In seinem Artikel " Stop Chasing Idle Servers: Intent-Aware FinOps for the Real World" beschreibt DoiT-CEO Vadim Solovey eine zentrale Realität des Cloud Computing: Eine "Illusion von Effizienz" kann erheblichen Waste verschleiern. Ungenutzte Ressourcen sind leicht zu erkennen – doch einige der teuersten Ineffizienzen verstecken sich in Ihrer Engineering-Organisation oder im Code, also dort, wo eine reine Cloud-Rekonfiguration das Problem nicht löst.
In diesen Hügeln liegt Gold!
Dieser Artikel widmet sich gezielt den Fällen, in denen der Code die Ursache ist. Den Weg von der Cloud-Ebene bis hinunter auf die Code-Ebene zu finden, ist nicht immer einfach. Ich stelle Ihnen dafür eine Methodik vor.
Ein systematischer Ansatz zur Cloud-Kostenoptimierung
Schritt 1: Identifizieren Sie Ihre größten Kostentreiber
Die Cloud-Kostenoptimierung folgt dem Pareto-Prinzip (80/20): Ein kleiner Teil Ihrer Ressourcen verursacht in der Regel den Großteil der Kosten. Beginnen Sie mit Tools wie DoiT Cloud Intelligence™, um Ihre größten Ausgabenblöcke zu identifizieren.
Schritt 2: Schnelle administrative Erfolge mitnehmen
Bevor Sie sich in Code-Optimierungen vertiefen, gehen Sie zunächst die einfacheren administrativen Anpassungen in der Cloud an:
- Right-Sizing unterausgelasteter Instanzen
- Entfernen verwaister Ressourcen
- Einsatz passender Storage-Tiers
- Anpassen der Autoscaling-Parameter
Das ist günstiger, als sich gleich in den Code zu vertiefen.
Schritt 3: Hinweise auf Ineffizienzen auf Code-Ebene erkennen
Sind die administrativen Optimierungen abgeschlossen, prüfen Sie kostenintensive Ressourcen auf mögliche Ineffizienzen, die im Code begründet liegen.
Aufgrund der "Illusion von Effizienz" können diese Hinweise subtil ausfallen. Die weiter unten besprochenen Praxisszenarien zeigen typische verräterische Anzeichen, die sich häufig schon mit den Standard-Monitoring-Tools in den Konsolen von GCP, AWS und Azure aufspüren lassen.
Schritt 4: Untersuchen – profilen und analysieren
Wechseln Sie von der Cloud- auf die Code-Ebene mithilfe von Profiling-Tools, die sich in der Cloud ausführen lassen.
- Für Datenbanken: Query-Analyzer und Performance Insights in der Cloud-Konsole
- Für Anwendungen: sprachspezifische Profiler und Memory-Analyzer
- Für Datenpipelines: Execution Graphs und Verteilungsmetriken
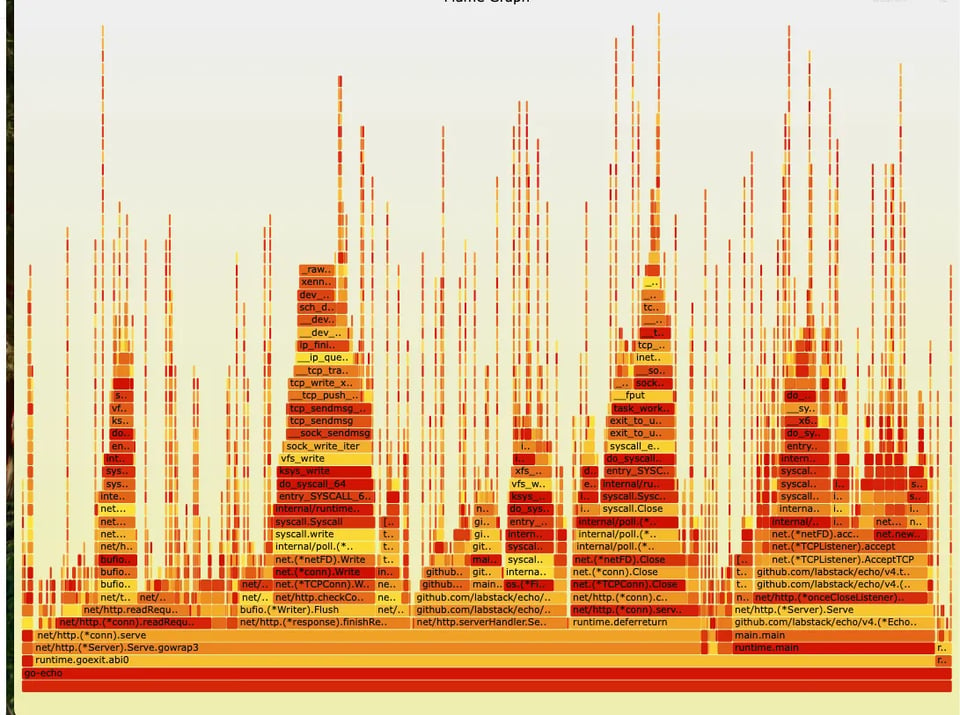 Flame Graph des Google Cloud Profiler
Flame Graph des Google Cloud Profiler
Die Umsetzung kann einfach sein – etwa bei SQL, wo passende Tools direkt in der Cloud bereitstehen – oder schwierig, etwa beim Memory-Profiling von Python in verteilten Anwendungen, die in Managed Environments laufen.
