O TensorFlow Extended é uma plataforma completa para implementar pipelines de ML em produção.

Para o seu pipeline de ML funcionar, você precisa de um orquestrador que rode esses pipelines. Neste artigo, vamos usar o Kubeflow nesse papel.
Ao final da leitura, você vai notar como Kubeflow e TensorFlow Extended foram feitos um para o outro ❤️.
Vamos passar pelos aspectos da criação de um pipeline do TensorFlow Extended, implantar esse pipeline no Kubeflow Pipelines usando os recursos nativos do TensorFlow Extended e, por fim, detalhar como fazer tudo isso em um fluxo de CI/CD.
Voltando ao passado
Em um artigo anterior, TensorFlow Extended 101, mostramos tudo o que você precisa saber para criar seu pipeline TFX. Agora vamos um passo além.
O que é o AI Platform Pipelines e por que estamos usando?
Quando falamos em AI Platform Pipelines, estamos falando também em Kubeflow.
O Kubeflow é formado por vários recursos, como Notebook, Pipelines, Feature Store, Serving, entre outros.
O Google AI Platform Pipelines pega um desses componentes, o Kubeflow Pipelines, e o entrega como um "serviço".
Escolha o AI Platform Pipelines se você precisa só de Pipelines e de mais nenhum outro recurso.
Daqui em diante, usamos AI Platform Pipelines e Kubeflow Pipelines como sinônimos. A abordagem que usamos também se aplica ao Kubeflow sem nenhuma adaptação extra.
Usar o AI Platform Pipelines economiza um bom tempo na configuração do Kubeflow.
Quer ir direto para o notebook e o código?
Acredito que machine learning precisa seguir os mesmos padrões de qualquer outro código. Por mais conveniente que seja, nenhum pipeline em produção deveria viver em um notebook.
Formas de criar um Kubeflow Pipeline
Dá para construir pipelines para o Kubeflow de várias maneiras. Vamos focar na primeira abordagem, mas quero apontar outros caminhos para criar Kubeflow Pipelines.
- Com TensorFlow Extended: vá por aqui se você já estiver usando TensorFlow. O pipeline TFX é compilado em um formato que o Kubeflow entende.
- Com Kubeflow Components
- Com Componentes do TensorFlow Extended implementados como Kubeflow Components.
Essa última opção é útil quando você quer combinar o TFX com outros componentes e recursos. No passado, havia suporte não oficial para esse cenário, mas ele foi descontinuado em maio de 2020 em favor do TFX SDK. De qualquer forma, se esse tipo de arquitetura te interessa, acompanhe a discussão em https://github.com/kubeflow/pipelines/issues/3853.
Instalação do AI Platform Pipelines
A instalação é simples assim: 2 cliques e alguns minutinhos de espera para subir a infraestrutura.
https://cloud.google.com/ai-platform/pipelines/docs/setting-up
O Google cuida da configuração do cluster Kubernetes necessário para rodar os Kubeflow pipelines. Você também pode instalar o Kubeflow Pipelines em um cluster Kubernetes já existente.
Se você já tem prática em gerenciar e operar Kubernetes, aproveite seu cluster atual e instale o Kubeflow Pipelines ou o Kubeflow completo.
Kubeflow Pipelines SDK
Para criar um pipeline para o Kubeflow, precisamos garantir que o Kubeflow Pipelines SDK esteja instalado.
pip install kfp
Se aparecer o erro abaixo ao criar o pipeline pela CLI, confira se o SDK foi instalado corretamente.
error Kubeflow not found
Criar o pipeline
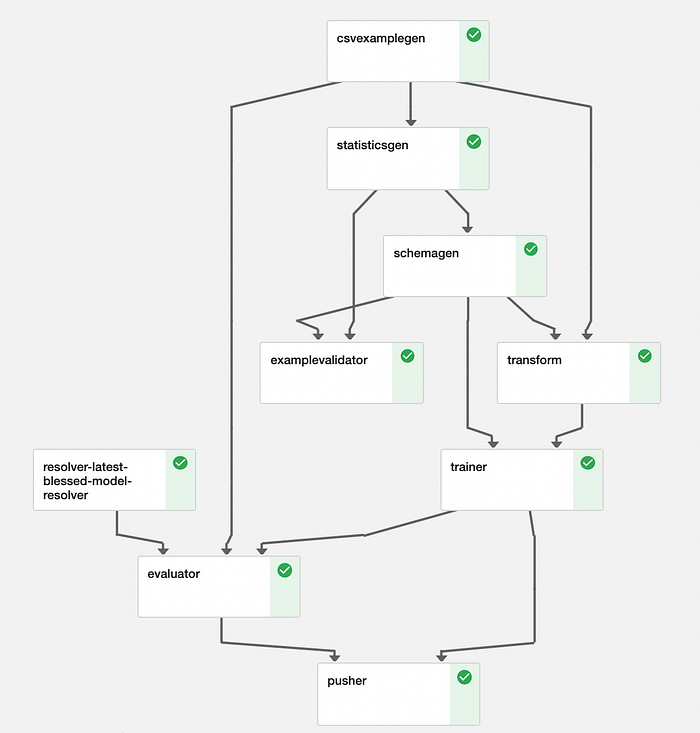
Usamos vários componentes do TensorFlow Extended. Um pipeline nada mais é do que reunir esses componentes.
