
Par Vadim Solovey, Google Developer Expert.
Je suis récemment tombé sur un benchmark intéressant de systèmes BigData inspiré de A Comparison of Approaches to Large-Scale Data Analysis de Pavlo et al. (SIGMOD 2009). À partir de cette méthodologie, l'équipe de l'APMLab de l'université de Berkeley a développé un logiciel open-source qui permet à chacun d'exécuter ce benchmark sur un cloud public (AWS en l'occurrence).
Ce benchmark mesure le temps de réponse sur quelques requêtes relationnelles : scans, agrégations et jointures sur différentes volumétries de données. L'équipe propose un site remarquable présentant les résultats, qui comparent Amazon Redshift, Hive, Shark, Impala et Stinger/Tez.
Comme je consacre une grande partie de mon temps à Google BigQuery, j'étais curieux de voir comment il se positionnerait face aux autres solutions sur exactement le même jeu de données. BigQuery a évidemment une nature très différente puisqu'il s'agit d'un service partagé, et non d'une solution dédiée déployée (et maintenue) par le client.
Malgré cette spécificité de Google BigQuery, les résultats sont extrêmement surprenants (à mon humble avis).
Le jeu de données
Le benchmark propose 3 tailles de jeux de données : tiny, 1node et 5nodes. Le plus volumineux est 5nodes, qui contient une table rankings de 90 millions d'enregistrements et une table uservisits de 775 millions d'enregistrements. Les données sont générées à l'aide des outils de benchmark Hadoop d'Intel. Elles sont disponibles à l'adresse s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix]. J'ai utilisé la version texte au format CSV, ce qui rend le chargement dans BigQuery très simple.
De manière générale, il y a deux tables avec les schémas suivants :
Schéma de la table Ranking :
(Liste les sites web et leur page rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Schéma de la table Uservisits :
(Stocke les logs serveur de chaque page web)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
Les workloads
Pour rappel, le benchmark mesure le temps de réponse sur quelques requêtes relationnelles : scans, agrégations et jointures. Certains résultats dépassent 128 Mo et enfreignent la politique de quotas. Pour contourner cela, j'ai utilisé une table de destination pour stocker les résultats, en passant allowLargeResults à true.
Autre remarque : l'usage du modificateur EACH pour les opérateurs GROUP BY et JOIN. Il est nécessaire dès que le jeu de données est volumineux et que l'agrégation ou la jointure présente une cardinalité élevée.
1. Requête de scan
Cette requête comporte 3 variantes, avec X égal à 1000, 100 puis 10 :
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Requête d'agrégation
Cette requête comporte 3 variantes, avec X égal à 8, 10 puis 12 :
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. Requête de jointure
Comme les requêtes précédentes, celle-ci comporte également 3 variantes : X = '1980–04–01', X = '1983–01–01' et X = '2010–01–01' :
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. Requête avec script externe
Le benchmark original évalue aussi les performances des UDF (fonctions définies par l'utilisateur). À ce jour, BigQuery ne prend pas en charge les UDF, mais cela pourrait évoluer prochainement. Le cas échéant, j'enrichirai le benchmark avec les résultats correspondants.
Les résultats
Des pics ponctuels de latence sont à prévoir avec BigQuery du fait de sa nature partagée. J'ai donc exécuté chaque requête 10 fois (une fois par heure) ; les résultats correspondent à la médiane des temps de réponse (en secondes).
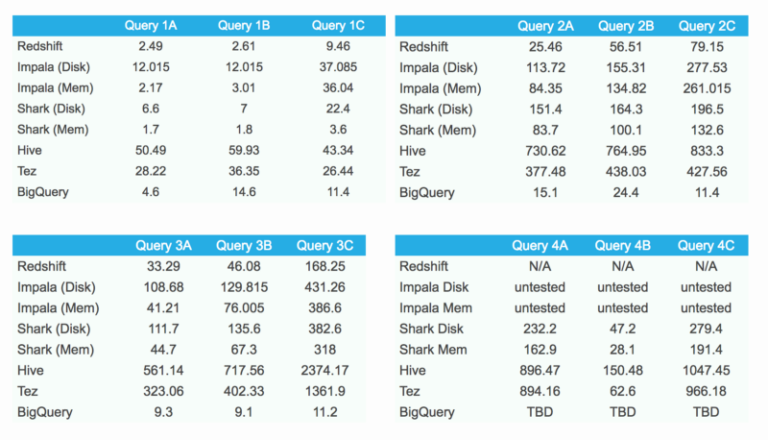
Résultats du benchmark
À la lecture des résultats, il est clair que BigQuery excelle sur les agrégations (requêtes 2A, 2B et 2C) et les jointures (requêtes 3A, 3B et 3C). Sur ces deux familles de requêtes, BigQuery décroche la première place face à ses concurrents.
La première requête est également assez rapide, mais en raison de la limitation sur la taille des résultats — et donc de la nécessité de les stocker dans une table temporaire — les performances n'atteignent pas leur plein potentiel.
BigQuery reste néanmoins une solution BigData sans maintenance, sans configuration et en pay-as-you-go, dotée de performances remarquables. Je vous invite à y jeter un œil et à l'envisager pour votre prochain défi big data.
Article initialement publié sur www.doit.com le 9 juin 2015.