
Von Vadim Solovey, Google Developer Expert.
Vor Kurzem bin ich auf einen interessanten Benchmark von BigData-Systemen gestoßen, der auf "A Comparison of Approaches to Large-Scale Data Analysis" von Pavlo et al. (SIGMOD 2009) basiert. Auf Basis dieser Methodik hat das APMLab-Team der Berkeley University eine Open-Source-Software entwickelt, mit der sich der Benchmark in der Public Cloud (hier AWS) ausführen lässt.
Der Benchmark misst die Antwortzeit bei einer Reihe relationaler Queries: Scans, Aggregationen und Joins über verschiedene Datenmengen hinweg. Auf einer sehenswerten Website sind die Ergebnisse für Amazon Redshift, Hive, Shark, Impala und Stinger/Tez dokumentiert.
Da ich beruflich viel mit Google BigQuery arbeite, hat mich die Frage gereizt, wie sich BigQuery im direkten Vergleich auf exakt demselben Datensatz schlägt. Klar ist: BigQuery tickt grundsätzlich anders, denn es ist ein Shared Service und keine dedizierte, vom Kunden bereitgestellte (und gewartete) Lösung.
Trotz dieser Eigenheit sind die Ergebnisse – meiner Meinung nach – ausgesprochen überraschend.
Der Datensatz
Der Benchmark stellt drei Datensatzgrößen zur Auswahl: tiny, 1node und 5nodes. Der größte Datensatz 5nodes umfasst die Tabelle 'rankings' mit 90 Millionen Datensätzen und die Tabelle 'uservisits' mit 775 Millionen Datensätzen. Die Daten werden mit den Hadoop-Benchmark-Tools von Intel erzeugt und stehen unter s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix] bereit. Ich habe die Textversion im CSV-Format genutzt, die sich problemlos in BigQuery laden lässt.
Es gibt zwei Tabellen mit folgenden Schemata:
Schema der Tabelle Ranking:
(Listet Websites und ihren Page Rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Schema der Tabelle Uservisits:
(Speichert Server-Logs für jede Webseite)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
Der Workload
Wie erwähnt misst der Benchmark die Antwortzeit bei einer Reihe relationaler Queries: Scans, Aggregationen und Joins. Einige Ergebnisse sind größer als 128 MB und überschreiten damit die Quota Policy. Als Workaround habe ich eine Zieltabelle für die Ergebnisse genutzt und allowLargeResults auf true gesetzt.
Eine weitere Anmerkung gilt dem EACH-Modifier bei GROUP BY- und JOIN-Operatoren. Er ist nötig, wenn der Datensatz groß ist und eine Aggregation oder ein Join mit hoher Kardinalität anliegt.
1. Scan Query
Diese Query gibt es in drei Varianten – X = 1000, X = 100 und X = 10:
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Aggregation Query
Auch hier drei Varianten – X = 8, X = 10 und X = 12:
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. Join Query
Wie bei den anderen Queries gibt es drei Varianten: X = '1980–04–01', X = '1983–01–01' und X = '2010–01–01':
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. External Script Query
Der ursprüngliche Benchmark misst auch die Performance von UDFs (User Defined Functions). BigQuery unterstützt UDFs derzeit nicht, das kann sich aber bald ändern. Sobald es so weit ist, ergänze ich den Benchmark um die UDF-Ergebnisse.
Die Ergebnisse
Da BigQuery als Shared Service betrieben wird, sind gelegentliche Latenzspitzen zu erwarten. Deshalb habe ich jede Query 10-mal ausgeführt (einmal pro Stunde); die Werte sind die mediane Antwortzeit (in Sekunden).
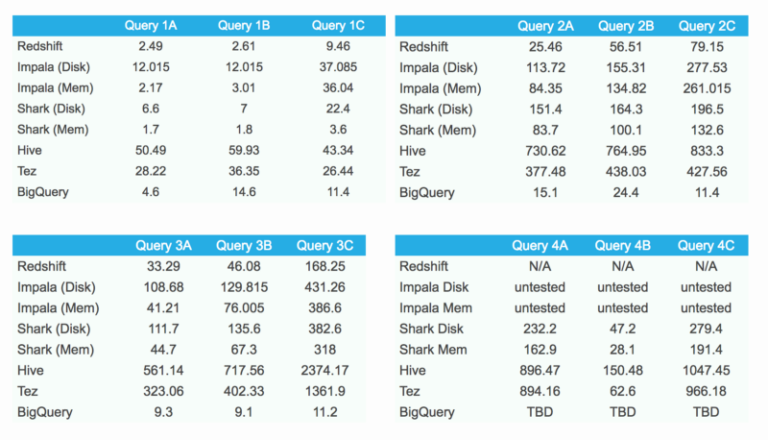
Benchmark-Ergebnisse
Die Zahlen sprechen eine klare Sprache: BigQuery glänzt vor allem bei Aggregationen (Queries 2A, 2B und 2C) und Joins (Queries 3A, 3B und 3C). In diesen beiden Disziplinen liegt BigQuery vor allen Mitbewerbern auf Platz eins.
Auch die erste Query läuft schnell, doch wegen der Begrenzung der Ergebnisgröße – und der damit verbundenen Zwischenspeicherung in einer temporären Tabelle – schöpft sie ihr Potenzial nicht voll aus.
Unterm Strich ist BigQuery eine wartungsfreie BigData-Lösung ohne Setup-Aufwand und mit nutzungsbasierter Abrechnung – bei beeindruckender Performance. Es lohnt sich, sie für die nächste Big-Data-Aufgabe in Betracht zu ziehen.
Ursprünglich veröffentlicht auf www.doit.com am 9. Juni 2015.