#pipeline.py (simplified full code in repository)from tfx.orchestration import pipelinecomponents.append(example_gen)
components.append(trainer)
components.append(pusher)return pipeline.Pipeline(
pipealine_name=pipeline_name,
pipeline_root=pipeline_root,
components=components
)
No artigo anterior, mencionamos os possíveis orquestradores compatíveis com o TensorFlow Extended. Cada um deles exige configurações e implementação específicas para executar o pipeline.
A única parte do pipeline que muda entre esses orquestradores é o runner. Mesmo que este artigo seja focado em Kubeflow, a maior parte do código é idêntica para os outros orquestradores.
A seguir, vamos destrinchar o runner e percorrer a implementação necessária.
Primeiro, obtemos uma instância do proto KubeflowMetadataConfig. Nada mais é do que um conjunto de informações sobre como se conectar ao Kubeflow metadata. Metadata é um componente do Kubeflow usado para rastrear e gerenciar metadados de pipelines de machine learning. Relembrando o artigo anterior, falamos do ML Metadata (MLMD), que oferece funcionalidade parecida com o Kubeflow metadata.
#kubeflow_runner.py (simplified full code in repository)metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
Os pipelines do Kubeflow rodam como um container ou como vários containers. Para executar nosso pipeline TFX no Kubeflow, precisamos criar uma imagem de container Docker. O pipeline pode ter dependências específicas, como pandas ou nosso próprio código de transformação. Colocar essas dependências em um Docker permite que o pipeline rode no Kubeflow. Vamos detalhar isso na seção de CI/CD mais adiante.
Aprofundando:
Se você quiser ir mais a fundo, recomendo dar uma olhada na implementação da orquestração TFX no Kubeflow. É sempre bom entender como funcionam as ferramentas que usamos. Pela implementação, dá para ver que o TFX usa o Kubeflow SDK e a sua linguagem específica de domínio para definir o componente. A documentação do Kubeflow SDK descreve o processo usado no TFX.
Resumindo: basta lembrar que o pipeline precisa estar dentro de uma imagem de container Docker.
tfx_image = "gcr.io/sascha-playground-doit/sentiment-pipeline"
No nosso caso, o runner exige uma configuração, o KubeflowDagRunnerConfig, formado pelo nosso metadata config e pela imagem de container Docker.
#kubeflow_runner.py (simplified, full code in repository)runner_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(
kubeflow_metadata_config=metadata_config, tfx_image=tfx_image)
Para fechar, juntamos tudo definindo o nosso KubeflowDagRunner com a configuração e o pipeline. A função create_pipeline encapsula nossos componentes TFX e devolve um objeto pipeline TFX.
#kubeflow_runner.py (simplified, full code in repository)from pipeline import create_pipelinekubeflow_dag_runner.KubeflowDagRunner(config=runner_config).run( create_pipeline( pipeline_name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
)
Documentação da API do Runner:
O TFX traz um comando da CLI para criar um pipeline. Runners diferentes podem pedir parâmetros adicionais. No nosso caso, vamos implantar no Kubeflow, e abaixo está a configuração mínima necessária.
!tfx pipeline create \
--pipeline-path=./kubeflow_runner.py \
--endpoint={ENDPOINT}
Aprofundando:
O comando repassa os parâmetros para o kpf.client. A CLI funciona como um wrapper útil que simplifica a criação de pipelines no Kubeflow. Dá uma olhada na implementação da CLI: é bem interessante e ajuda a entender como o processo funciona.
Em poucos minutos, o pipeline está criado e pronto para uso. Sua equipe de ML pode usar a CLI em notebooks para implantar manualmente uma nova versão do pipeline.
Sempre dá para melhorar, e é o que vamos fazer na próxima seção, implementando uma solução de entrega contínua.
Entrega contínua
Nosso pipeline roda no Google Cloud Platform; por isso, vamos usar o Google Cloud Build, uma plataforma de CI/CD serverless.
Pela seção anterior, já sabemos do que precisamos para implantar o pipeline.
- Uma imagem de container Docker com o pipeline e suas dependências. A imagem é enviada ao Google Container Registry.
