TensorFlow Extended es una plataforma end-to-end para implementar pipelines de ML en producción.

Para que tu pipeline de ML funcione, necesitas un orquestador que lo ejecute. En este artículo vamos a usar Kubeflow como orquestador.
Al terminar de leer, vas a ver lo bien que se complementan Kubeflow y TensorFlow Extended ❤️.
Vamos a cubrir cómo se crea un pipeline de TensorFlow Extended, cómo desplegarlo en Kubeflow Pipelines aprovechando la funcionalidad integrada de TensorFlow Extended y, por último, cómo hacerlo siguiendo un esquema de CI/CD.
Volvamos al pasado
En un artículo anterior, TensorFlow Extended 101, cubrimos todo lo que necesitas saber para crear tu pipeline de TFX. Demos un paso más con este artículo.
¿Qué es AI Platform Pipelines y por qué lo usamos?
Cuando hablamos de AI Platform Pipelines, también hablamos de Kubeflow.
Kubeflow está compuesto por varias funcionalidades como Notebook, Pipelines, Feature Store, Serving y muchas más.
Google AI Platform Pipelines toma uno de esos componentes, Kubeflow Pipelines, y lo ofrece como un "servicio".
Elige AI Platform Pipelines si solo necesitas Pipelines y ninguna otra funcionalidad.
De aquí en adelante usaremos AI Platform Pipelines y Kubeflow Pipelines de forma intercambiable. El enfoque que aplicamos también sirve para Kubeflow sin necesidad de adaptaciones adicionales.
Usar AI Platform Pipelines nos ahorra bastante tiempo en la configuración de Kubeflow.
¿Quieres ir directo al notebook y al código?
Creo que el machine learning debe seguir los mismos estándares que cualquier otro código. Por más cómodo que resulte, ningún pipeline de producción debería vivir dentro de un notebook.
Formas de crear un Kubeflow Pipeline
Hay muchas maneras de construir pipelines para Kubeflow. Nos vamos a centrar en la primera, pero quiero mencionar las demás opciones.
- Con TensorFlow Extended: elige esta vía si ya estás usando TensorFlow. El pipeline de TFX se compila a un formato que Kubeflow entiende.
- Con Kubeflow Components
- Con componentes de TensorFlow Extended implementados como Kubeflow Components.
Esto resulta útil si quieres combinar TFX con otros componentes y funcionalidades. Antes existía soporte no oficial para ese caso de uso, pero quedó obsoleto en mayo de 2020 a favor del SDK de TFX. De todos modos, si te interesa ese tipo de arquitectura, sigue la conversación en https://github.com/kubeflow/pipelines/issues/3853.
Instalación de AI Platform Pipelines
Configurarlo es tan simple como 2 clics y unos minutos de espera mientras se levanta la infraestructura.
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
Google se encarga de configurar el cluster de Kubernetes necesario para ejecutar los pipelines de Kubeflow. También puedes instalar Kubeflow Pipelines sobre un cluster de Kubernetes ya existente.
Si ya tienes experiencia gestionando Kubernetes, usa tu cluster existente e instala Kubeflow Pipelines o Kubeflow completo.
Kubeflow Pipelines SDK
Para crear un pipeline para Kubeflow, primero hay que asegurarse de tener instalado el Kubeflow Pipelines SDK.
pip install kfp
Si te aparece el siguiente error al crear el pipeline desde la CLI, revisa que el SDK esté correctamente instalado.
