TensorFlow Extended est une plateforme de bout en bout pour mettre en œuvre des pipelines ML en production.

Pour qu'un pipeline ML fonctionne, il faut un orchestrateur capable de l'exécuter. Dans cet article, nous nous appuierons sur Kubeflow.
À la fin de cette lecture, vous comprendrez à quel point Kubeflow et TensorFlow Extended sont faits l'un pour l'autre ❤️.
Au programme : la création d'un pipeline TensorFlow Extended, son déploiement sur Kubeflow Pipelines via les fonctionnalités intégrées de TensorFlow Extended, puis le détail d'une mise en œuvre en CI/CD.
Petit retour en arrière
Dans un précédent article, TensorFlow Extended 101, nous avons passé en revue tout ce qu'il faut savoir pour créer son pipeline TFX. Allons un cran plus loin.
AI Platform Pipelines : qu'est-ce que c'est et pourquoi l'utiliser ?
Dès que l'on parle d'AI Platform Pipelines, on parle aussi de Kubeflow.
Kubeflow regroupe plusieurs briques : Notebook, Pipelines, Feature Store, Serving, et bien d'autres.
Google AI Platform Pipelines reprend l'un de ces composants, Kubeflow Pipelines, et le propose sous forme de service géré.
Optez pour AI Platform Pipelines si vous n'avez besoin que de Pipelines et d'aucune autre fonctionnalité.
Dans la suite, nous employons indifféremment AI Platform Pipelines et Kubeflow Pipelines. L'approche présentée s'applique aussi à Kubeflow sans aucune adaptation.
Recourir à AI Platform Pipelines fait gagner un temps précieux sur la mise en place de Kubeflow.
Envie d'aller directement au notebook et au code ?
Pour moi, le machine learning doit respecter les mêmes standards que n'importe quel autre code. Aussi pratique soit-il, aucun pipeline de production n'a sa place dans un notebook.
Différentes manières de créer un pipeline Kubeflow
Il existe plusieurs façons de construire un pipeline pour Kubeflow. Nous nous concentrons sur la première, mais voici les autres options à connaître.
- Avec TensorFlow Extended. À privilégier si vous utilisez déjà TensorFlow. Le pipeline TFX est compilé dans un format que Kubeflow sait interpréter.
- Avec Kubeflow Components
- Avec les composants TensorFlow Extended implémentés sous forme de Kubeflow Components.
Cette dernière option est utile si vous souhaitez combiner TFX avec d'autres composants et fonctionnalités. Ce cas d'usage a longtemps bénéficié d'un support non officiel, abandonné en mai 2020 au profit du SDK TFX. Si ce type d'architecture vous intéresse malgré tout, suivez la discussion ici : https://github.com/kubeflow/pipelines/issues/3853.
Installation d'AI Platform Pipelines
L'installation se résume à deux clics et quelques minutes d'attente, le temps que l'infrastructure soit provisionnée.
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
Google se charge de provisionner le cluster Kubernetes nécessaire à l'exécution des pipelines Kubeflow. Vous pouvez aussi installer Kubeflow Pipelines sur un cluster Kubernetes existant.
Si vous maîtrisez déjà Kubernetes, partez de votre cluster existant et installez-y Kubeflow Pipelines, ou Kubeflow dans son intégralité.
Le SDK Kubeflow Pipelines
Pour créer un pipeline destiné à Kubeflow, il faut s'assurer que le SDK Kubeflow Pipelines est bien installé.
pip install kfp
Si l'erreur suivante apparaît au moment de créer le pipeline via la CLI, vérifiez l'installation du SDK.
