TensorFlow Extended ist eine End-to-End-Plattform für produktive ML-Pipelines.

Damit eine ML-Pipeline läuft, brauchen Sie einen Orchestrator, der sie ausführt. In diesem Artikel setzen wir dafür Kubeflow ein.
Am Ende werden Sie sehen, wie gut Kubeflow und TensorFlow Extended zusammenpassen ❤️.
Wir zeigen, wie sich eine TensorFlow Extended Pipeline aufbauen lässt, deployen sie anschließend mit den Bordmitteln von TensorFlow Extended in Kubeflow Pipelines und gehen am Ende im Detail darauf ein, wie sich das Ganze per CI/CD umsetzen lässt.
Zurück in die Vergangenheit
In einem früheren Artikel, TensorFlow Extended 101, haben wir alles Wissenswerte für den Aufbau einer TFX-Pipeline behandelt. Mit diesem Artikel gehen wir einen Schritt weiter.
Was ist AI Platform Pipelines – und warum nutzen wir es?
Wer über AI Platform Pipelines spricht, spricht zwangsläufig auch über Kubeflow.
Kubeflow umfasst mehrere Bestandteile wie Notebook, Pipelines, Feature Store, Serving und vieles mehr.
Google AI Platform Pipelines greift sich eine dieser Komponenten heraus – Kubeflow Pipelines – und stellt sie als "Service" bereit.
Wählen Sie AI Platform Pipelines, wenn Sie ausschließlich Pipelines benötigen und sonst keine Funktionen.
Im Folgenden verwenden wir AI Platform Pipelines und Kubeflow Pipelines synonym. Der gezeigte Ansatz lässt sich ohne weitere Anpassungen auch direkt auf Kubeflow übertragen.
Mit AI Platform Pipelines sparen wir uns einiges an Aufwand beim Aufsetzen von Kubeflow.
Direkt zum Notebook und Code?
Meiner Überzeugung nach muss Machine Learning denselben Standards genügen wie jeder andere Code. So bequem es auch sein mag – eine produktive Pipeline gehört nicht in ein Notebook.
Wege, eine Kubeflow-Pipeline zu erstellen
Pipelines für Kubeflow lassen sich auf unterschiedliche Arten bauen. Wir konzentrieren uns auf den ersten Ansatz, möchten aber auch die übrigen Wege kurz aufzeigen.
- Mit TensorFlow Extended: sinnvoll, wenn Sie ohnehin TensorFlow einsetzen. Die TFX-Pipeline wird in ein Format kompiliert, das Kubeflow versteht.
- Mit Kubeflow Components
- Mit TensorFlow-Extended-Komponenten, die als Kubeflow-Komponenten implementiert sind.
Letzteres ist nützlich, wenn Sie TFX mit anderen Komponenten und Funktionen kombinieren möchten. Früher gab es dafür inoffiziellen Support; im Mai 2020 wurde dieser zugunsten des TFX SDK abgekündigt. Falls Sie sich dennoch für diese Architektur interessieren, verfolgen Sie die Diskussion unter https://github.com/kubeflow/pipelines/issues/3853.
Installation von AI Platform Pipelines
Das Setup ist denkbar simpel: zwei Klicks und ein paar Minuten Wartezeit, bis die Infrastruktur bereitsteht.
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
Google kümmert sich um den Kubernetes-Cluster, der für den Betrieb der Kubeflow-Pipelines nötig ist. Sie können Kubeflow Pipelines aber auch auf einem bestehenden Kubernetes-Cluster installieren.
Wenn Sie mit dem Betrieb von Kubernetes vertraut sind, nutzen Sie Ihren bestehenden Cluster und installieren dort Kubeflow Pipelines oder das vollständige Kubeflow.
Kubeflow Pipelines SDK
Um eine Pipeline für Kubeflow zu bauen, muss das Kubeflow Pipelines SDK installiert sein.
pip install kfp
Erhalten Sie beim Erstellen der Pipeline über die CLI folgenden Fehler, prüfen Sie, ob das SDK korrekt installiert ist.
