No artigo " Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World", o CEO da DoiT, Vadim Solovey, destacou uma realidade importante da computação em nuvem: a "ilusão de eficiência" pode esconder um desperdício e tanto. Recursos ociosos são fáceis de identificar, mas algumas das ineficiências mais caras se escondem dentro da sua área de engenharia ou no próprio código — onde reconfigurar a nuvem, sozinho, não resolve o problema.
Tem ouro debaixo daquelas colinas douradas!
Este artigo foca justamente nos casos em que o vilão é o código. Nem sempre é simples levar a investigação do nível da nuvem até o nível do código. É essa metodologia que vou apresentar.
Uma abordagem sistemática para otimizar custos de nuvem
Passo 1: identifique seus maiores centros de custo
A otimização de custos de nuvem segue o Princípio de Pareto (80/20) — uma pequena parcela dos seus recursos costuma responder pela maior parte dos custos. Comece usando ferramentas como o DoiT Cloud Intelligence™ para identificar suas maiores áreas de despesa.
Passo 2: garanta as vitórias administrativas rápidas
Antes de mergulhar em otimizações de código, ataque primeiro os ajustes mais simples de administração da nuvem:
- Right-sizing de instâncias subutilizadas
- Remoção de recursos órfãos
- Adoção de tiers de armazenamento adequados
- Ajuste de parâmetros de autoscaling
Sai bem mais barato do que mexer no código.
Passo 3: procure indícios de ineficiência no nível do código
Concluídas as otimizações administrativas, examine os recursos de alto custo em busca de possíveis ineficiências causadas pelo código.
Por causa da "ilusão de eficiência", esses indícios podem ser sutis. Os cenários reais discutidos mais adiante neste artigo mostram sinais comuns aos quais ficar atento, em geral identificáveis com as ferramentas padrão de monitoramento dos Consoles do GCP, AWS e Azure.
Passo 4: investigue, faça profiling e analise
Saia do nível da nuvem para o nível do código com ferramentas de profiling de execução que rodam na própria nuvem.
- Para bancos de dados: query analyzers e performance insights do Cloud Console
- Para aplicações: profilers e analisadores de memória específicos da linguagem
- Para data pipelines: gráficos de execução e métricas de distribuição
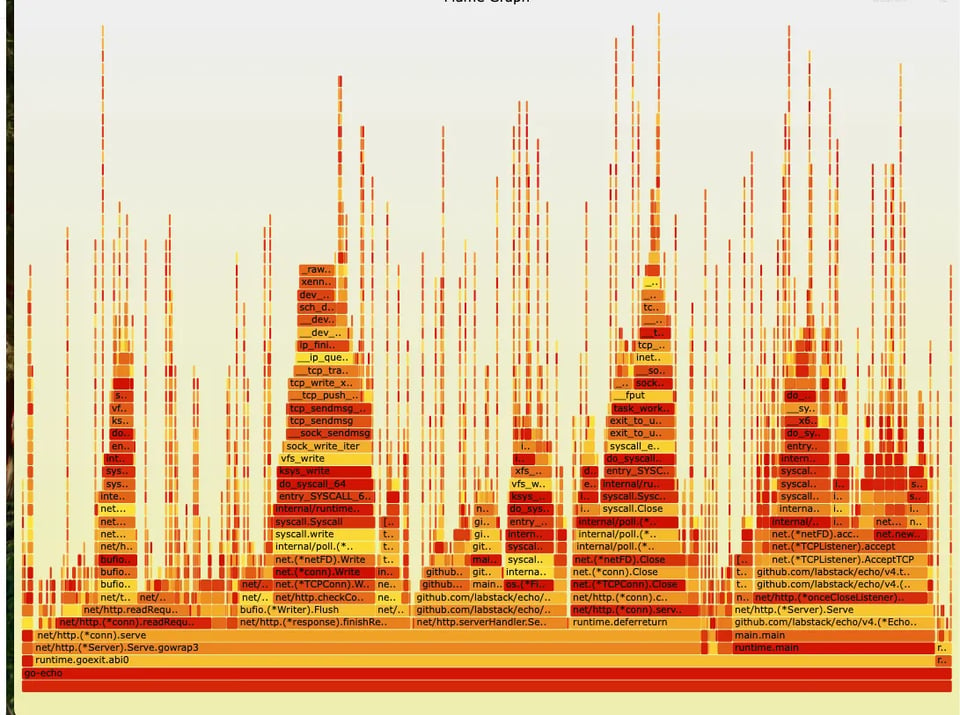 Flame Graph do Google Cloud Profiler
Flame Graph do Google Cloud Profiler
Essa implementação pode ser fácil — como em SQL, em que as ferramentas já vêm prontas na nuvem — ou difícil, como no profiling de memória de Python em aplicações distribuídas rodando em ambientes gerenciados.
