DoiT CEOのVadim Soloveyは、記事「Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World」で、クラウドにおける重要な事実を指摘しました。それは「効率の幻想」が大きな無駄を覆い隠しうるということです。アイドル状態のリソースは見つけやすい一方、本当にコストを蝕む非効率はエンジニアリング組織やコードの内側に潜んでおり、クラウド側の再構成だけでは解決できないケースが少なくありません。
あの金色の丘の下には、まだ金が眠っている!
本記事では、原因がコード側にあるケースに絞って取り上げます。クラウドレベルからコードレベルへと調査を掘り下げるのは決して簡単ではありません。そこで、その進め方を体系的に紹介します。
クラウドコスト最適化への体系的アプローチ
ステップ1:最大のコストセンターを特定する
クラウドコスト最適化はパレートの法則(80/20ルール)に従います。つまり、ごく一部のリソースがコスト全体の大半を占めるのが通例です。まずはDoiT Cloud Intelligence™のようなツールで、支出が集中している領域を洗い出しましょう。
ステップ2:管理面で素早く成果を出す
コードに踏み込む前に、まずはクラウド管理面で着手しやすい調整から片付けましょう。
- 使用率の低いインスタンスのライトサイジング
- 不要になったまま残るリソースの削除
- 適切なストレージ階層の適用
- オートスケーリングのパラメーター調整
コードに手を入れるよりも低コストで実施できます。
ステップ3:コードレベルの非効率の兆候を探す
管理面の最適化が済んだら、コストの高いリソースについて、コードに起因する非効率がないかを点検します。
「効率の幻想」のせいで、こうした兆候は見逃されがちです。本記事の後半で紹介する事例には、見落としやすい典型的なサインを盛り込みました。多くはGCP、AWS、Azureの各コンソールにある標準的なクラウド監視ツールで把握できます。
ステップ4:調査:プロファイリングと分析
クラウド上で動かせる実行プロファイリングツールを活用し、クラウドレベルからコードレベルへ踏み込みましょう。
- データベース:Cloud Consoleのクエリアナライザーやパフォーマンスインサイト
- アプリケーション:言語別のプロファイラーやメモリアナライザー
- データパイプライン:実行グラフや分散メトリクス
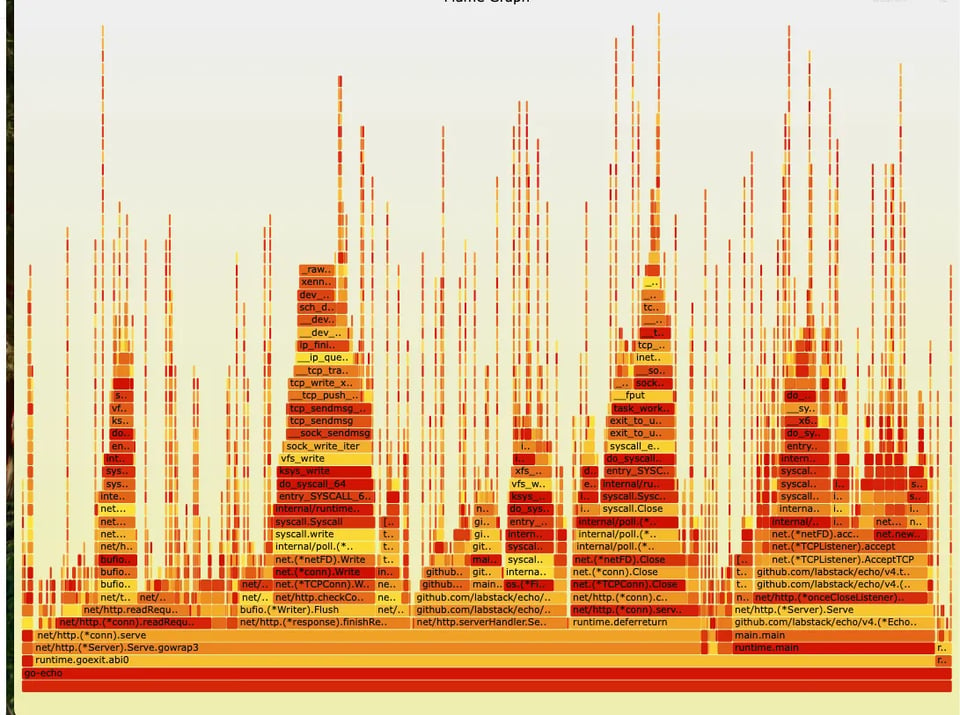 Google Cloud Profilerのフレームグラフ
Google Cloud Profilerのフレームグラフ
SQLのようにクラウド側にツールが揃っているケースは導入が容易ですが、マネージド環境上の分散アプリケーションでPythonのメモリプロファイリングを行うようなケースは難易度が高くなります。
ステップ5:実装、計測、検証
特定した問題を修正して再デプロイし、AWS、GCP、AzureのCloud Consoleで技術的な改善を計測します。あわせてCloud Intelligence™のコストレポートを確認し、コスト削減効果を検証しましょう。
実例とソリューション
シナリオ1:メモリリークを抱えたJavaマイクロサービス
一見効率的に見えたもの: メモリ使用率を70〜100%で維持していたJava Lambdaマイクロサービス。リソース割り当てを使い切れているように見えました。
実態: アプリケーションにはメモリリークがあり、グローバルオブジェクトが参照チェーンを保持して呼び出しをまたいでオブジェクトを抱え続けていました。クラッシュやインスタンスの入れ替えはまれにしか起きず、SREの目に留まりませんでした。
