
Por Vadim Solovey, Google Developer Expert.
Recentemente, me deparei com um benchmark interessante de sistemas BigData baseado em "A Comparison of Approaches to Large-Scale Data Analysis", de Pavlo et al. (SIGMOD 2009). A partir dessa metodologia, o pessoal do APMLab, da Universidade de Berkeley, desenvolveu um software open source que permite a qualquer pessoa rodar esse benchmark em nuvem pública (no caso, a AWS).
O benchmark mede o tempo de resposta em algumas consultas relacionais: scans, agregações e joins, em diferentes volumes de dados. Eles mantêm um site bem caprichado com os resultados, comparando Amazon Redshift, Hive, Shark, Impala e Stinger/Tez.
Como passo boa parte do meu tempo trabalhando com o Google BigQuery, fiquei curioso para ver como ele se sairia frente a outras soluções, usando exatamente o mesmo dataset. Vale lembrar que o BigQuery tem uma natureza bem diferente: é um serviço compartilhado, e não uma solução dedicada, implantada (e mantida) pelo cliente.
Mesmo assim, os resultados foram bastante surpreendentes (na minha humilde opinião).
O dataset
O benchmark oferece 3 tamanhos de dataset — tiny, 1node e 5nodes. O maior deles é o 5nodes, com a tabela 'rankings' contendo 90 milhões de registros e a 'uservisits' com 775 milhões. Os dados são gerados pelas ferramentas de benchmark Hadoop da Intel e ficam disponíveis em s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix]. Usei a versão em texto, que está em CSV, o que facilita bastante o carregamento no BigQuery.
De modo geral, há duas tabelas com os seguintes schemas:
Schema da tabela Ranking:
(Lista sites e seu page rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Schema da tabela Uservisits:
(Armazena logs de servidor de cada página)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
O workload
Reforçando: o benchmark mede o tempo de resposta em algumas consultas relacionais — scans, agregações e joins. Alguns resultados ultrapassam 128MB e violam a política de cotas. Para contornar isso, usei uma tabela de destino para armazenar os resultados, com allowLargeResults definido como true.
Outra observação é sobre o uso do modificador EACH nos operadores GROUP BY e JOIN. Ele é necessário quando o dataset é grande e há agregações ou joins de alta cardinalidade.
1. Scan Query
Esta consulta tem 3 variações: X igual a 1000, 100 e 10:
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Aggregation Query
Esta consulta tem 3 variações: X igual a 8, 10 e 12:
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. Join Query
Assim como as anteriores, esta também tem 3 variações: X igual a '1980–04–01', '1983–01–01' e '2010–01–01':
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. External Script Query
O benchmark original também mede a performance de UDFs (user defined functions). No momento, o BigQuery não dá suporte a UDFs, mas isso pode mudar em breve. Quando mudar, vou atualizar o benchmark com os resultados.
Os resultados
Picos ocasionais de latência são esperados no BigQuery por causa da sua natureza compartilhada. Por isso, executei cada consulta 10 vezes (uma a cada hora) e os resultados representam a mediana do tempo de resposta (em segundos).
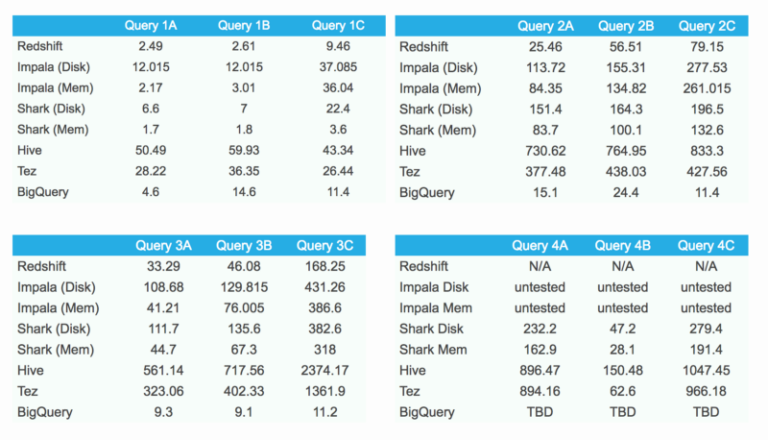
Resultados do benchmark
Olhando para os números, fica claro que o BigQuery brilha mesmo em agregações (consultas 2A, 2B e 2C) e joins (consultas 3A, 3B e 3C). Nessas duas categorias, ele fica em 1º lugar entre os concorrentes.
A primeira consulta também é bastante rápida, mas, por conta do limite de tamanho do resultado — e da consequente necessidade de gravar os dados em uma tabela temporária —, a performance não é tão alta quanto poderia ser.
Ainda assim, o BigQuery é uma solução de BigData sem manutenção, sem setup e no modelo pay-as-you-go, com uma performance excelente. Vale a pena dar uma olhada e considerá-lo no seu próximo desafio de big data.
Publicado originalmente em www.doit.com em 09/06/2015.