Nel mio [post precedente](https://www.doit.com/blog/instant-on-scaling-eliminating-node-provisioning-delays-in-gke-with-active-buffer) ho raccontato come l'[Active Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer) di GKE abbia risolto uno dei problemi più spinosi della gestione di Kubernetes: la latenza nel provisioning dei nodi. Dichiarando una risorsa [`CapacityBuffer`](https://docs.cloud.google.com/kubernetes-engine/docs/reference/crds/capacitybuffer), l'Active Buffer tiene pronti nodi pre-riscaldati in grado di assorbire all'istante i picchi di traffico — niente più avvii a freddo di diversi minuti, niente più balloon pod, niente più acrobazie artigianali con `PriorityClass`.
Ma, come ogni schema architetturale che mantiene nodi on-demand attivi e inutilizzati, anche gli active buffer hanno un prezzo. Sono più economici di un over-provisioning indiscriminato dell'intero cluster, ma occorre comunque pagare un sovrapprezzo per tenere intere macchine virtuali in piedi 24 ore su 24. Se ti serve una rete di sicurezza ampia — diciamo 50 CPU e 50 GiB di RAM in riserva — stai pagando tariffe di calcolo piene per nodi che restano fermi.
A giugno 2026 Google ha rilasciato la risposta a questo problema: **[Standby Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#standby_buffer)**, una nuova `provisioningStrategy` per l'API `CapacityBuffer` che consente a GKE di effettuare il pre-provisioning e l'inizializzazione completa dei nodi tenendoli poi in uno stato sospeso. Disponibili a partire dalla versione GKE `1.36.0-gke.2253000`, gli standby buffer permettono di ottenere uno scheduling sotto il secondo per workloads imprevedibili, riducendo al tempo stesso i costi dell'infrastruttura inattiva fino al 90% rispetto a un over-provisioning totale.
> **Nota:** gli standby buffer sono attualmente in **Preview** e soggetti ai "Pre-GA Offerings Terms". Consulta [requisiti e limitazioni](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) prima di portarli in produzione.
## L'evoluzione: Active vs. Standby Buffer
Per cogliere il valore degli standby buffer, conviene mettere a confronto come ciascuna strategia tratta l'infrastruttura di calcolo:
**Active Buffer (`buffer.x-k8s.io/active-capacity`):** GKE crea pod placeholder leggeri per rappresentare la domanda in attesa. Il Cluster Autoscaler li intercetta e fa il provisioning di VM reali e pienamente operative. I nodi sono attivi, i DaemonSet caricati e le istanze vengono fatturate a tariffa piena. Quando i pod dei workloads reali scalano, prendono subito il posto su questa capacità già calda.
**Standby Buffer (`buffer.gke.io/standby-capacity`):** GKE effettua il provisioning e l'inizializzazione completa dei nodi — avviando i DaemonSet e lasciando il tempo di precaricare le immagini dei container — per poi **sospendere le istanze di calcolo sottostanti**. Lo stato del sistema operativo viene conservato su disco, la fatturazione di CPU e memoria si ferma e si paga solo per il disco persistente e l'indirizzo IP. Quando arriva un picco di domanda, questi nodi sospesi tornano operativi **2-3 volte più rapidamente** rispetto al provisioning di una VM da zero, perché i passaggi di bootstrap del sistema operativo e di Kubernetes sono già stati eseguiti.
**I benchmark:** dai [primi benchmark](https://cloud.google.com/blog/products/containers-kubernetes/gke-standby-buffers-speed-up-autoscaling-for-less-spend) pubblicati da Google emerge che un cluster con standby buffer ha garantito una latenza di scheduling sotto il secondo per workloads dinamici (come gli AI Agent Sandbox) con costi inferiori fino al 90% rispetto al classico over-provisioning.

gke-cluster-3-nap-n4-highcpu-4-1b5c18-fb0115cd-mrfm True
```
I tre stati possibili sono:
- `` — il nodo è attivo e non è mai stato sospeso (ad esempio un normale nodo del cluster o un nodo di active buffer)
- `False` — il nodo è stato sospeso in precedenza, ma è stato riattivato per servire i workloads
- `True` — il nodo è attualmente sospeso (standby buffer: si paga solo disco e IP)
## Preloading delle immagini: non saltarlo
Un nodo sospeso si riattiva più rapidamente di un avvio a freddo, ma le immagini dei tuoi workloads devono comunque essere già presenti sul nodo quando vi atterra un pod reale. L'annotation `standby-capacity-init-time` concede al nodo una finestra di avvio prima della sospensione, ma le immagini non vengono scaricate automaticamente: serve qualcosa che le richieda esplicitamente in quella finestra.
L'approccio supportato da GKE consiste nel distribuire un [DaemonSet](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#preload-images) di preloading delle immagini eseguito durante la finestra di init. Il dettaglio chiave è la toleration per il taint `buffer.gke.io/standby-node-suspended`: senza di essa il DaemonSet verrebbe ignorato sui nodi di standby buffer, mentre così viene correttamente schedulato. Un init container scarica poi l'immagine di destinazione, costringendo containerd a memorizzare in cache locale i layer prima che il nodo entri in sospensione.
Quando si verifica un evento di scaling, il nodo si risveglia dallo standby con l'immagine già nello storage locale — il pod parte immediatamente, senza attendere il pull dal registry.
