Dans son article Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World, Vadim Solovey, CEO de DoiT, met en lumière une réalité essentielle du cloud computing : une illusion d'efficacité peut masquer un gaspillage considérable. Si les ressources inactives sont faciles à repérer, certaines des inefficacités les plus coûteuses se nichent au cœur de votre organisation d'ingénierie ou dans le code — là où une simple reconfiguration cloud ne suffit pas à résoudre le problème.
De l'or se cache sous ces collines !
Cet article s'attache précisément aux cas où le code est en cause. Faire descendre l'investigation du niveau cloud jusqu'au niveau code n'a rien d'évident. Voici une méthodologie pour y parvenir.
Une approche systématique de l'optimisation des coûts cloud
Étape 1 : identifier vos principaux centres de coûts
L'optimisation des coûts cloud obéit au principe de Pareto (80/20) : un faible pourcentage de vos ressources concentre généralement la majorité de vos coûts. Commencez par utiliser des outils comme DoiT Cloud Intelligence™ pour repérer vos postes de dépenses les plus importants.
Étape 2 : engranger les gains administratifs rapides
Avant de vous lancer dans l'optimisation du code, traitez d'abord les ajustements d'administration cloud les plus simples :
- Right-sizing des instances sous-utilisées
- Suppression des ressources orphelines
- Mise en place de paliers de stockage adaptés
- Ajustement des paramètres d'autoscaling
Ces actions sont bien moins coûteuses que de s'attaquer au code.
Étape 3 : repérer les indicateurs d'inefficacité au niveau du code
Une fois les optimisations administratives effectuées, examinez les ressources les plus coûteuses pour détecter d'éventuelles inefficacités liées au code.
Du fait de l'illusion d'efficacité, ces indicateurs peuvent rester subtils. Les cas concrets présentés plus loin illustrent les signaux courants à surveiller, généralement détectables grâce aux outils de monitoring standards des consoles GCP, AWS et Azure.
Étape 4 : enquêter — profiler et analyser
Passez du niveau cloud au niveau code grâce à des outils de profilage d'exécution disponibles directement dans le cloud.
- Pour les bases de données : analyseurs de requêtes des Cloud Consoles et performance insights
- Pour les applications : profilers spécifiques au langage et analyseurs de mémoire
- Pour les pipelines de données : graphes d'exécution et métriques de distribution
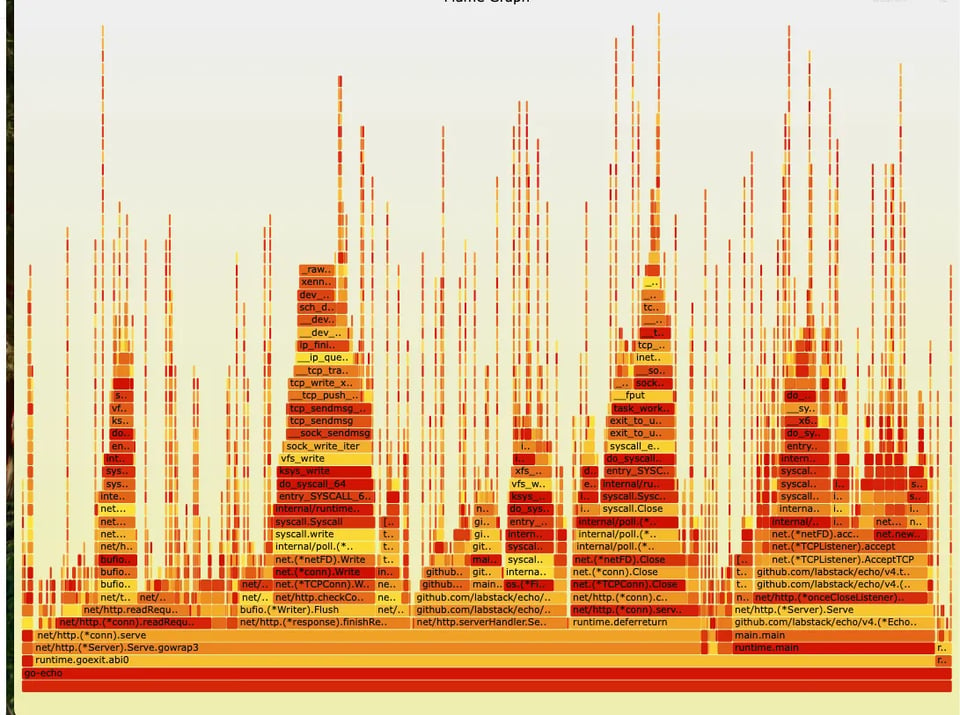 Flame graph de Google Cloud Profiler
Flame graph de Google Cloud Profiler
La mise en œuvre peut être simple, comme pour SQL où les outils sont fournis nativement dans le cloud, ou plus délicate, comme pour le profilage mémoire de Python dans des applications distribuées tournant en environnement managé.