Schritt 5: Umsetzen, messen, validieren
Beheben Sie die identifizierten Probleme, deployen Sie neu und messen Sie die technischen Verbesserungen über die Cloud-Konsolen von AWS, GCP und Azure. Prüfen Sie anschließend die Cost Reports in Cloud Intelligence™, um die Kosteneffekte zu validieren.
Praxisszenarien und Lösungen
Szenario 1: Java-Microservice mit Memory Leaks
Was effizient aussah: Ein Java-Lambda-Microservice mit einer Memory-Auslastung von 70–100 %, der die zugeteilten Ressourcen scheinbar voll ausschöpfte.
Die Realität: Die Anwendung litt unter Memory Leaks: Ein globales Objekt hielt Referenzketten, die Objekte über Invocations hinweg im Speicher festhielten. Vereinzelte Crashes und Instance-Replacements traten zu selten auf, um dem SRE-Team aufzufallen.
Der Hinweis: Das Monitoring zeigte über die Zeit ein sägezahnförmiges Memory-Muster. Die Untersuchung der Einbrüche im Sägezahn führte zu CloudWatch-Logs mit periodischen Crashes.
Untersuchung: Der CodeGuru Profiler wurde aktiviert und legte einen kontinuierlich steigenden Speicherverbrauch offen. Offline-Analysen mit einem JVM-Profiler identifizierten unerwartet zurückgehaltene Objekte.
Lösung: Der Code wurde so angepasst, dass Objektreferenzen am Ende jedes Web-Requests freigegeben werden.
Ergebnis: Stabile Speicherauslastung, weniger Instance-Replacements und niedrigere Ressourcenkosten.
Szenario 2: Java-Datenverarbeitungspipeline mit ineffizienten Datenstrukturen
Was effizient aussah: Eine Dataflow-Pipeline mit eigenen Java-Containern, die täglich Millionen von Datensätzen mit konstant hoher CPU-Auslastung verarbeitete.
Die Realität: Der Code nutzte ineffiziente Datenstrukturen, darunter Maps mit unnötiger String-Konkatenation pro Objekt in engen Schleifen, was übermäßigen Garbage-Collection-Overhead erzeugte.
Der Hinweis: Die hohe Ressourcenauslastung legte eine tiefergehende Untersuchung nahe.
Untersuchung: Der GCP Cloud Profiler wurde dem Container hinzugefügt. Er zeigte ein überlineares Wachstum von Laufzeit und Speicherverbrauch bei größeren Datenmengen.
Lösung:
- Maps wurden durch eigene Objekte ersetzt, die nur die wirklich benötigten Informationen halten.
- Statt wiederholter Konkatenation kam ein sauberes String-Joining zum Einsatz.
Ergebnis: 50 % weniger Speicherverbrauch und 70 % kürzere Verarbeitungszeit – das ermöglichte kleinere Worker-Maschinen und weniger Instanzen.
Szenario 3: In-Memory-Datenstrukturen führen zu überdimensionierten VMs
Was effizient aussah: VMs mit großem Arbeitsspeicher wirkten im Vergleich zu horizontal skalierten Lösungen kosteneffizient, und In-Memory-Datenstrukturen in Python boten algorithmische Geschwindigkeitsvorteile gegenüber Datenbankabfragen.
Die Realität: Dieser Ansatz erzeugte gleich mehrere Ineffizienzen:
- Cloud-Anbieter erzwingen ein Mindestverhältnis von CPU zu Memory – das führt zu teurer, ungenutzter CPU-Kapazität.
- Speicher wird in vordefinierten Stufen zugeteilt, sodass auch ungenutzte Pufferkapazität bezahlt werden muss.
- Lange Initialisierungszeiten machten es nötig, mehrere teure Instanzen für die Ausfallsicherheit dauerhaft parallel laufen zu lassen.
Der Hinweis: DoiT Cloud Intelligence™ zeigte, dass ein großer Anteil der Gesamtkosten auf besonders große VMs entfiel – meist ein Indikator für problematische Statefulness in Cloud-Architekturen.
Untersuchung: Eine tiefergehende Analyse der Algorithmen offenbarte Möglichkeiten zum Refactoring, sodass sich Daten außerhalb des Anwendungsspeichers ablegen ließen.
Lösung:
- Algorithmen wurden so überarbeitet, dass sie mit Teildatensätzen arbeiten, die bei Bedarf aus Datenbanken abgefragt werden.
- Eine NoSQL-Datenbank wurde mit Redis als In-Memory-Cache ergänzt.
- Wo für zentrale Referenzdaten ein vollständiges Preloading nötig war, ermöglichten optimierte Datenstrukturen in Redis einen geringeren Memory-Footprint als die entsprechenden Objekte im Anwendungsspeicher.