error Kubeflow not found
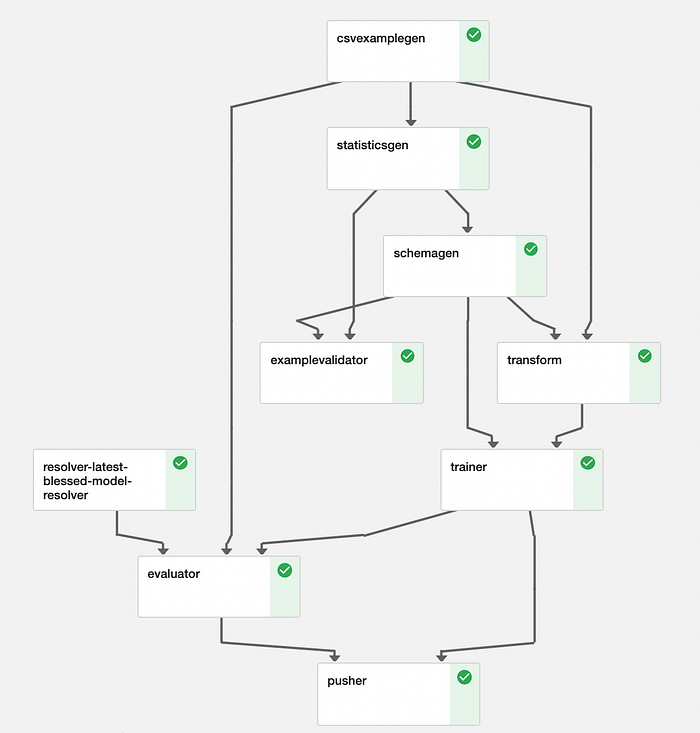
Créer le pipeline
Nous avons utilisé plusieurs composants de TensorFlow Extended. Un pipeline, c'est simplement l'assemblage de ces composants.
#pipeline.py (simplified full code in repository)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
Dans notre précédent article, nous avons évoqué les orchestrateurs pris en charge par TensorFlow Extended. Chacun requiert une configuration et une implémentation spécifiques pour exécuter le pipeline.
La seule partie qui change d'un orchestrateur à l'autre, c'est le runner. Cet article cible Kubeflow, mais l'essentiel reste identique pour les autres orchestrateurs.
Décomposons maintenant le runner et passons en revue son implémentation.
D'abord, on récupère une instance du proto KubeflowMetadataConfig. Rien de plus qu'un ensemble d'informations indiquant comment se connecter à Kubeflow metadata. Metadata est un composant de Kubeflow dédié au suivi et à la gestion des métadonnées des pipelines de machine learning. Pour rappel, dans l'article précédent, nous avons abordé ML Metadata (MLMD), qui propose des fonctionnalités similaires à Kubeflow metadata.
#kubeflow_runner.py (simplified full code in repository)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Les pipelines Kubeflow s'exécutent sous forme de conteneurs, parfois multiples. Pour faire tourner notre pipeline TFX dans Kubeflow, il faut produire une image de conteneur Docker. Notre pipeline peut embarquer des dépendances spécifiques comme pandas ou notre code de transformation. Les regrouper dans une image Docker garantit la bonne exécution sur Kubeflow. Nous y reviendrons en détail dans la section CI/CD.
Pour aller plus loin :
Si vous voulez creuser le sujet, jetez un œil à l'implémentation de l'orchestration TFX pour Kubeflow. Comprendre le fonctionnement interne des outils que l'on utilise est toujours utile. On y voit que TFX s'appuie sur le SDK Kubeflow et son langage spécifique au domaine pour définir les composants. La documentation du SDK Kubeflow décrit le processus mis en œuvre dans TFX.
Pour faire simple, retenez que notre pipeline doit être embarqué dans une image de conteneur Docker.
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
Dans notre cas, le runner attend une configuration, le KubeflowDagRunnerConfig, qui réunit notre configuration de métadonnées et notre image de conteneur Docker.
#kubeflow_runner.py (simplified, full code in repository)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
Pour finir, on assemble le tout en définissant notre KubeflowDagRunner à partir de la configuration et du pipeline. La fonction create_pipeline encapsule nos composants TFX et renvoie un objet pipeline TFX.
#kubeflow_runner.py (simplified, full code in repository)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
Documentation API des runners :
TFX fournit une commande CLI pour créer un pipeline. Selon le runner, certains paramètres supplémentaires peuvent être nécessaires. Pour un déploiement sur Kubeflow, voici la configuration minimale.
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
Pour aller plus loin :
La commande transmet ses paramètres à kpf.client. La CLI est un wrapper pratique qui simplifie la création de pipelines dans Kubeflow. L'implémentation de la CLI vaut le détour : c'est instructif et cela aide à bien comprendre le processus.
Quelques minutes plus tard, le pipeline est créé et prêt à l'emploi. Votre équipe ML peut s'appuyer sur la CLI dans des notebooks pour déployer manuellement une nouvelle version du pipeline.