error Kubeflow not found
Pipeline erstellen
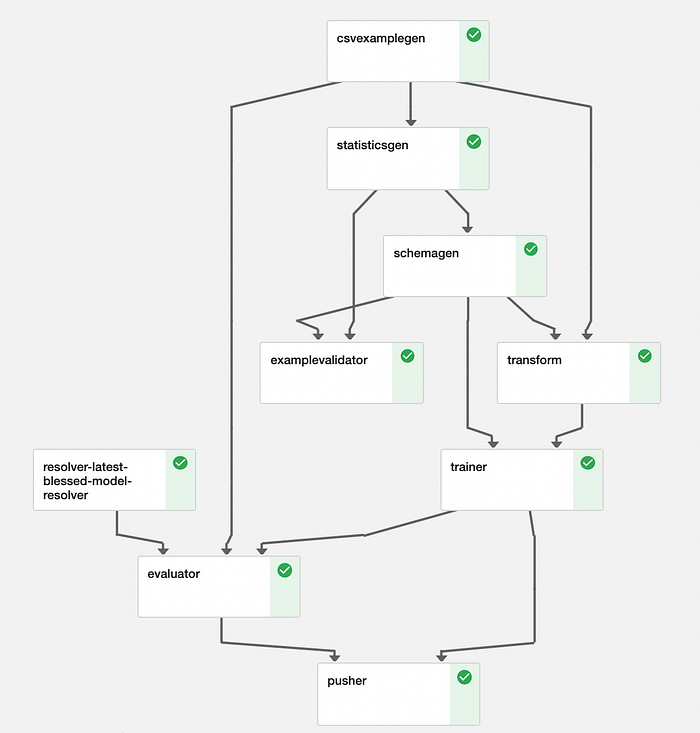
Wir haben verschiedene Komponenten von TensorFlow Extended verwendet. Eine Pipeline fügt diese Komponenten lediglich zusammen.
#pipeline.py (simplified full code in repository)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
Im vorherigen Artikel haben wir die von TensorFlow Extended unterstützten Orchestratoren erwähnt. Jeder davon erfordert eigene Konfigurationen und eine eigene Implementierung, um die Pipeline tatsächlich auszuführen.
Der einzige Teil unserer Pipeline, der sich zwischen den Orchestratoren unterscheidet, ist der Runner. Auch wenn dieser Artikel auf Kubeflow fokussiert ist, sind die meisten Bestandteile mit den anderen Orchestratoren identisch.
Im Folgenden zerlegen wir den Runner und gehen die nötige Implementierung Schritt für Schritt durch.
Zunächst holen wir uns eine Instanz des KubeflowMetadataConfig proto. Dabei handelt es sich lediglich um ein Bündel an Informationen, wie eine Verbindung zu den Kubeflow-Metadaten hergestellt wird. Metadata ist eine Kubeflow-Komponente zum Tracken und Verwalten der Metadaten von Machine-Learning-Pipelines. Zur Erinnerung an den vorherigen Artikel: Dort haben wir ML Metadata (MLMD) behandelt, das eine ähnliche Funktionalität wie Kubeflow Metadata bietet.
#kubeflow_runner.py (simplified full code in repository)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Kubeflow-Pipelines werden als ein oder mehrere Container ausgeführt. Damit unsere TFX-Pipeline in Kubeflow läuft, müssen wir ein Docker-Container-Image bauen. Unsere Pipeline kann spezifische Abhängigkeiten enthalten, etwa pandas oder unseren Transformationscode. Indem wir diese Abhängigkeiten in einen Docker-Container packen, lässt sich die Pipeline in Kubeflow ausführen. Im CI/CD-Abschnitt weiter unten gehen wir darauf im Detail ein.
Deep Dive:
Wenn Sie tiefer einsteigen möchten, empfehle ich einen Blick in die TFX-Kubeflow-Orchestration-Implementierung. Es schadet nie zu wissen, wie die Tools, die wir einsetzen, intern funktionieren. Aus dem Code wird ersichtlich, dass TFX das Kubeflow SDK und dessen Domain-Specific Language nutzt, um die Komponente zu definieren. Die Kubeflow-SDK-Dokumentation beschreibt den in TFX verwendeten Prozess.
Vereinfacht gesagt reicht es, sich zu merken: Unsere Pipeline muss in einem Docker-Container-Image vorliegen.
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
In unserem Fall benötigt der Runner eine Konfiguration – die KubeflowDagRunnerConfig –, die aus unserer Metadata-Konfiguration und unserem Docker-Container-Image besteht.
#kubeflow_runner.py (simplified, full code in repository)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
Zum Schluss fügen wir alles zusammen, indem wir den KubeflowDagRunner mit der Konfiguration und unserer Pipeline definieren. Die Funktion create_pipeline kapselt unsere TFX-Komponenten und gibt ein TFX-Pipeline-Objekt zurück.
#kubeflow_runner.py (simplified, full code in repository)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
API-Dokumentation der Runner:
TFX bringt einen CLI-Befehl zum Erstellen einer Pipeline mit. Verschiedene Runner können zusätzliche Parameter erfordern. In unserem Fall deployen wir auf Kubeflow; das hier ist die Mindestkonfiguration.
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
Deep Dive:
Der Befehl reicht die Parameter an den kpf.client weiter. Die CLI ist ein praktischer Wrapper, der das Anlegen von Pipelines in Kubeflow vereinfacht. Werfen Sie einen Blick in die CLI-Implementierung – sehr aufschlussreich, um den Ablauf zu verstehen.
Nach wenigen Minuten ist die Pipeline angelegt und einsatzbereit. Ihr ML-Team kann die CLI in Notebooks nutzen, um eine neue Version manuell zu deployen.
Luft nach oben gibt es immer – im nächsten Abschnitt setzen wir genau dort an und implementieren eine Continuous-Delivery-Lösung.