- E a CLI para criar o pipeline.
No Cloud Build, definimos essas etapas em um arquivo yaml.
# cloudbuild.yaml
steps:
# Build the image that encapsulates the pipeline.
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/sascha-playground-doit/sentiment-pipeline', '.']
dir: 'pipeline'- name: 'gcr.io/sascha-playground-doit/tfx-cli'
args: ['pipeline', 'create', '--engine', 'kubeflow', '--pipeline_path', 'runner.py', '--endpoint', 'xyz-dot-us-central1.pipelines.googleusercontent.com']
dir: 'pipeline'# Push the custom image to Container Registry
images: ['gcr.io/sascha-playground-doit/sentiment-pipeline']
O nosso processo de build precisa chamar o comando create da CLI do TFX. Hoje, não existe uma imagem Docker pública pronta para isso, mas dá para criar a nossa com poucas linhas de código.
#dockerfile (simplified, full code in repository)FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-4
COPY requirements.txt .
RUN python3 -m pip install -U -r requirements.txtENTRYPOINT ["tfx"]
Para fechar o processo de implantação contínua, conectamos nosso repositório no GitHub ao Cloud Build. Em seguida, definimos triggers para iniciar o fluxo. Por exemplo: a cada push na branch main, o pipeline é construído e implantado no Kubeflow.
O Google Cloud Build precisa de acesso ao seu cluster Kubernetes, então não esqueça de habilitar essa permissão. https://cloud.google.com/build/docs/deploying-builds/deploy-gke
Boas práticas e limitações
Cemitério de dados 🧟
Cada execução do pipeline gera uma quantidade de metadados. Os pipelines guardam esses metadados, também chamados de artefatos, no Google Cloud Storage. Para fins de observabilidade, os dados de cada execução também são armazenados. Se você treina com alta frequência ou em grandes datasets, pense em adicionar uma regra de ciclo de vida ao seu bucket. Dependendo do caso de uso, dá para excluir dados com mais de X dias. https://cloud.google.com/storage/docs/managing-lifecycles
Autenticação na CLI do TFX 🔑
A CLI do TFX não oferece suporte a autenticação. O ambiente que executa o comando precisa ter acesso ao Kubeflow / AI Platform Pipelines para criar o pipeline.
Confusão na API do TFX 🤔
A API do TFX traz dois runners diferentes para Kubeflow:
Vai contra meus instintos de engenheiro usar o KubeflowDagRunner em vez do KubeflowV2DagRunner, que parece mais novo, mas o Google recomenda mesmo o KubeflowDagRunner. (até março de 2021, a V2 ainda está em desenvolvimento https://github.com/tensorflow/tfx/issues/3361.
Seja manual para ser automático 🧂
A primeira versão do pipeline precisa ser criada com o comando create da CLI do TFX. As mudanças seguintes no pipeline são feitas com o comando update. Tenha isso em mente ao montar um processo de CI/CD. A equipe do TFX está trabalhando em uma solução https://groups.google.com/a/tensorflow.org/g/tfx/c/MhUwMLjipGs
Memória 🍫
Dependendo da sua solução de machine learning, os recursos podem ficar apertados. No nosso caso de uso de Análise de Sentimentos, precisamos aumentar a memória padrão do AI Platform Pipelines para rodar as transformações (usar BERT tem seus custos :). https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster.
GPUs
Dependendo do modelo, você pode precisar de GPUs para o treinamento. Há várias formas de usá-las: dá para escolher o componente AI Platform Trainer ou adicionar uma GPU ao cluster.
Recursos e correções nessa jornada até aqui 💪
Quero mostrar a rapidez com que as equipes do TensorFlow e do Kubeflow respondem às issues. Da escrita deste artigo até a publicação, quase todas as issues já estão em andamento.
- https://github.com/tensorflow/tfx/issues/3369 🟢 resolvido
- https://github.com/tensorflow/tfx/issues/3361 🟡 em andamento
- https://github.com/kubeflow/pipelines/issues/5302 🟡 em andamento
- https://github.com/kubeflow/pipelines/issues/5303 🟡 em andamento
- https://github.com/tensorflow/tfx/issues/3386 🟡 em andamento
A partir de uma discussão no grupo do Google sobre TFX
- https://github.com/tensorflow/tfx/issues/3417 🟡 em andamento
E o que vem por aí?
Fique de olho: vem mais conteúdo sobre machine learning por aí.
Obrigado pela leitura
Seu feedback e suas perguntas são muito bem-vindos. Você me encontra no Twitter @HeyerSascha ou pode se conectar comigo pelo LinkedIn . Melhor ainda: inscreva-se no meu canal no YouTube ❤️ .