[前回の記事](https://www.doit.com/blog/instant-on-scaling-eliminating-node-provisioning-delays-in-gke-with-active-buffer)では、Kubernetes運用で最も悩ましい課題の一つであるノードプロビジョニングの遅延を、GKEの[Active Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer)がどう解決するかを取り上げました。[`CapacityBuffer`](https://docs.cloud.google.com/kubernetes-engine/docs/reference/crds/capacitybuffer)リソースを宣言するだけで、Active Bufferは事前にウォームアップしたノードを待機させ、トラフィックの急増を瞬時に吸収します。数分単位のコールドスタートも、バルーンPodも、`PriorityClass`を駆使した職人芸も、もう必要ありません。
とはいえ、オンデマンドのノードをアイドル状態で稼働させ続けるアーキテクチャである以上、コストは避けられません。クラスタ全体をやみくもに過剰プロビジョニングするよりは安く済むものの、仮想マシンを24時間365日立ち上げておくにはそれなりの料金がかかります。たとえば50 CPU・50 GiBメモリ分のセーフティネットを確保する場合、アイドル状態のノードに対してフル料金を払い続けることになります。
この問題への答えとしてGoogleが2026年6月にリリースしたのが、**[Standby Buffers](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#standby_buffer)**です。`CapacityBuffer` APIに追加された新しい`provisioningStrategy`で、GKEがノードを事前にプロビジョニングして完全に初期化したうえで、サスペンド状態に置けるようになりました。GKEバージョン`1.36.0-gke.2253000`以降で利用でき、予測しづらいワークロードに対して1秒未満のスケジューリングを実現しつつ、フル過剰プロビジョニングと比べてアイドルインフラのコストを最大90%削減できます。
> **注:** Standby Buffersは現在**プレビュー**段階で、「Pre-GA Offerings Terms」が適用されます。本番環境で利用する前に、必ず[要件と制限事項](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations)をご確認ください。
## 進化のかたち:Active BufferとStandby Bufferの違い
Standby Buffersの価値を理解するには、それぞれの戦略がコンピュートインフラをどう扱うかを比べてみるのが近道です。
**Active Buffer(`buffer.x-k8s.io/active-capacity`):** GKEは保留中の需要を表す軽量なプレースホルダPodを作成します。Cluster Autoscalerがこれを検知して、実際に稼働するVMをプロビジョニングします。ノードは起動し、DaemonSetが読み込まれ、インスタンスはフル課金で動作します。実際のワークロードPodがスケールアップすると、このウォームな容量を即座に引き継ぎます。
**Standby Buffer(`buffer.gke.io/standby-capacity`):** GKEはノードをプロビジョニングして完全に初期化(DaemonSetの起動やコンテナイメージのプリロード時間の確保)を済ませたうえで、**背後のコンピュートインスタンスをサスペンド**します。OSの状態はディスクに保持され、コンピュートとメモリの課金は止まり、永続ディスクとIPアドレスの料金だけが発生します。需要が急増したときには、これらサスペンド済みノードが新規VMをゼロから立ち上げる場合に比べて**2〜3倍速く**復帰します。OSとKubernetesのブートストラップ処理がすでに終わっているからです。
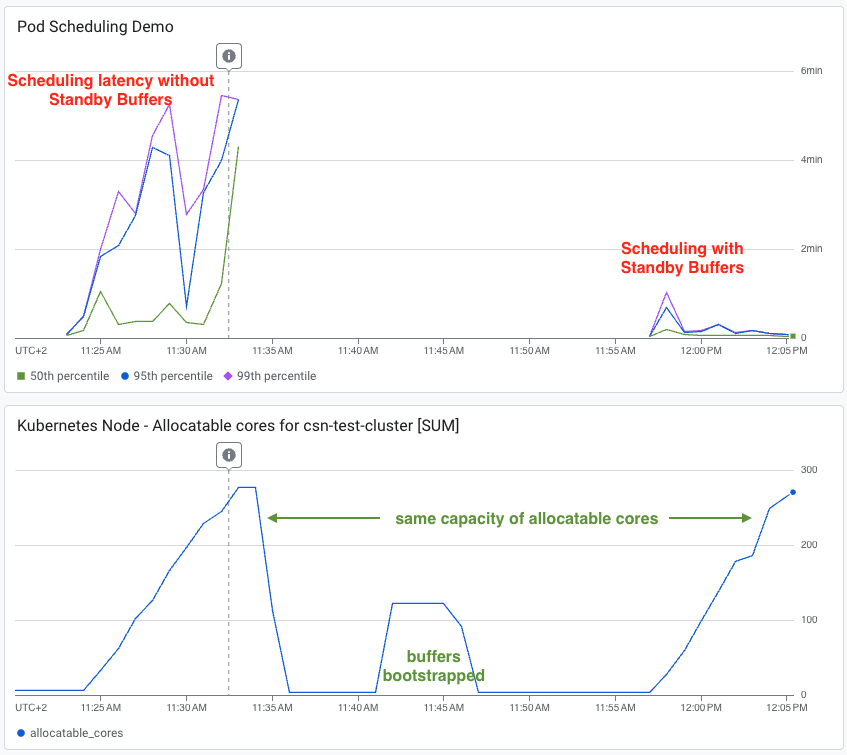
**ベンチマーク結果:** Googleが公開した[初期ベンチマーク](https://cloud.google.com/blog/products/containers-kubernetes/gke-standby-buffers-speed-up-autoscaling-for-less-spend)によると、Standby Buffersを使ったクラスタは、AI Agent Sandboxのような動的ワークロードに対して1秒未満のスケジューリングレイテンシを実現し、従来の過剰プロビジョニングと比べてコストを最大90%削減しました。

同一のトラフィック負荷でのレイテンシテストでは、バッファなしのクラスタはP95・P99のスケジューリングレイテンシが4〜6分の間で高止まりしていました。一方、Standby Buffersを使ったクラスタはP50を1桁秒に抑え、P95・P99は一時的に1分まで上がったものの、その後完全に正常値へ戻っています。
## 適切なバッファ戦略の選び方
Podスケジューリングレイテンシを極限まで下げたいアプリケーションであれば、Standby Buffersだけに頼るのは得策ではありません。サスペンド済みノードの復帰は速い(コールドスタートの数分に対しておよそ30秒)とはいえ、突発的かつ予測不能なスパイクに対しては、それでも短いレイテンシが発生します。
理想的なアーキテクチャは、2層構成のハイブリッドバッファです。
1. **Active Buffer(ショックアブソーバー):** 容量を予約済みで完全に稼働中の小規模なノードプールが、1秒未満のスケジューリングレイテンシで突発的なスパイクを吸収します。