Il y a toujours matière à amélioration : la section suivante propose une solution de livraison continue.
Livraison continue
Notre pipeline tourne sur Google Cloud Platform : nous utilisons donc Google Cloud Build, une plateforme CI/CD serverless.
D'après la section précédente, deux éléments sont nécessaires au déploiement.
- Une image de conteneur Docker contenant notre pipeline et ses dépendances. Elle est poussée vers Google Container Registry.
- La CLI pour créer le pipeline.
Avec Cloud Build, on décrit ces étapes dans un fichier YAML.
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
Notre processus de build doit invoquer la commande create de la CLI TFX. Aujourd'hui, aucune image Docker publique prête à l'emploi n'existe pour cela. Mais on peut créer la sienne en quelques lignes.
#dockerfile (simplified, full code in repository)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
Pour finaliser le déploiement continu, on connecte le dépôt GitHub à Cloud Build. On définit ensuite des déclencheurs pour lancer le processus. Par exemple, à chaque push sur la branche main, le pipeline est construit puis déployé sur Kubeflow.
Google Cloud Build doit pouvoir accéder à votre cluster Kubernetes : pensez à activer cet accès. https://cloud.google.com/build/docs/deploying-builds/deploy-gke
Bonnes pratiques et limites
Cimetière de données 🧟
Chaque exécution de pipeline produit son lot de métadonnées. Notre pipeline les stocke, sous le nom d'artefacts, sur Google Cloud Storage. Pour des raisons d'observabilité, les données de chaque exécution sont également conservées. Si vous entraînez à cadence élevée ou sur de gros jeux de données, pensez à ajouter une règle de cycle de vie sur votre bucket. Selon le cas d'usage, vous pourrez par exemple supprimer les données de plus de X jours. https://cloud.google.com/storage/docs/managing-lifecycles
Authentification de la CLI TFX 🔑
La CLI TFX ne gère pas l'authentification. L'environnement qui exécute la commande doit déjà avoir accès à Kubeflow / AI Platform Pipelines pour pouvoir créer le pipeline.
Confusion autour de l'API TFX 🤔
L'API TFX expose deux runners Kubeflow différents :
Mon instinct d'ingénieur me pousserait vers KubeflowV2DagRunner parce qu'il paraît plus récent, mais Google recommande KubeflowDagRunner. (À l'heure où nous écrivons, en mars 2021, la V2 est toujours en développement https://github.com/tensorflow/tfx/issues/3361.)
Manuel d'abord, automatique ensuite 🧂
La toute première version du pipeline doit être créée avec la commande create de la CLI TFX. Les modifications suivantes passent par la commande update. Gardez-le en tête au moment de mettre en place votre processus CI/CD. L'équipe TFX travaille à une solution : https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
Mémoire 🍫
Selon votre solution de machine learning, vous risquez de manquer de ressources. Pour notre cas d'analyse de sentiment, il a fallu augmenter la mémoire par défaut d'AI Platform Pipelines pour exécuter les transformations (utiliser BERT a un coût :). https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster.
GPU
Selon votre modèle, des GPU peuvent être nécessaires pour l'entraînement. Plusieurs options existent : utiliser le composant AI Platform Trainer ou ajouter un GPU à votre cluster.
Fonctionnalités et correctifs apportés en cours de route 💪
Je tiens à souligner la réactivité des équipes TensorFlow et Kubeflow face aux issues. Entre la rédaction de cet article et sa publication, presque toutes ont avancé.
- https://github.com/tensorflow/tfx/issues/3369 🟢 résolu
- https://github.com/tensorflow/tfx/issues/3361 🟡 en cours
- https://github.com/kubeflow/pipelines/issues/5302 🟡 en cours
- https://github.com/kubeflow/pipelines/issues/5303 🟡 en cours
- https://github.com/tensorflow/tfx/issues/3386 🟡 en cours
À la suite d'une discussion sur le Google group TFX :
Et ensuite ?
Restez à l'écoute pour de nouveaux sujets autour du machine learning.
Merci de votre lecture
Vos retours et questions sont les bienvenus. Retrouvez-moi sur Twitter @HeyerSascha ou échangeons sur LinkedIn . Mieux encore, abonnez-vous à ma chaîne YouTube ❤️ .