TensorFlow Extended è una piattaforma end-to-end per realizzare pipeline ML in produzione.

Per far funzionare una pipeline ML serve un orchestratore che la esegua. In questo articolo useremo Kubeflow proprio in questo ruolo.
Alla fine della lettura vedrà quanto Kubeflow e TensorFlow Extended siano fatti l'uno per l'altro ❤️.
Vedremo come creare una pipeline TensorFlow Extended, come distribuirla su Kubeflow Pipelines sfruttando le funzionalità native di TensorFlow Extended e, per finire, come gestire il tutto in ottica CI/CD.
Un salto nel passato
Nell'articolo precedente, TensorFlow Extended 101, abbiamo visto tutto il necessario per creare una pipeline TFX. Con questo articolo facciamo un passo avanti.
Cos'è AI Platform Pipelines e perché lo usiamo
Quando si parla di AI Platform Pipelines, si parla inevitabilmente anche di Kubeflow.
Kubeflow è composto da diverse funzionalità: Notebook, Pipelines, Feature Store, Serving e molto altro.
Google AI Platform Pipelines prende uno di questi componenti, Kubeflow Pipelines, e lo offre come "servizio".
Scelga AI Platform Pipelines se le servono solo le Pipelines e nessun'altra funzionalità.
Nel prosieguo useremo AI Platform Pipelines e Kubeflow Pipelines come sinonimi. L'approccio descritto è applicabile anche a Kubeflow senza ulteriori adattamenti.
Affidarsi ad AI Platform Pipelines fa risparmiare parecchio tempo nella configurazione di Kubeflow.
Vuole andare subito al notebook e al codice?
Sono convinto che il machine learning debba seguire gli stessi standard di qualsiasi altro codice. Per quanto comodo, nessuna pipeline di produzione dovrebbe vivere dentro un notebook.
Come creare una Kubeflow Pipeline
Le pipeline per Kubeflow si possono costruire in molti modi. Ci concentreremo sul primo approccio, ma vale la pena citare anche gli altri.
- Con TensorFlow Extended: la scelta naturale se sta già usando TensorFlow. La pipeline TFX viene compilata in un formato che Kubeflow è in grado di interpretare.
- Con Kubeflow Components.
- Con componenti TensorFlow Extended implementati come Kubeflow Components.
Quest'ultima strada è utile se vuole combinare TFX con altri componenti e funzionalità. In passato esisteva un supporto non ufficiale per questo caso d'uso, deprecato a maggio 2020 a favore dell'SDK TFX. Se le interessa questo tipo di architettura, può seguire la conversazione qui: https://github.com/kubeflow/pipelines/issues/3853.
Installazione di AI Platform Pipelines
Bastano due clic e qualche minuto di attesa per il provisioning dell'infrastruttura.
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
Google si occupa di configurare il cluster Kubernetes necessario a eseguire le pipeline di Kubeflow. In alternativa, può installare Kubeflow Pipelines su un cluster Kubernetes già esistente.
Se ha familiarità con Kubernetes, sfrutti il suo cluster esistente e installi Kubeflow Pipelines o Kubeflow nella sua versione completa.
Kubeflow Pipelines SDK
Per creare una pipeline per Kubeflow occorre verificare che il Kubeflow Pipelines SDK sia installato.
pip install kfp
Se durante la creazione della pipeline da CLI compare l'errore seguente, controlli che l'SDK sia installato correttamente.
error Kubeflow not found
Creare la pipeline
Abbiamo utilizzato vari componenti di TensorFlow Extended. Una pipeline non è altro che la composizione di questi componenti.
#pipeline.py (simplified full code in repository)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
Nell'articolo precedente abbiamo elencato i possibili orchestratori supportati da TensorFlow Extended. Ognuno richiede configurazioni e implementazioni specifiche per eseguire la pipeline.
L'unica parte della pipeline che cambia da un orchestratore all'altro è il runner. Anche se questo articolo è dedicato a Kubeflow, gran parte di quanto vedremo vale anche per gli altri orchestratori.
Di seguito analizziamo il runner pezzo per pezzo, esaminando l'implementazione necessaria.