手がかり: モニタリングデータに、時間経過とともに鋸歯状のメモリ使用パターンが現れていました。落ち込み箇所をたどってCloudWatchログを確認したところ、定期的なクラッシュが記録されていました。
調査: CodeGuru Profilerを有効化したところ、時間とともにメモリ使用量が増加していることを確認。さらにJVMプロファイラーによるオフライン調査で、想定外のオブジェクト保持が判明しました。
解決策: 各Webリクエストの終了時にオブジェクト参照を解放するようコードを修正しました。
結果: メモリ使用量が安定し、インスタンスの入れ替えが減少、リソースコストも削減できました。
シナリオ2:非効率なデータ構造を抱えるJavaデータ処理パイプライン
一見効率的に見えたもの: カスタムJavaコンテナを用いたDataflowパイプラインで、毎日数百万件のレコードを処理し、CPU使用率も常時高水準を保っていました。
実態: コードでは非効率なデータ構造が多用されており、特にタイトループ内でオブジェクトごとに不要な文字列連結を行うマップなどが、過剰なガベージコレクションのオーバーヘッドを生んでいました。
手がかり: リソース使用率の高さが、より深い調査が必要であることを示唆していました。
調査: コンテナにGCP Cloud Profilerを組み込んだところ、データセットが大きくなるにつれて時間とメモリ使用量が超線形に増えていることが判明しました。
解決策:
- マップを、必要な情報だけを保持するカスタムオブジェクトに置き換え
- 連結の繰り返しではなく、適切な文字列結合を実装
結果: メモリ使用量を50%削減、処理時間を70%短縮し、より小さなワーカーマシンで、より少ないインスタンスでの運用が可能になりました。
シナリオ3:インメモリのデータ構造がVMを肥大化させていたケース
一見効率的に見えたもの:大容量メモリのVMは水平スケール構成と比べて一見コスト効率がよく、Pythonのインメモリデータ構造もデータベースクエリよりアルゴリズム面で速度面の優位がありました。
実態:このアプローチは複数の非効率を生み出していました。
- クラウドプロバイダーはCPUとメモリの最低比率を強制するため、高価で使い切れないCPU容量が発生する
- メモリは決まった単位でしか割り当てられず、未使用のバッファ容量分まで支払いが発生する
- 初期化に時間がかかるため、堅牢性を確保するには高価なインスタンスを複数同時に立ち上げ続ける必要があった
手がかり:DoiT Cloud Intelligence™で確認すると、総コストの大きな割合が超大容量VMから発生していました。これはクラウドアーキテクチャに問題のあるステートフル性が潜むことを示す典型的なサインです。
調査:アルゴリズムを掘り下げて分析した結果、リファクタリングによってデータをアプリケーションメモリの外に持ち出せる余地が見つかりました。
解決策:
- 必要に応じてデータベースから部分的なデータセットを取得して動作するよう、アルゴリズムをリファクタリング
- NoSQLデータベースを導入し、Redisをインメモリキャッシュとして併用
- 主要な参照データを丸ごとプリロードする必要がある箇所では、Redis上の最適化されたデータ構造により、アプリケーションメモリ上のオブジェクトよりも小さなメモリフットプリントを実現
結果:このアーキテクチャ変更によりVMサイズが大幅に縮小し、水平スケーリングが可能になり、コストも劇的に削減できました。ただし相応のエンジニアリング工数を要しました。
これまでの事例を振り返る
冒頭で触れた記事「Stop Chasing Idle Servers」から、さらに2つの事例を取り上げ、本フレームワークにどう当てはまるかを見ていきましょう。