Passo 5: implemente, meça e valide
Corrija os problemas identificados, faça o redeploy e meça as melhorias técnicas pelos Cloud Consoles da AWS, GCP e Azure; depois, confira os relatórios de custo do Cloud Intelligence™ para validar os ganhos financeiros.
Cenários reais e suas soluções
Cenário 1: microsserviço Java com vazamentos de memória
O que parecia eficiente: um microsserviço Java em Lambda mantendo de 70 a 100% de utilização de memória, aparentemente tirando o máximo proveito da alocação de recursos.
A realidade: a aplicação sofria com vazamentos de memória — um objeto global mantinha cadeias de referência que retinham objetos entre invocações. Crashes ocasionais e substituições de instâncias eram raros o suficiente para passar despercebidos pelo time de SRE.
A pista: o monitoramento revelou um padrão de uso de memória em dente de serra ao longo do tempo. Investigar as quedas desse padrão levou aos logs do CloudWatch, que mostravam crashes periódicos.
Investigação: ativamos o CodeGuru Profiler, que evidenciou aumento progressivo no uso de memória ao longo do tempo. Análises offline com um JVM profiler identificaram a retenção inesperada de objetos.
Solução: alteramos o código para liberar as referências aos objetos no fim de cada requisição web.
Resultado: uso de memória estável, menos substituições de instâncias e custos de recursos mais baixos.
Cenário 2: pipeline Java de processamento de dados com estruturas ineficientes
O que parecia eficiente: um pipeline do Dataflow com containers Java customizados processando milhões de registros por dia, com utilização de CPU consistentemente alta.
A realidade: o código usava estruturas de dados ineficientes, incluindo maps com concatenação desnecessária de strings por objeto em loops apertados, gerando uma sobrecarga excessiva de garbage collection.
A pista: o alto uso de recursos sugeria a necessidade de uma investigação mais profunda.
Investigação: adicionamos o GCP Cloud Profiler ao container, o que evidenciou um escalonamento super-linear do tempo e do uso de memória conforme os datasets cresciam.
Solução:
- Substituímos os maps por objetos customizados, guardando apenas as informações necessárias.
- Implementamos junção de strings adequada em vez de concatenação repetida
Resultado: 50% menos uso de memória e 70% de redução no tempo de processamento, viabilizando máquinas worker menores e em menor número.
Cenário 3: estruturas de dados em memória inflando o tamanho das VMs
O que parecia eficiente: VMs com muita memória aparentavam um bom custo-benefício frente a soluções com escalonamento horizontal, e estruturas de dados Python em memória ofereciam vantagens algorítmicas de velocidade em relação a queries no banco de dados.
A realidade: essa abordagem criou várias ineficiências:
- Os provedores de nuvem impõem proporções mínimas de CPU em relação à memória, resultando em capacidade de CPU cara e ociosa.
- As alocações de memória vêm em incrementos predefinidos, o que faz você pagar por capacidade de buffer não utilizada.
- Tempos de inicialização longos exigiam manter várias instâncias caras rodando ao mesmo tempo para garantir robustez.
A pista: o DoiT Cloud Intelligence™ mostrou que uma fatia grande da despesa total vinha de VMs gigantes — em geral, um indicador de problemas de statefulness em arquiteturas de nuvem.
Investigação: uma análise profunda dos algoritmos revelou oportunidades de refatorar e armazenar os dados fora da memória da aplicação.