Per prima cosa otteniamo un'istanza di KubeflowMetadataConfig proto. Si tratta semplicemente di un insieme di informazioni su come connettersi ai metadati di Kubeflow. Metadata è il componente di Kubeflow che traccia e gestisce i metadati delle pipeline di machine learning. Riprendendo l'articolo precedente, abbiamo già parlato di ML Metadata (MLMD), che offre funzionalità analoghe ai metadati di Kubeflow.
#kubeflow_runner.py (simplified full code in repository)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Le pipeline di Kubeflow vengono eseguite come container, singoli o multipli. Per eseguire la nostra pipeline TFX su Kubeflow dobbiamo quindi creare un'immagine Docker. La pipeline può portarsi dietro dipendenze specifiche come pandas o il nostro codice di trasformazione: inserirle in un container Docker ci consente di eseguirla su Kubeflow. Vedremo il dettaglio più avanti, nella sezione dedicata al CI/CD.
Approfondimento:
Se vuole andare più a fondo, le consiglio di dare un'occhiata all'implementazione dell'orchestrazione TFX su Kubeflow. Capire come funzionano gli strumenti che usiamo è sempre utile. Dall'implementazione si nota che TFX si appoggia all'SDK di Kubeflow e al suo domain-specific language per definire i componenti. La documentazione dell'SDK Kubeflow descrive il processo utilizzato in TFX.
Per semplicità basta ricordare che la pipeline deve essere contenuta in un'immagine Docker.
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
Nel nostro caso, il runner richiede una configurazione, KubeflowDagRunnerConfig, composta dalla configurazione dei metadati e dall'immagine Docker.
#kubeflow_runner.py (simplified, full code in repository)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
A questo punto mettiamo tutto insieme definendo il KubeflowDagRunner a partire dalla configurazione e dalla pipeline. La funzione create_pipeline incapsula i componenti TFX e restituisce un oggetto pipeline TFX.
#kubeflow_runner.py (simplified, full code in repository)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
Documentazione delle API dei runner:
TFX mette a disposizione un comando CLI per creare una pipeline. Runner diversi possono richiedere parametri aggiuntivi. Nel nostro caso distribuiamo su Kubeflow e quella che segue è la configurazione minima.
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
Approfondimento:
Il comando passa i parametri al kpf.client. La CLI è un wrapper utile per semplificare la creazione delle pipeline su Kubeflow. Dia un'occhiata all'implementazione della CLI: è interessante e aiuta a capire come funziona il processo.
Dopo qualche minuto la pipeline è creata e pronta all'uso. Il suo team ML può sfruttare la CLI nei notebook per distribuire manualmente una nuova versione della pipeline.
C'è sempre margine di miglioramento e nella prossima sezione lo dimostreremo implementando una soluzione di continuous delivery.
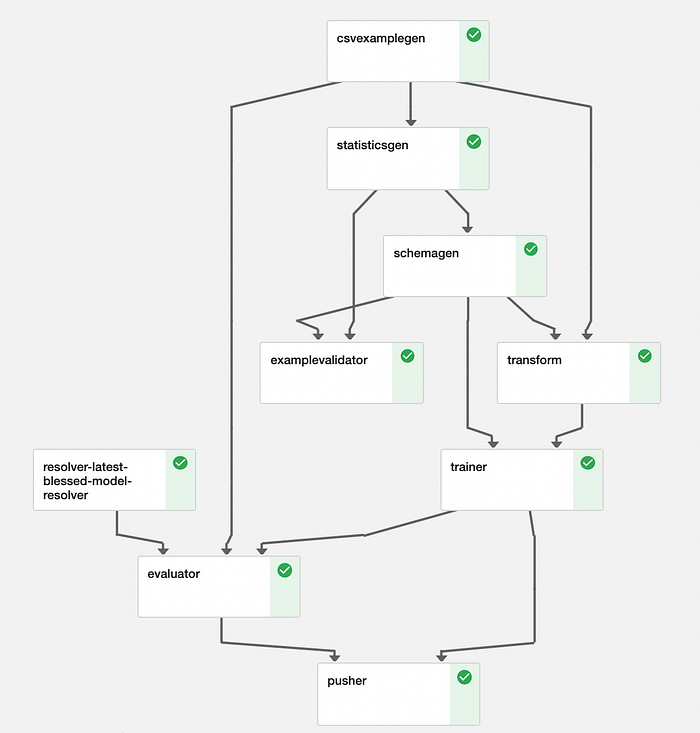
Continuous Delivery
La nostra pipeline gira su Google Cloud Platform: useremo quindi Google Cloud Build, una piattaforma CI/CD serverless.