Ergebnis: Diese architektonische Anpassung verkleinerte die VMs deutlich, ermöglichte horizontale Skalierung und senkte die Kosten radikal – erforderte allerdings einen erheblichen Engineering-Aufwand.
Ein Blick auf frühere Fälle
Werfen wir noch einen Blick auf zwei weitere Beispiele aus dem eingangs erwähnten Artikel " Stop Chasing Idle Servers" und schauen, wie sie sich in dieses Framework einordnen.
Szenario 4: Datenbank an 85 % IOPS
Was effizient aussah: Die RDS-Instanz schien voll ausgelastet, was auf eine optimale Ressourcenzuteilung hindeutete.
Die Realität: Wegen zweier fehlender, kritischer Indizes führte jede Abfrage einen Full Table Scan durch, was den Ressourcenbedarf dramatisch erhöhte.
Der Hinweis: Da die meisten SQL-Queries keine hohe Ressourcenauslastung erfordern sollten (außer in stark optimierten Batch-Prozessen), deutete eine dauerhaft hohe Auslastung auf Optimierungspotenzial hin.
Untersuchung: Mit dem AWS RDS Performance Optimizer, der out of the box in der AWS-Konsole verfügbar ist, wurden problematische Queries und fehlende Indizes identifiziert. (GCP bietet mit Cloud SQL Query Insights ein vergleichbares Werkzeug.)
Lösung: Die fehlenden Indizes wurden ergänzt.
Ergebnis: Eine 10-fache Reduktion der Query-Latenz und die Möglichkeit, die Datenbank um zwei Größenstufen zu verkleinern.
Szenario 5: Spark-Job bei 70 % CPU – vier Stunden pro Nacht
Was effizient aussah: Der Cluster hielt eine konstant hohe CPU-Auslastung, was auf eine angemessene Ressourcenzuteilung hindeutete.
Die Realität: 80 % der Daten konzentrierten sich auf einen einzigen verzerrten Key. Die daraus entstehenden Straggler-Tasks verlängerten die Verarbeitungszeit erheblich.
Der Hinweis: Das Problem trat zu einem bestimmten Zeitpunkt ohne erkennbare andere Ursache auf. (Wie sich später herausstellte, fiel dies mit dem Eintreffen neuer Daten mit dem "Hot Key" zusammen.)
Untersuchung: Spark-Code läuft in einer hochgradig verteilten Umgebung, was den Einsatz eines klassischen Profilers, wie man ihn für Anwendungen verwenden würde, erschwert. Genau deshalb sollte sich die Logik auf einfache Transformationen konzentrieren statt auf komplexe Geschäftslogik. Über die Spark-UI ließ sich jedoch die Task-Verteilung über die Stages analysieren und Straggler identifizieren. Das BigTable-Monitoring deckte zudem "Hot Keys" in der verarbeiteten Datenbank auf.
Lösung: Der problematische Key wurde repartitioniert und gesalzen, um die workloads gleichmäßiger zu verteilen.
Ergebnis: Die Job-Laufzeit sank von 4 Stunden auf 45 Minuten, und die benötigte Cluster-Größe ließ sich um zwei Drittel reduzieren.
Echte Cloud-Effizienz erfordert manchmal mehr als nur Cloud-Konfigurationen – nämlich auch das Beheben von Ineffizienzen auf Code-Ebene. Liegt die Ursache überhöhter Cloud-Kosten im Code, helfen reine Infrastruktur-Anpassungen nicht weiter.
Wenn Ihr Entwicklungsteam eng mit FinOps und SRE zusammenarbeitet, lassen sich diese versteckten Ineffizienzen mit einem systematischen Vorgehen identifizieren und beheben:
- Beginnen Sie bei den größten Ausgabenbereichen, die Ihre Cost Analytics ausweist.
- Heben Sie zunächst die Quick Wins auf der Ebene der Cloud-Konfiguration.
- Achten Sie in den Cloud-Konsolen auf verräterische Hinweise, die eine tiefergehende Analyse nahelegen.
- Nutzen Sie passende Profiling-Tools – idealerweise in der Cloud, bei Bedarf offline – um Ineffizienzen punktgenau aufzuspüren.
- Korrigieren Sie den Code, deployen Sie neu und validieren Sie die Kosteneffekte.
Dieser kollaborative Ansatz senkt nicht nur die Kosten, sondern verbessert oft auch Performance und Zuverlässigkeit Ihrer Anwendungen – ein Gewinn für Ihr Budget und Ihre Nutzer.
Im Customer Reliability Engineering Team von DoiT begleite ich Unternehmen über den gesamten Optimierungsweg. Mit DoiT Cloud Intelligence™ und jahrzehntelanger Erfahrung im Rücken helfen wir, Potenziale zu erkennen, Fixes auf Cloud-Ebene zu beschreiben, Effizienz-Illusionen aufzudecken und den Effekt von Code-Verbesserungen zu validieren. Sprechen Sie uns an unter doit.com/services.