En su artículo " Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World", Vadim Solovey, CEO de DoiT, expuso una realidad clave del cloud computing: la "ilusión de eficiencia" puede esconder una pérdida considerable. Los recursos inactivos saltan a la vista, pero las ineficiencias más costosas suelen ocultarse dentro del equipo de Engineering o en el propio código, donde reconfigurar la nube no basta para resolver el problema.
¡Hay oro debajo de esas colinas!
Este artículo se enfoca específicamente en los casos donde el código es el responsable. No siempre es fácil llevar la investigación desde el nivel de la nube hasta el nivel del código. A continuación te presento una metodología.
Un enfoque sistemático para optimizar los costos en la nube
Paso 1: Identifica tus mayores centros de costo
La optimización de costos en la nube sigue el principio de Pareto (80/20): un porcentaje pequeño de tus recursos suele concentrar la mayor parte del gasto. Empieza por usar herramientas como DoiT Cloud Intelligence™ para detectar tus áreas de mayor gasto.
Paso 2: Aprovecha las victorias rápidas a nivel administrativo
Antes de meterte de lleno en optimizaciones de código, atiende primero los ajustes más simples de administración en la nube:
- Aplicar right-sizing a las instancias subutilizadas
- Eliminar recursos huérfanos
- Implementar los tiers de almacenamiento adecuados
- Ajustar los parámetros de autoescalado
Estas acciones salen más baratas que ponerse a tocar el código.
Paso 3: Busca indicadores de ineficiencia a nivel de código
Una vez completadas las optimizaciones administrativas, revisa los recursos de alto costo en busca de posibles ineficiencias originadas en el código.
Por la "ilusión de eficiencia", estos indicadores pueden ser sutiles. Los escenarios reales que se analizan más adelante en este artículo ilustran señales típicas a las que conviene estar atento, que suelen detectarse con las herramientas estándar de monitoreo en las consolas de GCP, AWS y Azure.
Paso 4: Investiga: perfila y analiza
Pasa del nivel de la nube al nivel del código con herramientas de profiling de ejecución que puedan correr en la nube.
- Para bases de datos: analizadores de queries y performance insights de la consola de la nube
- Para aplicaciones: profilers específicos del lenguaje y analizadores de memoria
- Para pipelines de datos: gráficos de ejecución y métricas de distribución
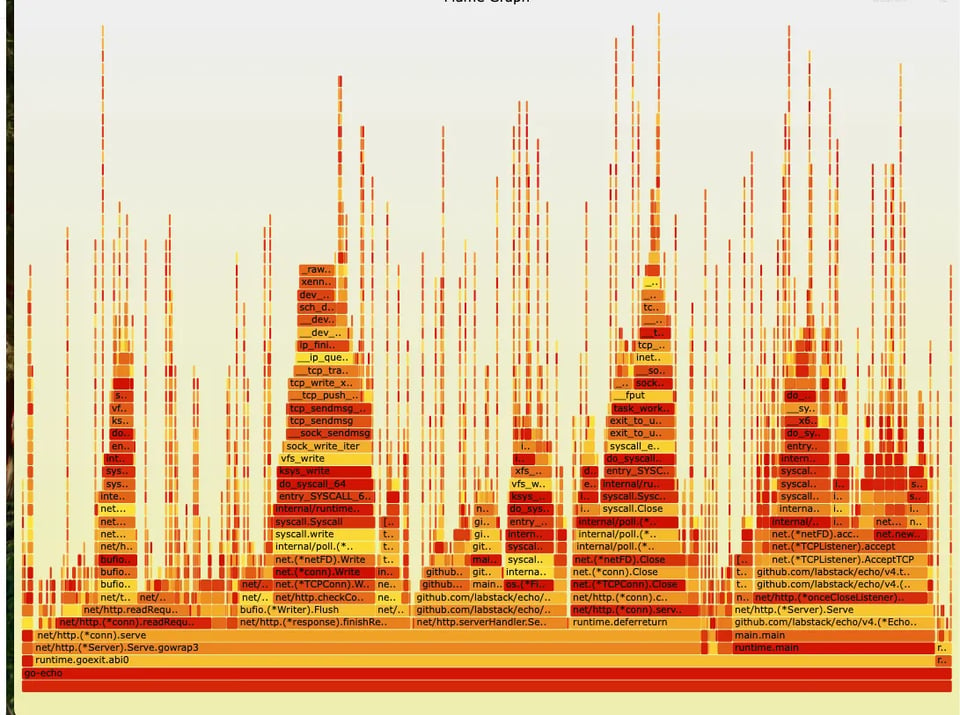 Flame Graph de Google Cloud Profiler
Flame Graph de Google Cloud Profiler
La implementación puede ser sencilla, como en SQL, donde las herramientas vienen integradas en la nube, o complicada, como en el profiling de memoria de Python en aplicaciones distribuidas que corren en entornos administrados.