シナリオ4:IOPSを85%まで使い切っていたデータベース
一見効率的に見えたもの: RDSインスタンスはフルに活用されているように見え、リソース割り当ても最適に思えました。
実態: 重要なインデックスが2つ欠けていたため、すべてのクエリがフルテーブルスキャンを実行しており、必要リソースを大幅に押し上げていました。
手がかり: 大半のSQLクエリは(高度にチューニングされたバッチ処理を除き)高いリソース使用率を必要としないはずです。にもかかわらず使用率が高止まりしている状態は、最適化の余地があることを示していました。
調査: AWS Consoleで標準的に有効化できるAWS RDS Performance Optimizerを用いて、問題のあるクエリと欠落しているインデックスを特定しました(GCPにも同様のCloud SQL Query Insightsがあります)。
解決策: 欠落していたインデックスを追加しました。
結果: クエリレイテンシが10分の1に短縮され、データベースを2段階ダウンサイジングできるようになりました。
シナリオ5:毎晩4時間、CPU使用率70%で稼働するSparkジョブ
一見効率的に見えたもの: クラスターはCPU使用率を高く保っており、リソース割り当ても適切に思えました。
実態: データの80%が偏った単一キーに集中しており、ストラグラータスクが発生して処理時間を大幅に引き延ばしていました。
手がかり: 問題は特定の時点から突然発生し、他に明確な原因は見当たりませんでした(後に「ホットキー」を含む新規データの流入と一致することが判明しました)。
調査: Sparkコードは高度に分散された環境で動作するため、アプリケーション向けの一般的なプロファイラーをそのまま使うのは困難です。だからこそ、ロジックは複雑なビジネスロジックではなくシンプルな変換処理に絞るのが望ましいと言えます。今回はSpark UIでステージごとのタスク分布を分析し、ストラグラーを特定。さらにBigTableの監視から、処理対象のデータベースに「ホットキー」が存在することが明らかになりました。
解決策: 問題のキーをリパーティションし、ソルティングを施すことで、workloadsをより均等に分散させました。
結果: ジョブ完了時間は4時間から45分に短縮され、必要なクラスターサイズも3分の1に削減されました。
真のクラウド効率を実現するには、クラウド側の構成にとどまらず、コードレベルの非効率にも踏み込む必要があります。コストの根本原因がコードにある場合、インフラの調整だけでは解決しません。
開発チームをFinOpsやSREと連携させることで、こうした隠れた非効率を体系的に特定・解消できます。
- コスト分析で浮かび上がる、最大の支出領域から着手する
- まずはクラウド構成レベルで実行できる素早い改善に取り組む
- Cloud Consoleで、深掘り調査を促す兆候を探す
- 適切なプロファイリングツール(できればクラウド上、必要に応じてオフライン)を使い、非効率を特定する
- コードを修正し、再デプロイして、コスト削減効果を検証する
こうした連携型のアプローチは、コスト削減だけでなく、アプリケーションのパフォーマンスや信頼性の向上にもつながることが多く、予算面でもユーザー体験の面でもメリットがあります。
私はDoiT Customer Reliability Engineeringチームで、お客様の最適化の取り組み全体を支援しています。DoiT Cloud Intelligence™と長年の知見を活かし、改善余地の特定、クラウドレベルの対処方針の提示、効率の幻想の解明、そしてコードレベルの改善効果の検証までを伴走します。お問い合わせはdoit.com/servicesまで。