2. **Standby Buffer(深い貯水池):** 大規模なサスペンド済みノードプールが約30秒で復帰し、長く続くトラフィックサージをカバーします。Active Bufferのユニットが消費されていくと、Standbyノードが目を覚ましてActive層を補充します。
```text
[ Incoming Traffic Spike ]
│
▼
┌──────────────────────────────────────┐
│ Tier 1: Active Buffer (Instant) │ ──► Absorbs immediate surge
└──────────────────────────────────────┘
│ (As Tier 1 depletes...)
▼
┌──────────────────────────────────────┐
│ Tier 2: Standby Buffer (~30s Wake) │ ──► Wakes up to cover extended traffic surge
└──────────────────────────────────────┘
```
**サイジングの考え方:** Active Bufferは小さく安価に保ち、Standbyノードが起き上がるまでの30秒のギャップを埋められる最小限のサイズにとどめます。Standby Bufferは、長く続くトラフィックピーク全体をカバーできる十分な大きさを確保します。
## 宣言的に設定する:Standby Buffersの実装手順
Active Bufferからの設定変更はごくわずかです。CapacityBufferのspecに`provisioningStrategy`フィールドを追加して`buffer.gke.io/standby-capacity`を指定し、必要に応じてサスペンドのタイミングとリフレッシュ頻度を制御する2つの新しいアノテーションを調整するだけです。
### 前提条件
Standby Buffersを利用するには、GKE Standardクラスタが`1.36.0-gke.2253000`以降のバージョンで動作している必要があります。また、ノード自動プロビジョニングが**必須**です。要件と制限事項の詳細は[公式ドキュメント](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations)を参照してください。
### ステップ1: NamespaceとComputeClassを作成する
フォールバック用のコンピュート優先順位を設定したい場合は、[`ComputeClass`](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes)を定義します。
```YAML
apiVersion: v1
kind: Namespace
metadata:
name: platform-scaling
---
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: high-perf-compute
namespace: platform-scaling
spec:
priorities:
- machineFamily: n4
- machineFamily: n4d
- machineFamily: c4
- machineFamily: c4d
nodePoolAutoCreation:
enabled: true
```
### ステップ2: バッファユニットを定義する
スケール対象のワークロードのリソースプロファイルを反映した`PodTemplate`を作成します。GKEはこれをもとに、各バッファユニットに必要なコンピュート容量を判断します。
```YAML
apiVersion: v1
kind: PodTemplate
metadata:
name: app-buffer-template
namespace: platform-scaling
template:
spec:
terminationGracePeriodSeconds: 0
containers:
- name: buffer-container
image: registry.k8s.io/pause:3.9
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
nodeSelector:
cloud.google.com/compute-class: high-perf-compute
```
### ステップ3: Standby Bufferを作成する
Active Bufferと比べて意味のある変更は`provisioningStrategy`フィールドだけです。2つの[アノテーション](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#customize-standby-behavior)は、ノードがサスペンドされるまでアクティブのまま留まる時間と、DaemonSetのバージョンやイメージレイヤーを最新に保つためにサスペンド済みノードをリフレッシュする頻度を制御します。
```yaml
apiVersion: autoscaling.x-k8s.io/v1beta1
kind: CapacityBuffer
metadata:
name: my-standby-buffer
namespace: platform-scaling
annotations:
# How long a node stays active after init before being suspended (default: 5m)
# Increase if your workload needs time to preload heavy images or ML models
buffer.gke.io/standby-capacity-init-time: "5m"
# How often suspended nodes are recreated to stay fresh (default: 1d)
buffer.gke.io/standby-capacity-refresh-frequency: "1d"
spec:
podTemplateRef:
name: app-buffer-template
limits:
cpu: "50"
memory: "50Gi"
provisioningStrategy: "buffer.gke.io/standby-capacity"
```
### ステップ4: 小さなActive Bufferと組み合わせる(推奨)
5 CPU・5 GBメモリのActive Buffer
```yaml
apiVersion: autoscaling.x-k8s.io/v1beta1
kind: CapacityBuffer
metadata:
name: my-active-buffer
namespace: platform-scaling
spec:
podTemplateRef:
name: app-buffer-template
limits:
cpu: "5"
memory: "5Gi"
provisioningStrategy: "buffer.x-k8s.io/active-capacity"
```
### ステップ5: サスペンド済みノードを確認する
キャパシティバッファがサスペンド済みノードをネイティブに管理していることは、`kubectl`で確認できます。サスペンド済みノードはSuspendedコンディションで見分けられます。
```bash
kubectl get nodes -o custom-columns=\
'NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status'
```
出力例:
```yaml
NAME SUSPENDED
gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-4v2z False
gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-pdbs
gke-cluster-3-nap-n4-highcpu-4-1b5c18-fb0115cd-mrfm True
```
取り得る3つの状態は次のとおりです。
- `` — アクティブで、一度もサスペンドされたことがないノード(通常のクラスタノードやActive Bufferノードなど)
- `False` — 以前サスペンドされていたが、ワークロードを処理するために復帰したノード
- `True` — 現在サスペンド中のノード(Standby Buffer。ディスクとIPの料金のみ発生)
## イメージのプリロード:省略は禁物
サスペンド済みノードはコールドスタートより速く復帰しますが、実際のPodが配置される時点で、ワークロードのイメージがノード上に存在していなければなりません。`standby-capacity-init-time`アノテーションはサスペンド前の起動ウィンドウをノードに与えるものの、そのウィンドウ中に明示的にイメージを要求するものがなければ、イメージは自動でプルされません。
GKEが推奨するのは、初期化ウィンドウの間に動作するイメージプリロード用[DaemonSet](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#preload-images)をデプロイする方法です。要となるのは、`buffer.gke.io/standby-node-suspended` taintに対するtolerationです。これがあることで、DaemonSetがStandby Bufferノードにスケジュールされるようになります(無いとスキップされてしまいます)。その後、initコンテナが対象イメージをプルし、ノードがサスペンドされる前にcontainerdへイメージレイヤーをローカルディスクへキャッシュさせます。
スケーリングイベントが発生すると、ノードはイメージをローカルストレージに抱えたままスタンバイから復帰するため、Podはレジストリからのプルを待たずにすぐに起動できます。
## まとめ
Standby Bufferの登場で、GKEのキャパシティバッファの全体像がついに完成しました。Active Bufferはウォームな稼働中の容量を確保することでノードプロビジョニングのレイテンシを解消し、Standby Bufferはそのセーフティネットを大規模に維持するコスト問題を解消します。
宣言的な2層構成のActive/Standbyキャパシティバッファ戦略を取り入れれば、ユーザー需要にミリ秒単位で応答する自己修復型インフラを構築しつつ、FinOpsチームをこの上なく満足させることができます。
まずは小さなStandby BufferをActive Bufferと組み合わせて始め、トラフィックパターンと復帰ウィンドウの相性を観察しながら、そこから育てていきましょう。Googleは、パフォーマンス目標に合わせてバッファサイズを見極めるのに実際に役立つ[バッファサイジングシミュレータ](https://github.com/gke-labs/buffers-simulator)も公開しています。設定リファレンスの全容は[GKEキャパシティバッファのドキュメント](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer)をご覧ください。