Nell'articolo " Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World", il CEO di DoiT Vadim Solovey ha messo in luce una verità importante del cloud computing: l'"illusione di efficienza" può nascondere sprechi consistenti. Le risorse inattive sono facili da individuare, ma alcune delle inefficienze più costose si annidano nei team di engineering o nel codice — terreni in cui la sola riconfigurazione del cloud non basta a risolvere il problema.
C'è oro sotto quelle colline d'oro!
Questo articolo si concentra proprio su quei casi in cui la responsabilità è del codice. Spostare l'analisi dal piano cloud a quello del codice non è sempre semplice: in queste pagine propongo una metodologia.
Un approccio sistematico all'ottimizzazione dei costi cloud
Fase 1: individuare i principali centri di costo
L'ottimizzazione dei costi cloud segue il principio di Pareto (80/20): di norma una piccola percentuale delle risorse genera la maggior parte della spesa. Si parta da strumenti come DoiT Cloud Intelligence™ per individuare le aree di spesa più rilevanti.
Fase 2: ottenere risultati rapidi sul piano amministrativo
Prima di addentrarsi nelle ottimizzazioni del codice, conviene affrontare gli interventi più semplici di amministrazione cloud:
- right-sizing delle istanze sottoutilizzate;
- rimozione delle risorse orfane;
- adozione di tier di storage adeguati;
- taratura dei parametri di autoscaling.
Sono interventi meno onerosi rispetto a mettere mano al codice.
Fase 3: cercare gli indicatori di inefficienza a livello di codice
Una volta completate le ottimizzazioni amministrative, si esaminino le risorse a costo elevato per individuare possibili inefficienze imputabili al codice.
A causa dell'"illusione di efficienza", questi indicatori possono essere sfumati. Gli scenari reali presentati più avanti illustrano i segnali rivelatori più comuni a cui prestare attenzione, spesso emersi grazie agli strumenti standard di monitoraggio nelle Console di GCP, AWS e Azure.
Fase 4: analizzare con profiling e indagini mirate
Si passa dal piano cloud a quello del codice usando strumenti di profiling dell'esecuzione che possono girare nel cloud.
- Per i database: query analyzer e performance insights della Cloud Console.
- Per le applicazioni: profiler specifici del linguaggio e analizzatori di memoria.
- Per le pipeline di dati: grafi di esecuzione e metriche di distribuzione.
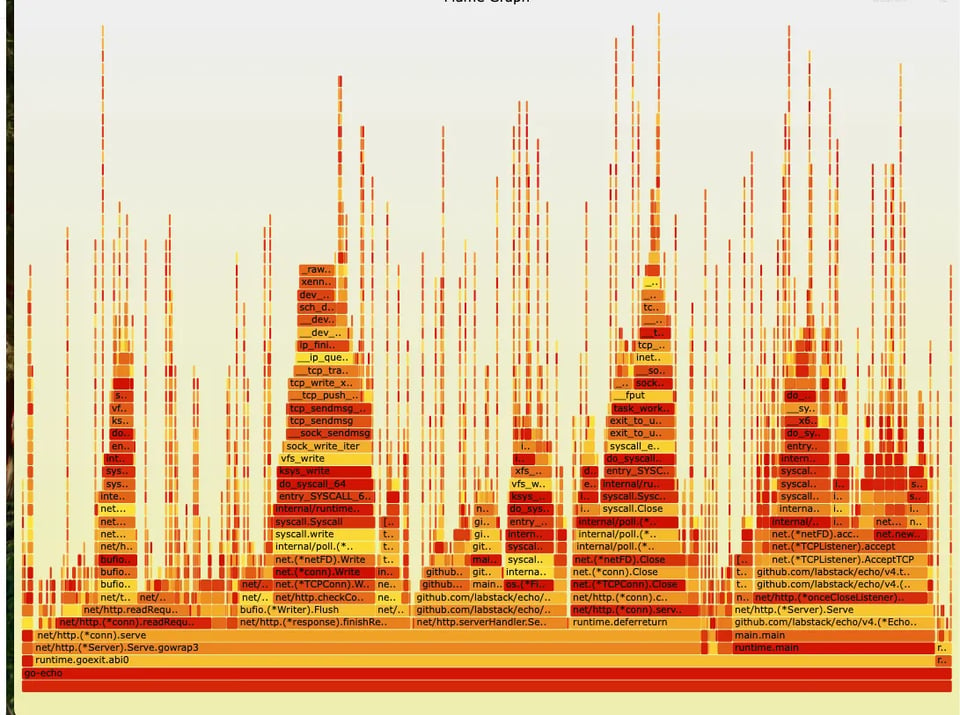 Flame graph di Google Cloud Profiler
Flame graph di Google Cloud Profiler
L'attuazione può essere immediata, come per SQL dove gli strumenti sono già integrati nel cloud, oppure complessa, come nel profiling della memoria di Python in applicazioni distribuite eseguite in ambienti gestiti.
