
著者: Vadim Solovey、Google Developer Expert。
先日、Pavloら著「 A Comparison of Approaches to Large-Scale Data Analysis」(SIGMOD 2009) に基づく、ビッグデータ基盤の興味深いベンチマークに出会いました。バークレー大学のAPMLabチームは、この方法論をもとに、誰でもパブリッククラウド (今回はAWS) 上でベンチマークを実行できるオープンソースソフトウェアを開発しています。
このベンチマークは、スキャン・集約・結合といったリレーショナルクエリのレスポンスタイムを、さまざまなデータサイズで計測するものです。Amazon Redshift、Hive、Shark、Impala、Stinger/Tez を比較した結果は、専用サイトに詳しくまとめられています。
私自身、Google BigQueryに関わる時間が多いこともあり、まったく同じデータセットでBigQueryが他ソリューションとどこまで戦えるのか、強い興味を持ちました。BigQueryは共有サービスであり、顧客側でデプロイ・運用する専用ソリューションとは性質が大きく異なります。
とはいえ、その性質を踏まえてもなお、結果は (個人的にですが) 非常に意外なものでした。
データセット
このベンチマークでは、tiny、1node、5nodes の3種類のデータサイズが用意されています。最大の 5nodes は、9,000万件のレコードを持つ「rankings」テーブルと、7億7,500万件のレコードを持つ「uservisits」テーブルで構成されています。データはIntelのHadoopベンチマークツールで生成されたもので、s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix] から取得できます。今回はCSV形式のテキスト版を使ったため、BigQueryへの読み込みも非常にスムーズでした。
テーブルは大きく分けて2つあり、スキーマは以下のとおりです。
Ranking テーブルのスキーマ:
(ウェブサイトとそのページランクを格納)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Uservisits テーブルのスキーマ:
(各ウェブページのサーバーログを格納)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
workloads
改めてになりますが、このベンチマークでは スキャン、集約、結合 というリレーショナルクエリのレスポンスタイムを測定します。クエリ結果の中には128MBを超え、クォータポリシーに抵触するものもあります。そこで allowLargeResults をtrueにし、結果を宛先テーブルへ保存することで回避しました。
もう一点、GROUP BYとJOINには EACH 修飾子を使っています。データセットが大きく、カーディナリティの高い集約や結合を行う場合には、この指定が必要です。
1. スキャンクエリ
このクエリにはXが1000、100、10の3パターンがあります。
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. 集約クエリ
このクエリにはXが8、10、12の3パターンがあります。
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. 結合クエリ
他のクエリと同じく、こちらにも3パターンがあり、Xはそれぞれ「1980–04–01」、「1983–01–01」、「2010–01–01」です。
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. 外部スクリプトクエリ
オリジナルのベンチマークではUDF (ユーザー定義関数) の性能も測定対象になっています。現時点ではBigQueryはUDFをサポートしていませんが、近い将来サポートされる可能性があり、対応され次第UDFの結果も追加してベンチマークを更新する予定です。
結果
BigQueryは共有型サービスである以上、クエリのレイテンシに散発的なスパイクが出ることは想定されます。そこで各クエリを1時間に1回ずつ計10回実行し、レスポンスタイムの中央値 (秒) を結果としました。
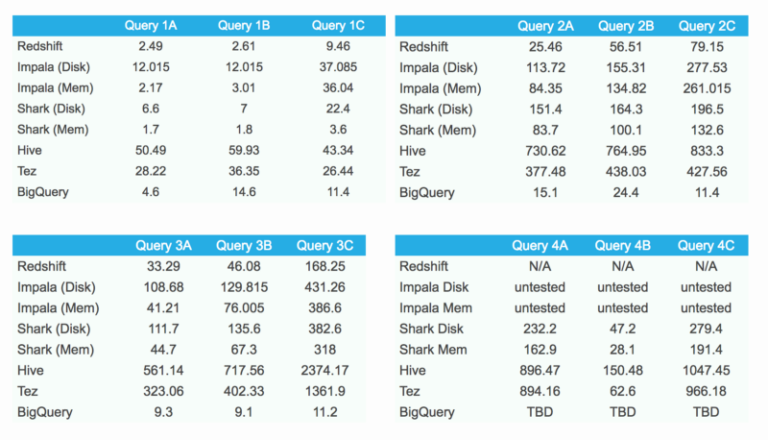
ベンチマーク結果
結果を見ると、BigQueryは集約 (クエリ2A、2B、2C) と結合 (クエリ3A、3B、3C) で真価を発揮していることがわかります。これら2種のクエリでは、BigQueryが他を抑えてトップに立っています。
1つ目のクエリも十分に高速ですが、結果サイズの制約から一時テーブルへ保存する必要があり、本来の性能を出し切れていません。
それでも、BigQueryはメンテナンス不要・セットアップ不要・従量課金制でありながら、優れた性能を備えたビッグデータソリューションです。次のビッグデータ案件では、ぜひ選択肢のひとつに加えてみてください。
初出: www.doit.com 2015年6月9日。