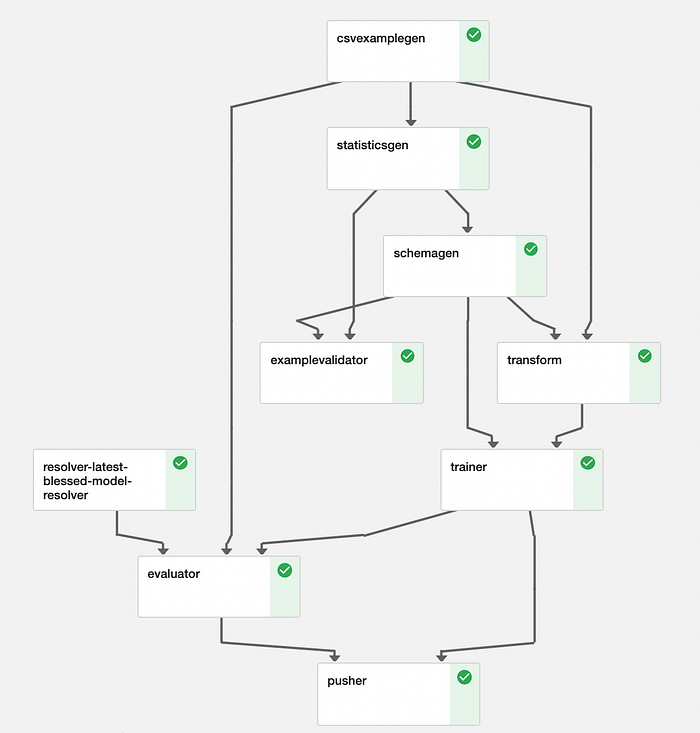
ここまでにTensorFlow Extendedのさまざまなコンポーネントを使ってきました。パイプラインとは、それらのコンポーネントを組み合わせたものに過ぎません。
#pipeline.py (simplified full code in repository)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
前回の記事では、TensorFlow Extendedがサポートしているオーケストレーターを紹介しました。それぞれのオーケストレーターでは、パイプラインを実行するためにオーケストレーター固有の設定と実装が必要になります。
パイプラインのうち、オーケストレーターによって異なるのはランナー部分のみです。本記事ではKubeflowに焦点を当てていますが、それ以外の部分はほかのオーケストレーターでもほぼ共通です。
以降では、ランナーを分解しながら必要な実装を順に見ていきます。
まず、KubeflowMetadataConfig protoのインスタンスを取得します。これはKubeflow metadataへの接続情報をまとめたものに過ぎません。Metadataは、機械学習パイプラインのメタデータを追跡・管理するためのKubeflowコンポーネントです。前回の記事を振り返っておくと、Kubeflow metadataと同様の機能を提供するML Metadata (MLMD) を取り上げていました。
#kubeflow_runner.py (simplified full code in repository)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Kubeflowパイプラインは、単一または複数のコンテナとして実行されます。TFXパイプラインをKubeflow上で動かすには、Dockerコンテナイメージを作成する必要があります。パイプラインにはpandasや独自の変換コードといった固有の依存関係が含まれることがあり、それらをDockerにまとめておくことでKubeflow上で実行できるようになります。詳細は本記事後半のCI/CDセクションで取り上げます。
もう一歩踏み込んで:
さらに掘り下げたい方は、TFXのKubeflowオーケストレーション実装を覗いてみることをおすすめします。使っているツールの仕組みを知っておくことは常に有益です。実装を見ると、TFXがKubeflow SDKとそのドメイン固有言語を使ってコンポーネントを定義していることがわかります。Kubeflow SDKドキュメントでは、TFXで使われているプロセスが解説されています。
シンプルにまとめると、パイプラインはDockerコンテナイメージに収める必要がある、と覚えておけば十分です。
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
今回のケースでは、ランナーには設定としてKubeflowDagRunnerConfigが必要です。これはメタデータ設定とDockerコンテナイメージで構成されます。
#kubeflow_runner.py (simplified, full code in repository)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
最後に、設定とパイプラインを使ってKubeflowDagRunnerを定義し、すべてを組み合わせます。create_pipeline関数はTFXコンポーネントをラップし、TFXパイプラインオブジェクトを返します。
#kubeflow_runner.py (simplified, full code in repository)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
ランナーAPIドキュメント:
TFXには、パイプラインを作成するためのCLIコマンドが用意されています。ランナーによっては追加のパラメーターが必要になりますが、今回はKubeflowにデプロイするので、必要最小限の設定は次のとおりです。
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
もう一歩踏み込んで:
このコマンドはパラメーターをkpf.clientに渡します。CLIはKubeflowでのパイプライン作成プロセスをシンプルにする便利なラッパーです。CLIの実装はとても興味深く、プロセスの仕組みを理解するうえで参考になります。
数分後にはパイプラインが作成され、利用可能になります。MLチームはノートブックからCLIを呼び出して、新しいバージョンのパイプラインを手動でデプロイすることもできます。
とはいえ、改善の余地は常にあります。次のセクションでは、継続的デリバリーの仕組みを実装していきます。
継続的デリバリー
パイプラインはGoogle Cloud Platform上で動作するため、サーバーレスCI/CDプラットフォームであるGoogle Cloud Buildを使います。
前のセクションで、パイプラインのデプロイに必要なものは整理できています。