Fase 5: implementare, misurare, validare
Si correggano i problemi individuati, si esegua il redeploy e si misurino i miglioramenti tecnici tramite le Cloud Console di AWS, GCP e Azure; quindi si consultino i report di costo di Cloud Intelligence™ per validare i benefici economici.
Scenari reali e soluzioni
Scenario 1: microservizio Java con memory leak
Cosa sembrava efficiente: un microservizio Java Lambda con utilizzo della memoria al 70-100%, apparentemente al massimo dello sfruttamento delle risorse.
La realtà: l'applicazione era affetta da memory leak: un oggetto globale tratteneva catene di riferimenti, conservando oggetti tra una invocazione e l'altra. Crash occasionali e sostituzioni di istanza erano abbastanza rari da sfuggire all'attenzione del team SRE.
L'indizio: il monitoraggio mostrava un andamento dell'uso della memoria a dente di sega. Indagando sui cali in quel pattern siamo arrivati ai log di CloudWatch, che evidenziavano crash periodici.
L'indagine: abbiamo attivato CodeGuru Profiler, che ha confermato un consumo di memoria crescente nel tempo. Analisi offline con un profiler JVM hanno individuato una ritenzione inattesa di oggetti.
La soluzione: il codice è stato modificato per rilasciare i riferimenti agli oggetti al termine di ogni richiesta web.
Il risultato: consumo di memoria stabile, meno sostituzioni di istanza e costi delle risorse ridotti.
Scenario 2: pipeline Java di elaborazione dati con strutture dati inefficienti
Cosa sembrava efficiente: una pipeline Dataflow con container Java personalizzati che elaborava milioni di record al giorno con un utilizzo della CPU costantemente elevato.
La realtà: il codice usava strutture dati inefficienti, fra cui mappe con concatenazioni superflue di stringhe per ogni oggetto in cicli stretti, generando un eccessivo overhead di garbage collection.
L'indizio: l'elevato consumo di risorse suggeriva la necessità di un'analisi più approfondita.
L'indagine: abbiamo aggiunto GCP Cloud Profiler al container, che ha evidenziato una crescita superlineare di tempi e memoria all'aumentare delle dimensioni dei dataset.
La soluzione:
- sostituzione delle mappe con oggetti personalizzati contenenti soltanto le informazioni necessarie;
- uso di un join corretto delle stringhe al posto di concatenazioni ripetute.
Il risultato: 50% di memoria in meno e 70% in meno di tempo di elaborazione, con la possibilità di adottare worker più piccoli e ridurre il numero di istanze.
Scenario 3: strutture dati in memoria che imponevano VM sovradimensionate
Cosa sembrava efficiente: VM con grande quantità di memoria sembravano economicamente vantaggiose rispetto a soluzioni scalate orizzontalmente, e le strutture dati Python in memoria offrivano vantaggi algoritmici di velocità rispetto alle query a database.
La realtà: questo approccio generava molteplici inefficienze:
- i cloud provider impongono rapporti minimi tra CPU e memoria, con il risultato di una capacità CPU costosa e inutilizzata;
- le allocazioni di memoria avvengono in incrementi predefiniti, costringendo a pagare per capacità di buffer non sfruttata;
- i lunghi tempi di inizializzazione imponevano di tenere in esecuzione contemporaneamente più istanze costose per garantire la robustezza.
L'indizio: DoiT Cloud Intelligence™ mostrava che una quota rilevante della spesa totale proveniva da VM ultra-grandi — di norma un campanello d'allarme per architetture cloud con problemi di statefulness.
L'indagine: un'analisi approfondita degli algoritmi ha messo in luce opportunità di refactoring per spostare i dati al di fuori della memoria dell'applicazione.
