
Di Vadim Solovey, Google Developer Expert.
Di recente mi sono imbattuto in un interessante benchmark per sistemi BigData ispirato a "A Comparison of Approaches to Large-Scale Data Analysis" di Pavlo et al. (SIGMOD 2009). A partire da quella metodologia, il team di APMLab della Berkeley University ha sviluppato un software open-source che consente a chiunque di eseguire il benchmark sul cloud pubblico (in questo caso AWS).
Il benchmark misura il tempo di risposta di una manciata di query relazionali: scan, aggregazioni e join su dataset di dimensioni diverse. Il team ha pubblicato un sito molto curato con i risultati, mettendo a confronto Amazon Redshift, Hive, Shark, Impala e Stinger/Tez.
Dato che dedico gran parte del mio tempo a Google BigQuery, ero curioso di vedere come si sarebbe comportato a parità di dataset rispetto alle altre soluzioni. Va detto che BigQuery ha una natura ben diversa, trattandosi di un servizio condiviso e non di una soluzione dedicata, distribuita e gestita dal cliente.
Nonostante questo, i risultati sono — a mio modesto parere — davvero sorprendenti.
Il dataset
Il benchmark prevede 3 dimensioni di dataset — tiny, 1node e 5nodes. Il più grande è 5nodes, che comprende la tabella 'rankings' con 90 milioni di record e la tabella 'uservisits' con 775 milioni di record. I dati sono generati con gli strumenti di benchmark Hadoop di Intel e sono disponibili all'indirizzo s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix]. Ho usato la versione text dei dati, in formato CSV, così da caricarli facilmente in BigQuery.
In generale ci sono due tabelle, con i seguenti schemi:
Schema della tabella Ranking:
(elenca i siti web e il loro page rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Schema della tabella Uservisits:
(conserva i log del server per ogni pagina web)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
Il workload
Come anticipato, il benchmark misura il tempo di risposta di una manciata di query relazionali: scan, aggregazioni e join. Alcuni risultati superano i 128MB e violano la quota policy. Per aggirare il limite ho usato una tabella di destinazione in cui salvare i risultati, impostando allowLargeResults a true.
Un'altra nota riguarda l'uso del modificatore EACH per gli operatori GROUP BY e JOIN: è necessario quando il dataset è di grandi dimensioni e si tratta di un'aggregazione o di un join ad alta cardinalità.
1. Scan Query
Questa query ha 3 varianti: con X pari a 1000, 100 e infine 10:
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Aggregation Query
Questa query ha 3 varianti: con X pari a 8, 10 e infine 12:
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. Join Query
Come le precedenti, anche questa ha 3 varianti: X è '1980–04–01', '1983–01–01' e '2010–01–01':
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. External Script Query
Il benchmark originale misura anche le prestazioni delle UDF (user defined functions). Ad oggi BigQuery non supporta le UDF, ma la situazione potrebbe cambiare presto: quando accadrà aggiornerò il benchmark con i relativi risultati.
I risultati
Con BigQuery sono prevedibili picchi occasionali di latenza, data la sua natura condivisa: per questo ho eseguito ogni query 10 volte (una all'ora) e i valori riportati sono il tempo di risposta mediano (in secondi).
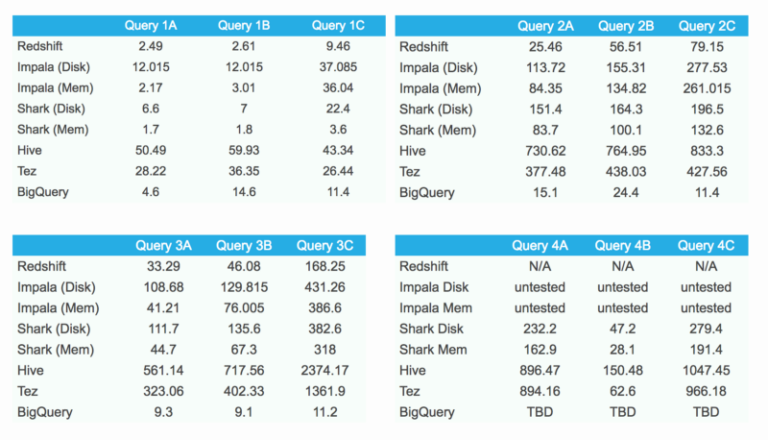
Risultati del benchmark
Dai dati emerge chiaramente che BigQuery dà il meglio di sé con le aggregazioni (query 2A, 2B e 2C) e con i join (query 3A, 3B e 3C). In queste due categorie BigQuery si piazza al primo posto tra i concorrenti.
Anche la prima query è piuttosto rapida; tuttavia, a causa del limite sulla dimensione del risultato e della conseguente necessità di salvare i dati in una tabella temporanea, le prestazioni non esprimono tutto il loro potenziale.
Detto questo, BigQuery è una soluzione BigData senza manutenzione, senza setup e pay-as-you-go, con prestazioni eccellenti. Le consiglio di provarla e di valutarla per la sua prossima sfida big data.
Pubblicato originariamente su www.doit.com il 9 giugno 2015.