- パイプラインと依存関係をまとめたDockerコンテナイメージ。このイメージはGoogle Container Registryにプッシュします。
- パイプラインを作成するためのCLI。
Cloud Buildでは、これらの手順をyamlファイルで定義します。
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
ビルドプロセスではTFX CLIのcreateコマンドを呼び出す必要があります。現時点ではそのまま使える公式のDockerイメージはありませんが、数行のコードで自前のイメージをビルドできます。
#dockerfile (simplified, full code in repository)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
継続的デプロイのプロセスを仕上げるため、GitHubリポジトリをCloud Buildに接続します。あとは継続的デプロイを起動するためのトリガーを定義するだけです。たとえば、mainブランチへのプッシュごとにパイプラインがビルドされ、Kubeflowにデプロイされる、といった形にできます。
Google Cloud BuildはKubernetesクラスターへのアクセスが必要です。アクセスを必ず有効にしておきましょう。https://cloud.google.com/build/docs/deploying-builds/deploy-gke
ベストプラクティスと制限事項
データの墓場 🧟
パイプラインを実行するたびに、一定量のメタデータが生成されます。このメタデータ(アーティファクトとも呼ばれます)はGoogle Cloud Storageに保存されます。可観測性を確保するため、各実行のデータも保存されます。学習頻度が高い場合や大規模データセットを扱う場合は、バケットにライフサイクルルールを追加することを検討してください。ユースケースに応じて、X日経過したデータを削除するといった運用も可能です。https://cloud.google.com/storage/docs/managing-lifecycles
TFX CLIの認証 🔑
TFX CLIは認証をサポートしていません。コマンドを実行する環境からKubeflow / AI Platform Pipelinesにアクセスできる状態にしておく必要があります。
TFX APIの紛らわしさ 🤔
TFX APIには、2種類のKubeflowランナーが用意されています。
エンジニアの直感としては新しそうなKubeflowV2DagRunnerを使いたくなりますが、Googleが推奨しているのはKubeflowDagRunnerの方です(2021年3月時点でV2はまだ開発中。https://github.com/tensorflow/tfx/issues/3361)。
自動化のための手動作業 🧂
パイプラインの初回バージョンは、TFX CLIのcreateコマンドで作成する必要があります。以降の変更にはupdateコマンドを使います。CI/CDプロセスを実装する際にはこの点を覚えておきましょう。TFXチームは現在この問題への対応を進めています。https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
メモリ 🍫
機械学習ソリューションによっては、リソースが不足することがあります。本記事のSentiment Analysisのユースケースでは、変換処理を実行するためにAI Platform Pipelinesのデフォルトメモリを増やす必要があります(BERTを使うとそれなりのコストがかかります :)。https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster
GPU
モデルによっては学習にGPUが必要になります。GPUを使う方法は複数あります。AI Platform Trainerコンポーネントを使う方法と、クラスターにGPUを追加する方法です。
これまでに進んだ機能追加と修正 💪
TensorFlowおよびKubeflowチームの対応の速さに触れておきたいと思います。本記事の執筆から公開までの短い間に、ほぼすべての課題が対応中になりました。
- https://github.com/tensorflow/tfx/issues/3369 🟢 解決済み
- https://github.com/tensorflow/tfx/issues/3361 🟡 対応中
- https://github.com/kubeflow/pipelines/issues/5302 🟡 対応中
- https://github.com/kubeflow/pipelines/issues/5303 🟡 対応中
- https://github.com/tensorflow/tfx/issues/3386 🟡 対応中
TFX Googleグループでのディスカッションに基づくもの:
次は何を取り上げる?
機械学習に関する今後のトピックにもどうぞご期待ください。
お読みいただきありがとうございました
フィードバックや質問は大歓迎です。Twitter @HeyerSascha または LinkedIn からお気軽にご連絡ください。私の YouTube チャンネルへのご登録もぜひ ❤️ 。