Paso 5: Implementa, mide, valida
Corrige los problemas detectados, vuelve a desplegar y mide las mejoras técnicas con las consolas de AWS, GCP y Azure; después revisa los reportes de costos de Cloud Intelligence™ para validar las mejoras económicas.
Escenarios reales y soluciones
Escenario 1: microservicio Java con fugas de memoria
Lo que parecía eficiente: un microservicio Java en Lambda que mantenía una utilización de memoria del 70–100%, aparentemente aprovechando al máximo la asignación de recursos.
La realidad: la aplicación tenía fugas de memoria; un objeto global retenía cadenas de referencias que conservaban objetos entre invocaciones. Los crashes ocasionales y los reemplazos de instancia eran lo bastante esporádicos como para pasar desapercibidos para el equipo de SRE.
La pista: el monitoreo reveló un patrón de uso de memoria con forma de sierra a lo largo del tiempo. Investigar las caídas de ese patrón llevó a logs de CloudWatch que mostraban crashes periódicos.
Investigación: se activó CodeGuru Profiler, que evidenció un uso creciente de memoria con el tiempo. El análisis offline con un profiler de JVM detectó una retención inesperada de objetos.
Solución: se modificó el código para liberar las referencias a objetos al final de cada request web.
Resultado: uso de memoria estable, menos reemplazos de instancia y menores costos de recursos.
Escenario 2: pipeline de procesamiento de datos en Java con estructuras de datos ineficientes
Lo que parecía eficiente: un pipeline de Dataflow con contenedores Java personalizados que procesaba millones de registros al día con un uso de CPU consistentemente alto.
La realidad: el código usaba estructuras de datos ineficientes, con maps que concatenaban strings por objeto de forma innecesaria dentro de loops cerrados, lo que generaba una sobrecarga excesiva de garbage collection.
La pista: el alto consumo de recursos hacía pensar en la necesidad de una investigación más profunda.
Investigación: se agregó GCP Cloud Profiler al contenedor. Esto mostró un escalado superlineal del tiempo y del uso de memoria con datasets más grandes.
Solución:
- Se reemplazaron los maps por objetos personalizados que solo guardaban la información necesaria.
- Se implementó un join apropiado de strings en lugar de concatenación repetida.
Resultado: 50% menos uso de memoria y una reducción del 70% en el tiempo de procesamiento, lo que permitió usar máquinas worker más pequeñas y menos instancias.
Escenario 3: estructuras de datos en memoria que provocan VMs sobredimensionadas
Lo que parecía eficiente: las VMs de gran memoria parecían rentables frente a las soluciones escaladas horizontalmente, ya que las estructuras de datos en memoria de Python ofrecían ventajas algorítmicas de velocidad sobre las consultas a la base de datos.
La realidad: este enfoque generaba varias ineficiencias:
- Los proveedores de nube imponen relaciones mínimas de CPU a memoria, lo que se traduce en capacidad de CPU costosa y sin usar.
- La memoria se asigna en incrementos predefinidos, así que se termina pagando por capacidad de buffer no utilizada.
- Los largos tiempos de inicialización obligaban a mantener varias instancias costosas corriendo en paralelo por robustez.
La pista: DoiT Cloud Intelligence™ mostró que una gran fracción del gasto total provenía de VMs ultra grandes, lo que suele indicar un problema de statefulness en arquitecturas en la nube.
Investigación: un análisis profundo de los algoritmos reveló oportunidades de refactorización para almacenar los datos fuera de la memoria de la aplicación.