Continuous Delivery
Unsere Pipeline läuft auf der Google Cloud Platform; deshalb setzen wir Google Cloud Build ein, eine serverlose CI/CD-Plattform.
Aus dem vorherigen Abschnitt wissen wir, was wir für das Deployment brauchen.
- Ein Docker-Container-Image mit unserer Pipeline und ihren Abhängigkeiten. Das Image wird in die Google Container Registry gepusht.
- Und die CLI, um die Pipeline anzulegen.
Mit Cloud Build definieren wir diese Schritte in einer YAML-Datei.
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
Unser Build-Prozess ruft den TFX-CLI-Befehl create auf. Aktuell gibt es dafür kein öffentliches, fertiges Docker-Image. Mit ein paar Zeilen Code bauen wir uns aber selbst eines.
#dockerfile (simplified, full code in repository)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
Zum Abschluss unseres Continuous-Deployment-Prozesses verbinden wir unser GitHub-Repository mit Cloud Build. Wir definieren Trigger, die den Continuous-Deployment-Prozess starten. So wird die Pipeline beispielsweise bei jedem Push in den Main-Branch gebaut und auf Kubeflow ausgerollt.
Google Cloud Build benötigt Zugriff auf unseren Kubernetes-Cluster – stellen Sie sicher, dass dieser Zugriff freigeschaltet ist. https://cloud.google.com/build/docs/deploying-builds/deploy-gke
Best Practices und Limitierungen
Datenfriedhof 🧟
Jeder Pipeline-Lauf erzeugt eine gewisse Menge an Metadaten. Unsere Pipelines speichern diese Metadaten – auch Artefakte genannt – in Google Cloud Storage. Aus Gründen der Observability werden zudem die Daten jedes Laufs abgelegt. Wer in hoher Frequenz oder auf großen Datensätzen trainiert, sollte eine Lifecycle-Regel für den Bucket einrichten. Je nach Anwendungsfall lassen sich so etwa Daten löschen, die älter als X Tage sind. https://cloud.google.com/storage/docs/managing-lifecycles
TFX-CLI-Authentifizierung 🔑
Die TFX CLI unterstützt keine Authentifizierung. Die Umgebung, die den Befehl ausführt, benötigt direkten Zugriff auf Kubeflow bzw. AI Platform Pipelines, um die Pipeline anzulegen.
Verwirrung in der TFX-API 🤔
Die TFX-API stellt zwei verschiedene Kubeflow-Runner bereit:
Es widerspricht meinem Engineer-Instinkt, den KubeflowV2DagRunner nicht zu verwenden, denn er wirkt neuer – Google empfiehlt jedoch den KubeflowDagRunner. (Stand März 2021 ist V2 noch in Entwicklung: https://github.com/tensorflow/tfx/issues/3361.)
Erst manuell, dann automatisch 🧂
Die allererste Version unserer Pipeline muss mit dem TFX-CLI-Befehl create angelegt werden. Spätere Änderungen werden mit dem Befehl update umgesetzt. Behalten Sie das im Hinterkopf, wenn Sie einen CI/CD-Prozess aufsetzen. Das TFX-Team arbeitet an einer Lösung: https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
Speicher 🍫
Je nach Machine-Learning-Lösung kann es bei den Ressourcen eng werden. Für unseren Sentiment-Analysis-Anwendungsfall müssen wir den Standardspeicher von AI Platform Pipelines erhöhen, um die Transformationen ausführen zu können (BERT hat eben seinen Preis :). https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster.
GPUs
Je nach Modell benötigen Sie GPUs für das Training. Dafür gibt es mehrere Wege: Sie können die AI Platform Trainer-Komponente verwenden oder Ihrem Cluster eine GPU hinzufügen.
Features und Fixes auf der bisherigen Reise 💪
Ich möchte zeigen, wie schnell die Teams bei TensorFlow und Kubeflow auf Issues reagieren. Vom Schreiben dieses Artikels bis zur Veröffentlichung sind nahezu alle Issues in Bearbeitung.
- https://github.com/tensorflow/tfx/issues/3369 🟢 gelöst
- https://github.com/tensorflow/tfx/issues/3361 🟡 in Bearbeitung
- https://github.com/kubeflow/pipelines/issues/5302 🟡 in Bearbeitung
- https://github.com/kubeflow/pipelines/issues/5303 🟡 in Bearbeitung
- https://github.com/tensorflow/tfx/issues/3386 🟡 in Bearbeitung
Auf Basis einer Diskussion in der TFX Google Group:
- https://github.com/tensorflow/tfx/issues/3417 🟡 in Bearbeitung
Wie geht es weiter?
Bleiben Sie dran – weitere Themen rund um Machine Learning folgen.
Danke fürs Lesen
Über Ihr Feedback und Ihre Fragen freue ich mich sehr. Sie finden mich auf Twitter unter @HeyerSascha oder vernetzen sich mit mir über LinkedIn. Noch besser: Abonnieren Sie meinen YouTube-Kanal ❤️.