Dalla sezione precedente sappiamo cosa serve per distribuirla.
- Un'immagine Docker che contenga la pipeline e le sue dipendenze, da pubblicare sul Google Container Registry.
- La CLI per creare la pipeline.
Con Cloud Build definiamo questi passaggi in un file yaml.
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
Il processo di build deve invocare il comando create della CLI TFX. Al momento non esiste un'immagine Docker pubblica pronta all'uso, ma possiamo costruirla con poche righe di codice.
#dockerfile (simplified, full code in repository)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
Per chiudere il cerchio del continuous deployment, colleghiamo il repository GitHub a Cloud Build e definiamo i trigger che avviano il processo. Ad esempio, a ogni push sul branch main la pipeline viene compilata e distribuita su Kubeflow.
Google Cloud Build deve poter accedere al cluster Kubernetes: si assicuri di abilitare l'accesso. https://cloud.google.com/build/docs/deploying-builds/deploy-gke
Best practice e limiti
Cimitero di dati 🧟
Ogni esecuzione della pipeline produce una certa quantità di metadati. Le nostre pipeline li memorizzano, insieme agli artefatti, su Google Cloud Storage. Per garantire l'osservabilità vengono salvati anche i dati di ciascuna esecuzione. Se l'addestramento è frequente o coinvolge dataset di grandi dimensioni, valuti di aggiungere una regola di lifecycle al bucket. A seconda del caso d'uso, può eliminare i dati più vecchi di X giorni. https://cloud.google.com/storage/docs/managing-lifecycles
Autenticazione della CLI TFX 🔑
La CLI TFX non gestisce l'autenticazione. L'ambiente da cui parte il comando deve avere accesso a Kubeflow / AI Platform Pipelines per poter creare la pipeline.
Confusione nelle API TFX 🤔
L'API TFX espone due runner Kubeflow:
Il mio istinto da ingegnere mi spingerebbe verso KubeflowV2DagRunner perché sembra più recente, ma Google consiglia KubeflowDagRunner (a marzo 2021 la V2 è ancora in sviluppo: https://github.com/tensorflow/tfx/issues/3361).
Manuali per essere automatici 🧂
La primissima versione della pipeline va creata con il comando create della CLI TFX. Le modifiche successive si applicano con il comando update. Da tenere a mente quando si imposta un processo CI/CD. Il team TFX sta lavorando a una soluzione: https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
Memoria 🍫
A seconda della soluzione di machine learning, può capitare di restare a corto di risorse. Per il nostro caso d'uso di Sentiment Analysis abbiamo dovuto aumentare la memoria predefinita di AI Platform Pipelines per portare a termine le trasformazioni (usare BERT ha i suoi costi :). https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster.
GPU
A seconda del modello, per l'addestramento potrebbero servire delle GPU. Le strade sono diverse: usare il componente AI Platform Trainer oppure aggiungere una GPU al cluster.
Funzionalità e fix lungo il percorso 💪
Vorrei mostrare quanto siano rapidi i team di TensorFlow e Kubeflow nel rispondere alle issue. Da quando ho iniziato a scrivere questo articolo a oggi, quasi tutte sono già in lavorazione.
- https://github.com/tensorflow/tfx/issues/3369 🟢 risolta
- https://github.com/tensorflow/tfx/issues/3361 🟡 in corso
- https://github.com/kubeflow/pipelines/issues/5302 🟡 in corso
- https://github.com/kubeflow/pipelines/issues/5303 🟡 in corso
- https://github.com/tensorflow/tfx/issues/3386 🟡 in corso
Sulla scia di una discussione nel gruppo Google di TFX:
Cosa ci aspetta
Resti sintonizzato per altri contenuti dedicati al machine learning.
Grazie per la lettura
Feedback e domande sono sempre benvenuti. Mi può trovare su Twitter @HeyerSascha o contattarmi su LinkedIn. Meglio ancora, si iscriva al mio canale YouTube ❤️.