La soluzione:
- refactoring degli algoritmi per lavorare con dataset parziali interrogati dal database al bisogno;
- introduzione di un database NoSQL con Redis come cache in memoria;
- laddove era necessario il preloading completo dei dati di riferimento principali, strutture dati ottimizzate in Redis hanno consentito un footprint di memoria inferiore rispetto agli oggetti tenuti nella memoria dell'applicazione.
Il risultato: questo cambiamento architetturale ha ridotto in modo significativo le dimensioni delle VM, abilitando lo scaling orizzontale e tagliando radicalmente i costi, pur richiedendo un notevole sforzo di engineering.
Riesame dei casi precedenti
Torniamo a due ulteriori esempi tratti dall'articolo citato in apertura, " Stop Chasing Idle Servers", per vedere come si collocano in questo framework.
Scenario 4: database all'85% di IOPS
Cosa sembrava efficiente: l'istanza RDS appariva pienamente utilizzata, lasciando supporre un'allocazione ottimale delle risorse.
La realtà: ogni query eseguiva scansioni complete di tabella per via di due indici critici mancanti, facendo lievitare il fabbisogno di risorse.
L'indizio: poiché la maggior parte delle query SQL non dovrebbe richiedere un utilizzo elevato di risorse (salvo in processi batch fortemente ottimizzati), un pattern di alto utilizzo lasciava intravedere margini di ottimizzazione.
L'indagine: abbiamo individuato le query problematiche e gli indici mancanti con AWS RDS Performance Optimizer, attivabile out-of-the-box dalla AWS Console (GCP offre l'analogo Cloud SQL Query Insights).
La soluzione: sono stati aggiunti gli indici mancanti.
Il risultato: latenza delle query ridotta di 10 volte e possibilità di ridimensionare il database di due tier.
Scenario 5: job Spark al 70% di CPU per quattro ore ogni notte
Cosa sembrava efficiente: il cluster manteneva un utilizzo elevato della CPU, segnale apparente di un'allocazione adeguata delle risorse.
La realtà: l'80% dei dati era concentrato su un'unica chiave sbilanciata, generando task straggler che allungavano sensibilmente i tempi di elaborazione.
L'indizio: il problema è iniziato in un momento ben preciso, senza altre cause evidenti (in seguito si è scoperto che corrispondeva all'arrivo di nuovi dati con la "hot key").
L'indagine: il codice Spark gira in un ambiente fortemente distribuito, e questo rende difficile usare un profiler ordinario come si farebbe per le applicazioni. Un buon motivo per concentrare la logica su trasformazioni semplici, evitando logica di business complessa. La Spark UI, però, ha permesso di analizzare la distribuzione dei task fra gli stage e individuare gli straggler. Il monitoraggio di BigTable ha poi rivelato "hot key" nel database in elaborazione.
La soluzione: la chiave problematica è stata ripartizionata e "salata" per distribuire i workloads in modo più uniforme.
Il risultato: il tempo di completamento del job è sceso da 4 ore a 45 minuti e la dimensione del cluster necessario è stata ridotta di due terzi.
Raggiungere una vera efficienza cloud richiede a volte di andare oltre la configurazione dell'infrastruttura e di affrontare le inefficienze anche a livello di codice. Quando la causa profonda dei costi cloud in eccesso è il codice, le sole modifiche infrastrutturali non risolvono il problema.
Facendo lavorare a stretto contatto il team di sviluppo con FinOps e SRE è possibile individuare e risolvere queste inefficienze nascoste con un approccio sistematico:
- partire dalle aree di spesa principali evidenziate dalle analytics dei costi;
- affrontare innanzitutto i quick win sul piano della configurazione cloud;
- nelle Cloud Console, cercare i segnali rivelatori che giustificano un'analisi più approfondita;
- usare strumenti di profiling adeguati, preferibilmente in cloud ma offline se necessario, per individuare con precisione le inefficienze;
- correggere il codice, eseguire il redeploy e validare i miglioramenti di costo.
Questo approccio collaborativo non solo riduce i costi, ma spesso migliora anche le prestazioni e l'affidabilità delle applicazioni — un vantaggio sia per il budget sia per gli utenti.
Nel team Customer Reliability Engineering di DoiT accompagno le organizzazioni lungo l'intero percorso di ottimizzazione. Grazie a DoiT Cloud Intelligence™ e a decenni di esperienza, aiutiamo a individuare i potenziali miglioramenti, definiamo le correzioni a livello cloud, smascheriamo le illusioni di efficienza e validiamo l'impatto degli interventi sul codice. Ci contatti su doit.com/services