error Kubeflow not found
Crear el pipeline
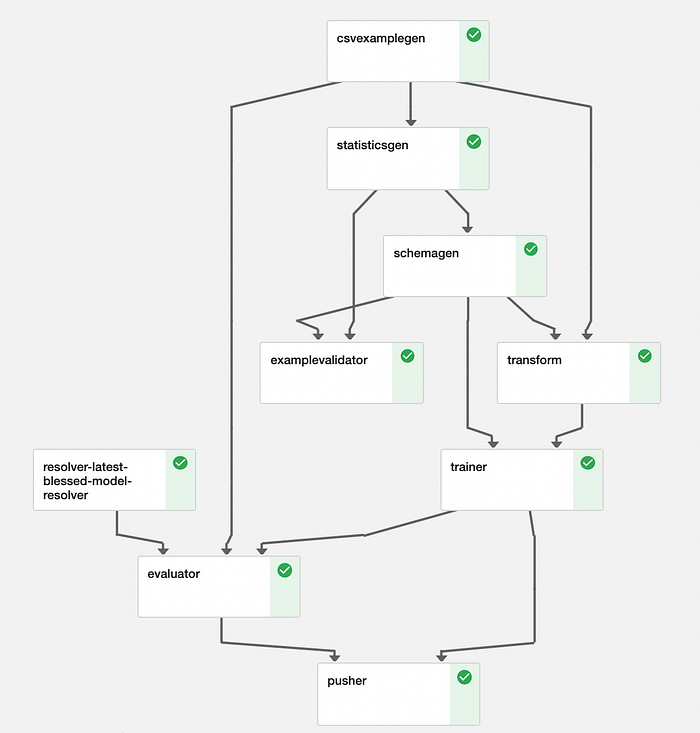
Ya usamos varios componentes de TensorFlow Extended. Un pipeline simplemente los une.
#pipeline.py (código completo simplificado en el repositorio)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
En el artículo anterior mencionamos los posibles orquestadores compatibles con TensorFlow Extended. Cada uno requiere configuraciones e implementaciones específicas para ejecutar el pipeline.
Lo único que cambia entre esos orquestadores es el runner. Aunque este artículo se enfoca en Kubeflow, la mayor parte aplica igual al resto.
A continuación desglosamos el runner y repasamos lo que hay que implementar.
Primero obtenemos una instancia de KubeflowMetadataConfig proto. No es más que un conjunto de datos sobre cómo conectarse a Kubeflow metadata. Metadata es un componente de Kubeflow que sirve para rastrear y gestionar los metadatos de los pipelines de machine learning. Recapitulando el artículo anterior, también vimos ML Metadata (MLMD), que ofrece una funcionalidad similar a Kubeflow metadata.
#kubeflow_runner.py (código completo simplificado en el repositorio)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Los pipelines de Kubeflow se ejecutan como uno o varios contenedores. Para correr nuestro pipeline de TFX en Kubeflow hay que crear una imagen de contenedor Docker. El pipeline puede tener dependencias específicas, como pandas o nuestro propio código de transformación. Empaquetar esas dependencias en Docker nos permite ejecutarlo en Kubeflow. Lo veremos en detalle más adelante, en la sección de CI/CD.
Profundizando:
Si quieres ir más a fondo, te recomiendo revisar la implementación de la orquestación TFX-Kubeflow. Siempre conviene saber cómo funcionan las herramientas que usamos. En la implementación se ve que TFX usa el SDK de Kubeflow y su lenguaje específico de dominio para definir el componente. La documentación del SDK de Kubeflow describe el proceso que utiliza TFX.
Para no complicarlo, basta con recordar que el pipeline tiene que ir dentro de una imagen de contenedor Docker.
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
En nuestro caso, el runner necesita una configuración, el KubeflowDagRunnerConfig, formada por la metadata config y la imagen de contenedor Docker.
#kubeflow_runner.py (simplificado, código completo en el repositorio)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
Por último, juntamos todo definiendo el KubeflowDagRunner con la configuración y nuestro pipeline. La función create_pipeline encapsula los componentes de TFX y devuelve un objeto pipeline de TFX.
#kubeflow_runner.py (simplificado, código completo en el repositorio)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
Documentación de la API del Runner:
TFX ofrece un comando de CLI para crear un pipeline. Cada runner puede pedir parámetros adicionales. En nuestro caso desplegamos en Kubeflow, y esta es la configuración mínima necesaria.
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
Profundizando:
El comando pasa los parámetros al kpf.client. La CLI es un wrapper práctico que simplifica el proceso de crear pipelines en Kubeflow. Échale un vistazo a la implementación de la CLI; es bastante interesante y te ayuda a entender cómo funciona el proceso.
En unos minutos, el pipeline queda creado y listo para usarse. Tu equipo de ML puede aprovechar la CLI desde notebooks para desplegar manualmente una nueva versión.