Solución:
- Se refactorizaron los algoritmos para trabajar con datasets parciales consultados a las bases de datos según se necesitara
- Se implementó una base de datos NoSQL con Redis como caché en memoria
- Donde se requería precargar todos los datos de referencia clave, las estructuras optimizadas en Redis lograron una huella de memoria menor que los objetos en la memoria de la aplicación
Resultado: este cambio arquitectónico redujo significativamente el tamaño de las VMs, habilitó el escalado horizontal y bajó los costos de forma radical, aunque requirió un esfuerzo considerable de Engineering.
Repasando casos anteriores
Volvamos a otros dos ejemplos del artículo que mencioné antes, " Stop Chasing Idle Servers", para ver cómo encajan en este marco.
Escenario 4: base de datos al 85% de IOPS
Lo que parecía eficiente: la instancia de RDS aparentaba estar plenamente utilizada, lo que sugería una asignación óptima de recursos.
La realidad: cada query estaba haciendo full-table scans por la falta de dos índices críticos, lo que disparaba el consumo de recursos.
La pista: dado que la mayoría de las queries SQL no debería requerir un consumo alto de recursos (salvo en procesos batch muy afinados), un patrón de alta utilización apuntaba a oportunidades de optimización.
Investigación: se identificaron las queries problemáticas y los índices faltantes con AWS RDS Performance Optimizer, activado out-of-the-box en la consola de AWS. (GCP tiene el equivalente Cloud SQL Query Insights).
Solución: se agregaron los índices faltantes.
Resultado: reducción de 10x en la latencia de las queries y la posibilidad de bajar dos niveles el tamaño de la base de datos.
Escenario 5: job de Spark al 70% de CPU durante cuatro horas cada noche
Lo que parecía eficiente: el cluster mantenía un uso alto de CPU, lo que sugería una asignación adecuada de recursos.
La realidad: el 80% de los datos estaba concentrado en una sola clave sesgada, lo que generaba tareas straggler que alargaban significativamente el tiempo de procesamiento.
La pista: el problema empezó en un momento puntual sin otra causa clara. (Más tarde se determinó que coincidía con la llegada de nuevos datos con la "hot key").
Investigación: el código de Spark corre en un entorno altamente distribuido, lo que dificulta usar un profiler convencional como el que usarías para aplicaciones. Esta es una buena razón para mantener la lógica enfocada en transformaciones simples y no en lógica de negocio compleja. De todos modos, analizar la distribución de tareas entre stages con la Spark UI permitió identificar a los stragglers. El monitoreo de BigTable reveló "hot keys" en la base de datos que se estaba procesando.
Solución: se reparticionó y se aplicó salting a la clave problemática para distribuir el workload de forma más pareja.
Resultado: el tiempo de ejecución del job bajó de 4 horas a 45 minutos, y el tamaño necesario del cluster se redujo en dos tercios.
Lograr verdadera eficiencia en la nube a veces exige ir más allá de las configuraciones y atacar también las ineficiencias a nivel de código. Cuando el código es la causa raíz del exceso de costos en la nube, los ajustes de infraestructura por sí solos no van a resolver el problema.
Al sumar a tu equipo de desarrollo con FinOps y SRE, puedes identificar y resolver estas ineficiencias ocultas con un enfoque sistemático:
- Empieza por las áreas de mayor gasto que muestran las analíticas de costos.
- Primero, atiende las victorias rápidas a nivel de configuración de la nube.
- En las consolas de la nube, busca señales reveladoras que ameriten una investigación más profunda.
- Usa las herramientas de profiling adecuadas, preferentemente en la nube y, si hace falta, offline, para detectar las ineficiencias.
- Corrige el código, vuelve a desplegar y valida las mejoras de costo.
Este enfoque colaborativo no solo reduce costos: muchas veces también mejora el rendimiento y la confiabilidad de las aplicaciones, una victoria tanto para tu presupuesto como para tus usuarios.
En el equipo de Customer Reliability Engineering de DoiT acompaño a las organizaciones a lo largo de todo el camino de optimización. Apoyándonos en DoiT Cloud Intelligence™ y en décadas de experiencia, ayudamos a identificar oportunidades, definir soluciones a nivel de nube, desenmascarar ilusiones de eficiencia y validar el impacto de las mejoras a nivel de código. Escríbenos en doit.com/services