Solução:
- Refatoramos os algoritmos para trabalhar com datasets parciais consultados nos bancos de dados conforme a necessidade
- Implementamos um banco NoSQL com Redis como cache em memória
- Quando o pré-carregamento total era necessário para dados de referência críticos, estruturas otimizadas no Redis ocuparam menos memória do que objetos na memória da aplicação
Resultado: essa mudança arquitetural reduziu bastante o tamanho das VMs, viabilizou o escalonamento horizontal e cortou os custos drasticamente, embora tenha exigido um esforço considerável de engenharia.
Revisitando casos anteriores
Vamos voltar a mais dois exemplos do artigo que mencionei antes, " Stop Chasing Idle Servers", e ver como eles se encaixam nesse framework.
Cenário 4: banco de dados a 85% de IOPS
O que parecia eficiente: a instância RDS aparentava estar totalmente utilizada, sugerindo alocação ótima de recursos.
A realidade: toda query fazia full-table scans por causa da falta de dois índices críticos, o que disparava os requisitos de recursos.
A pista: como a maioria das queries SQL não deveria exigir alto uso de recursos (exceto em processos batch altamente otimizados), um padrão de utilização tão alto apontava oportunidades de otimização.
Investigação: identificamos as queries problemáticas e os índices ausentes com o AWS RDS Performance Optimizer, disponível out-of-the-box no AWS Console. (O GCP tem o equivalente Cloud SQL Query Insights.)
Solução: adicionamos os índices que faltavam.
Resultado: redução de 10x na latência das queries e possibilidade de diminuir o banco em dois tiers.
Cenário 5: job Spark a 70% de CPU por quatro horas toda noite
O que parecia eficiente: o cluster mantinha alta utilização de CPU, sugerindo alocação adequada de recursos.
A realidade: 80% dos dados estavam concentrados em uma única chave enviesada, criando straggler tasks que estendiam o tempo de processamento de forma significativa.
A pista: o problema começou em um momento específico, sem nenhuma outra causa aparente. (Mais tarde descobrimos que isso coincidia com a chegada de novos dados contendo a "hot key".)
Investigação: código Spark roda em um ambiente altamente distribuído, o que dificulta usar um profiler comum, do tipo que se usaria em aplicações tradicionais. Esse é um bom motivo para manter a lógica focada em transformações simples, em vez de regras de negócio complexas. Ainda assim, usar a Spark UI para analisar a distribuição de tasks entre os stages identificou os stragglers. O monitoramento do BigTable revelou "hot keys" no banco que estava sendo processado.
Solução: reparticionamos e aplicamos salting na chave problemática para distribuir o workload de forma mais uniforme.
Resultado: o tempo de execução do job caiu de 4 horas para 45 minutos, e o tamanho necessário do cluster diminuiu em dois terços.
Alcançar eficiência de verdade na nuvem às vezes exige ir além das configurações de infraestrutura e atacar também as ineficiências no nível do código. Quando o código é a causa raiz do excesso de custos na nuvem, ajustes na infraestrutura, sozinhos, não resolvem.
Ao unir seu time de desenvolvimento ao FinOps e ao SRE, dá para identificar e resolver essas ineficiências ocultas com uma abordagem sistemática:
- Comece pelas maiores áreas de despesa apontadas na análise de custos.
- Primeiro, capture as vitórias rápidas no nível da configuração da nuvem.
- Nos Cloud Consoles, fique de olho em pistas que indiquem a necessidade de uma investigação mais profunda.
- Use ferramentas de profiling adequadas, de preferência na nuvem (mas offline, se preciso), para localizar as ineficiências.
- Corrija o código, faça o redeploy e valide os ganhos de custo.
Essa abordagem colaborativa não só reduz custos, como costuma melhorar também a performance e a confiabilidade da aplicação — uma vitória tanto para o seu orçamento quanto para os seus usuários.
No time de Customer Reliability Engineering da DoiT, eu acompanho organizações por toda a jornada de otimização. Com o apoio do DoiT Cloud Intelligence™ e de décadas de experiência, ajudamos a identificar ganhos potenciais, indicar correções no nível da nuvem, desmascarar ilusões de eficiência e validar o impacto das melhorias no nível do código. Entre em contato em doit.com/services