
Por Vadim Solovey, Google Developer Expert.
Hace poco me crucé con un benchmark interesante de sistemas BigData basado en " A Comparison of Approaches to Large-Scale Data Analysis" de Pavlo et al. (SIGMOD 2009). Tomando esa metodología como base, el equipo de APMLab de la Universidad de Berkeley desarrolló un software open-source que permite a cualquiera correr este benchmark sobre una nube pública (en este caso, AWS).
El benchmark mide el tiempo de respuesta de un puñado de consultas relacionales: scans, agregaciones y joins sobre distintos tamaños de datos. Tienen un sitio impresionante con los resultados, donde se comparan Amazon Redshift, Hive, Shark, Impala y Stinger/Tez.
Como dedico buena parte de mi tiempo a trabajar con Google BigQuery, me dio curiosidad ver cómo se desempeñaba frente a otras soluciones usando exactamente el mismo dataset. Está claro que BigQuery tiene una naturaleza muy distinta: es un servicio compartido y no una solución dedicada, desplegada (y mantenida) por el cliente.
A pesar de esa diferencia, los resultados son sumamente sorprendentes (en mi humilde opinión).
El dataset
El benchmark contempla 3 tamaños de datasets: tiny, 1node y 5nodes. El más grande es 5nodes, que tiene una tabla 'rankings' con 90 millones de registros y una tabla 'uservisits' con 775 millones de registros. Los datos se generan con las herramientas de benchmark de Hadoop de Intel y están disponibles en s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix]. Yo usé la versión text, que está en formato CSV, así que se carga en BigQuery sin complicaciones.
En términos generales, hay dos tablas con los siguientes esquemas:
Esquema de la tabla Ranking:
(Lista los sitios web y su page rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Esquema de la tabla Uservisits:
(Guarda los logs del servidor para cada página web)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
El workload
Entonces, repasando: el benchmark mide el tiempo de respuesta de un puñado de consultas relacionales: scans, agregaciones y joins. Algunos resultados pesan más de 128MB y se pasan de la política de cuotas. Para resolverlo, utilicé una tabla de destino donde almacenar los resultados, configurando allowLargeResults en true.
Otro punto a tener en cuenta es el uso del modificador EACH en los operadores GROUP BY y JOIN. Hace falta cuando el dataset es grande y la agregación o el join tienen alta cardinalidad.
1. Consulta de Scan
Esta consulta tiene 3 variantes: con X igual a 1000, 100 y 10:
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Consulta de Agregación
Esta consulta tiene 3 variantes: con X igual a 8, 10 y 12:
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP3. Consulta de Join
Al igual que las anteriores, también tiene 3 variantes: X igual a '1980–04–01', '1983–01–01' y '2010–01–01':
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 14. Consulta con script externo
El benchmark original también mide el rendimiento de las UDF (funciones definidas por el usuario). Al día de hoy, BigQuery no soporta UDF, pero eso podría cambiar pronto y, cuando ocurra, actualizaré el benchmark con esos resultados.
Los resultados
Es esperable que de tanto en tanto haya picos de latencia en BigQuery por su naturaleza compartida, así que corrí cada consulta 10 veces (una por hora) y los resultados muestran la mediana del tiempo de respuesta (en segundos).
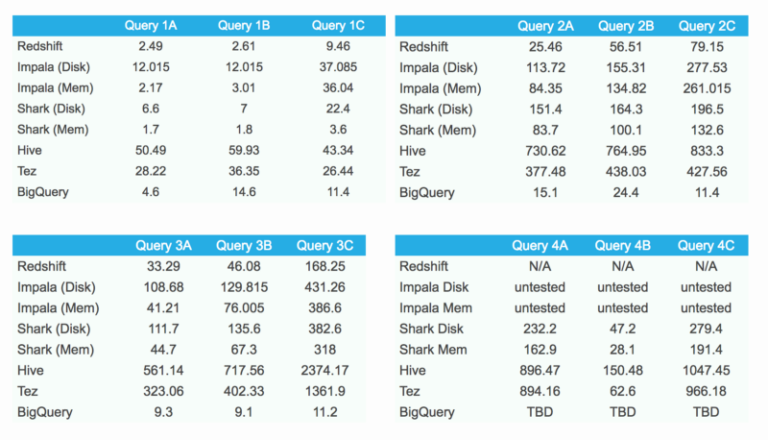
Resultados del benchmark
Mirando los números, queda claro que BigQuery brilla con las agregaciones (consultas 2A, 2B y 2C) y los joins (consultas 3A, 3B y 3C). En estas dos categorías, BigQuery se lleva el primer lugar frente a sus rivales.
La primera consulta también es bastante rápida, aunque por el límite en el tamaño del resultado y la necesidad de guardarlo en una tabla temporal, el rendimiento no llega a ser todo lo bueno que podría.
Aun así, BigQuery es una solución BigData sin mantenimiento, sin setup y de pago por uso, con un rendimiento excelente. Te recomiendo darle una mirada y tenerlo en cuenta para tu próximo desafío de big data.
Publicado originalmente en www.doit.com el 9 de junio de 2015.