Siempre hay margen de mejora, y eso lo cubrimos en la siguiente sección con una solución de entrega continua.
Entrega continua
Nuestro pipeline corre en Google Cloud Platform, así que usamos Google Cloud Build, una plataforma de CI/CD serverless.
Por la sección anterior ya sabemos qué necesitamos para desplegarlo.
- Una imagen de contenedor Docker con el pipeline y sus dependencias. La imagen se publica en Google Container Registry.
- Y la CLI para crear el pipeline.
Con Cloud Build definimos esos pasos en un archivo yaml.
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
El proceso de build requiere invocar el comando create de la CLI de TFX. Por ahora no existe una imagen Docker pública lista para usar, pero podemos armar la nuestra con muy pocas líneas de código.
#dockerfile (simplificado, código completo en el repositorio)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
Para cerrar el proceso de despliegue continuo, conectamos nuestro repositorio de Github con Cloud Build y definimos triggers que lo inicien. Por ejemplo, cada push a la rama main construye y despliega el pipeline en Kubeflow.
Google Cloud Build necesita acceso a tu cluster de Kubernetes, así que asegúrate de habilitarlo. https://cloud.google.com/build/docs/deploying-builds/deploy-gke
Buenas prácticas y limitaciones
Cementerio de datos 🧟
Cada ejecución del pipeline genera cierta cantidad de metadatos. Nuestros pipelines guardan esos metadatos, también llamados artefactos, en Google Cloud Storage. Por motivos de observabilidad, también se almacenan los datos de cada ejecución. Si entrenas con alta cadencia o sobre datasets grandes, conviene agregar una regla de ciclo de vida al bucket. Según el caso de uso, podrías borrar datos con más de X días de antigüedad. https://cloud.google.com/storage/docs/managing-lifecycles
Autenticación de la CLI de TFX 🔑
La CLI de TFX no soporta autenticación. El entorno donde corre el comando necesita acceso a Kubeflow / AI Platform Pipelines para crear el pipeline.
Confusión en la API de TFX 🤔
La API de TFX expone dos runners distintos para Kubeflow:
Va contra mi instinto de ingeniero no usar KubeflowV2DagRunner porque parece más nuevo, pero Google recomienda KubeflowDagRunner. (a marzo de 2021, V2 sigue en desarrollo https://github.com/tensorflow/tfx/issues/3361.
Hazlo manual para que sea automático 🧂
La primera versión del pipeline se debe crear con el comando create de la CLI de TFX. Los cambios posteriores se aplican con el comando update. Tenlo presente al implementar tu proceso de CI/CD. El equipo de TFX está trabajando en una solución https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
Memoria 🍫
Según tu solución de machine learning, podrías quedarte corto de recursos. Para nuestro caso de Análisis de Sentimiento hay que aumentar la memoria por defecto de AI Platform Pipelines para poder ejecutar las transformaciones (usar BERT tiene su precio :). https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster.
GPUs
Según el modelo, podrías necesitar GPUs para entrenar. Hay varias formas de usarlas: con el componente AI Platform Trainer o agregando una GPU al cluster.
Funcionalidades y arreglos del camino hasta ahora 💪
Quiero mostrar lo rápido que responden los equipos de TensorFlow y Kubeflow a los issues. Entre que escribí este artículo y se publicó, casi todos los issues ya están en marcha.
- https://github.com/tensorflow/tfx/issues/3369 🟢 resuelto
- https://github.com/tensorflow/tfx/issues/3361 🟡 en progreso
- https://github.com/kubeflow/pipelines/issues/5302 🟡 en progreso
- https://github.com/kubeflow/pipelines/issues/5303 🟡 en progreso
- https://github.com/tensorflow/tfx/issues/3386 🟡 en progreso
A partir de una discusión en el grupo de Google de TFX
- https://github.com/tensorflow/tfx/issues/3417 🟡 en progreso
¿Qué sigue?
Mantente atento a más temas sobre machine learning.
Gracias por leer
Tus comentarios y preguntas son siempre bienvenidos. Puedes encontrarme en Twitter @HeyerSascha o conectar conmigo por LinkedIn . Mejor aún, suscríbete a mi canal de YouTube ❤️ .