Étape 5 : implémenter, mesurer, valider
Corrigez les problèmes identifiés, redéployez et mesurez les améliorations techniques via les Cloud Consoles AWS, GCP et Azure ; consultez les rapports de coûts Cloud Intelligence™ pour valider les gains financiers.
Cas concrets et solutions
Cas n°1 : microservice Java avec fuites de mémoire
Ce qui paraissait efficace : un microservice Java Lambda affichant 70 à 100 % d'utilisation mémoire, semblant tirer le maximum de l'allocation de ressources.
La réalité : l'application souffrait de fuites de mémoire — un objet global retenait des chaînes de références qui conservaient des objets entre les invocations. Les crashs occasionnels et les remplacements d'instances étaient suffisamment rares pour passer sous le radar des SRE.
L'indice : le monitoring laissait apparaître une utilisation mémoire en dents de scie. L'analyse des chutes a mené aux logs CloudWatch, qui révélaient des crashs périodiques.
Investigation : CodeGuru Profiler a été activé ; il a mis en évidence une utilisation mémoire qui croissait avec le temps. Des analyses hors ligne avec un profiler JVM ont identifié une rétention d'objets inattendue.
Solution : modification du code pour libérer les références d'objets à la fin de chaque requête web.
Résultat : utilisation mémoire stable, moins de remplacements d'instances et coûts de ressources réduits.
Cas n°2 : pipeline Java de traitement de données aux structures inefficaces
Ce qui paraissait efficace : un pipeline Dataflow avec des conteneurs Java personnalisés traitant des millions d'enregistrements par jour, avec une utilisation CPU constamment élevée.
La réalité : le code reposait sur des structures de données inefficaces — notamment des maps avec des concaténations de chaînes inutiles par objet dans des boucles serrées — générant une surcharge excessive du garbage collector.
L'indice : une utilisation élevée des ressources qui appelait une investigation plus approfondie.
Investigation : GCP Cloud Profiler a été ajouté au conteneur. Il a révélé une montée super-linéaire du temps et de la mémoire à mesure que les jeux de données grossissaient.
Solution :
- Remplacement des maps par des objets personnalisés ne contenant que les informations nécessaires.
- Mise en place d'une véritable jointure de chaînes au lieu de concaténations répétées.
Résultat : 50 % de mémoire en moins et 70 % de temps de traitement en moins, ce qui a permis d'utiliser des machines worker plus petites et moins d'instances.
Cas n°3 : structures de données en mémoire entraînant des VM surdimensionnées
Ce qui paraissait efficace : des VM à grande mémoire semblaient économiques face aux solutions à scaling horizontal, les structures de données Python en mémoire offrant des avantages algorithmiques par rapport aux requêtes en base.
La réalité : cette approche cumulait plusieurs inefficacités :
- Les fournisseurs cloud imposent des ratios CPU/mémoire minimaux, d'où une capacité CPU coûteuse et inutilisée.
- Les allocations mémoire se font par paliers prédéfinis, obligeant à payer pour une capacité tampon non utilisée.
- Les longs temps d'initialisation imposaient de garder plusieurs instances coûteuses tournant en parallèle pour assurer la robustesse.
L'indice : DoiT Cloud Intelligence™ révélait qu'une part importante de la dépense totale provenait de VM ultra-larges — un signal classique d'une statefulness problématique dans les architectures cloud.
Investigation : une analyse approfondie des algorithmes a fait apparaître des opportunités de refactoring permettant de stocker les données hors de la mémoire applicative.
Solution :
- Refactoring des algorithmes pour travailler sur des sous-ensembles de données interrogés en base à la demande
- Mise en place d'une base NoSQL avec Redis comme cache en mémoire
- Lorsque le préchargement complet de données de référence clés s'imposait, des structures optimisées dans Redis offraient une empreinte mémoire plus faible que les objets en mémoire applicative
Résultat : ce changement architectural a considérablement réduit la taille des VM, ouvert la voie au scaling horizontal et fait drastiquement baisser les coûts, au prix d'un effort d'ingénierie conséquent.
Retour sur des cas précédents
Reprenons deux exemples supplémentaires de l'article cité plus haut, Stop Chasing Idle Servers, pour voir comment ils s'inscrivent dans ce cadre.
Cas n°4 : base de données à 85 % d'IOPS
Ce qui paraissait efficace : l'instance RDS semblait pleinement utilisée, suggérant une allocation optimale des ressources.
La réalité : chaque requête effectuait des full-table scans faute de deux index critiques, ce qui faisait grimper les besoins en ressources de manière spectaculaire.
L'indice : la plupart des requêtes SQL ne devraient pas mobiliser autant de ressources (sauf dans des batchs très optimisés) ; un schéma d'utilisation aussi élevé révélait donc des opportunités d'optimisation.
Investigation : identification des requêtes problématiques et des index manquants à l'aide d'AWS RDS Performance Optimizer, activé par défaut dans la console AWS. (GCP propose un équivalent avec Cloud SQL Query Insights.)
Solution : ajout des index manquants.
Résultat : latence des requêtes divisée par 10 et possibilité de réduire la base de données de deux paliers.
Cas n°5 : job Spark à 70 % de CPU pendant quatre heures chaque nuit
Ce qui paraissait efficace : le cluster maintenait une utilisation CPU élevée, signe d'une allocation appropriée des ressources.
La réalité : 80 % des données étaient concentrées sur une seule clé déséquilibrée, créant des tâches traînardes qui allongeaient considérablement le temps de traitement.
L'indice : le problème est apparu à un moment précis, sans autre cause apparente. (On a découvert plus tard que cela coïncidait avec l'arrivée de nouvelles données contenant la hot key.)
Investigation : le code Spark s'exécute dans un environnement hautement distribué, ce qui rend difficile le recours à un profiler classique. Raison de plus pour cantonner la logique à des transformations simples plutôt qu'à de la logique métier complexe. Cela dit, l'analyse de la distribution des tâches entre les stages via la Spark UI a permis d'identifier les traînards. Le monitoring BigTable a révélé des hot keys dans la base traitée.
Solution : repartitionnement et salting de la clé problématique pour répartir plus uniformément les workloads.
Résultat : temps d'exécution du job ramené de 4 heures à 45 minutes, et taille du cluster nécessaire réduite des deux tiers.
Atteindre une véritable efficacité cloud impose parfois d'aller au-delà des configurations cloud et de s'attaquer aussi aux inefficacités au niveau du code. Lorsque le code est à l'origine de coûts cloud excessifs, ajuster l'infrastructure ne suffira pas.
En faisant collaborer votre équipe de développement avec le FinOps et les SRE, vous pouvez identifier et résoudre ces inefficacités cachées grâce à une approche systématique :
- Commencez par les postes de dépenses les plus importants identifiés dans l'analyse des coûts.
- Traitez d'abord les gains rapides au niveau de la configuration cloud.
- Dans les Cloud Consoles, repérez les signaux qui appellent une investigation plus poussée.
- Utilisez des outils de profilage adaptés, de préférence dans le cloud mais hors ligne si nécessaire, pour cibler les inefficacités.
- Corrigez le code, redéployez et validez les gains financiers.
Cette approche collaborative ne se contente pas de réduire les coûts : elle améliore souvent aussi la performance et la fiabilité des applications — un gain à la fois pour votre budget et pour vos utilisateurs.
Au sein de l'équipe DoiT Customer Reliability Engineering, j'accompagne les organisations tout au long de leur parcours d'optimisation. Forts de DoiT Cloud Intelligence™ et de décennies d'expérience, nous aidons à identifier les gains potentiels, à décrire les correctifs au niveau cloud, à déjouer les illusions d'efficacité et à valider l'impact des améliorations apportées au code. Contactez-nous sur doit.com/services