## Riepilogo
Lo standby buffer chiude il cerchio sui capacity buffer di GKE. L'active buffer risolve la latenza di provisioning dei nodi tenendo pronta capacità calda e operativa. Lo standby buffer risolve il costo di mantenere quella rete di sicurezza su larga scala.
Adottando una strategia dichiarativa di capacity buffer a due livelli (active e standby), puoi costruire un'infrastruttura auto-riparante che risponde alla domanda degli utenti in millisecondi, mantenendo al tempo stesso il tuo team FinOps incredibilmente felice.
Parti con un piccolo standby buffer affiancato a un active buffer, osserva come i tuoi pattern di traffico interagiscono con la finestra di ripresa e cresci da lì. Google ha anche realizzato un [simulatore di dimensionamento dei buffer](https://github.com/gke-labs/buffers-simulator) davvero utile per calibrarli sui tuoi obiettivi di performance. Il riferimento completo alla configurazione si trova nella [documentazione dei capacity buffer di GKE](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer).
Fonte: Google Cloud Blog
Nei test di latenza condotti con carichi di traffico identici, un cluster senza buffer ha registrato latenze di scheduling P95 e P99 bloccate tra i 4 e i 6 minuti. Il cluster con standby buffer, invece, ha mantenuto un P50 nell'ordine di pochi secondi, con P95/P99 saliti brevemente fino a un minuto prima di rientrare completamente nella norma. 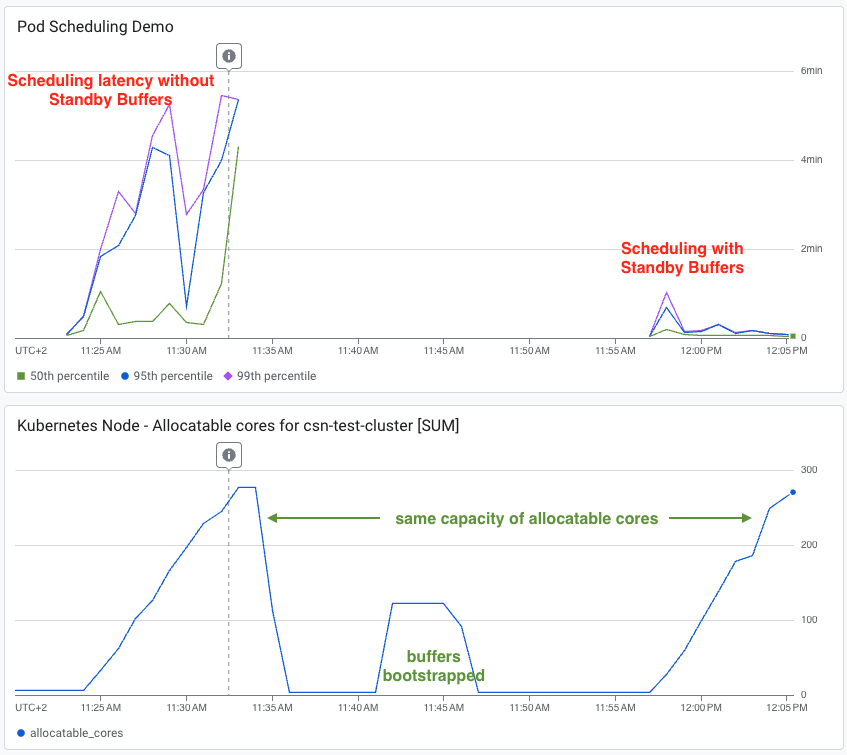Fonte: Google Cloud Blog
## Scegliere la strategia di buffer più adatta Se la tua applicazione richiede la latenza di scheduling dei pod più bassa in assoluto, non dovresti affidarti unicamente agli standby buffer. La ripresa di un nodo sospeso è rapida (circa 30 secondi, contro i diversi minuti di un avvio a freddo), ma introduce comunque una breve finestra di latenza per i picchi immediati e imprevedibili. Lo schema architetturale ideale è un sistema di buffer ibrido a due livelli: 1. **Active Buffer (l'ammortizzatore):** un piccolo pool di nodi pienamente operativi e a capacità riservata assorbe il picco immediato e imprevedibile con una latenza di scheduling sotto il secondo. 2. **Standby Buffer (la riserva profonda):** un pool più ampio di nodi sospesi si riattiva in circa 30 secondi per coprire picchi di traffico prolungati. Man mano che le unità di active buffer vengono consumate, i nodi standby che si risvegliano ripopolano il livello attivo. ```text [ Picco di traffico in arrivo ] │ ▼ ┌──────────────────────────────────────┐ │ Livello 1: Active Buffer (Istantaneo)│ ──► Assorbe il picco immediato └──────────────────────────────────────┘ │ (Quando il Livello 1 si esaurisce...) ▼ ┌──────────────────────────────────────┐ │ Livello 2: Standby Buffer (~30s) │ ──► Si risveglia per coprire il picco prolungato └──────────────────────────────────────┘ ``` **Filosofia di dimensionamento:** tieni l'active buffer snello ed economico — quanto basta per colmare i 30 secondi necessari al risveglio dei nodi standby. Dimensiona invece lo standby buffer in modo da coprire l'intero volume prolungato di un picco di traffico sostenuto. ## Configurazione dichiarativa: come implementare gli Standby Buffer La modifica di configurazione rispetto a un active buffer è minima. Basta aggiungere il campo `provisioningStrategy` alla spec del CapacityBuffer, impostarlo su `buffer.gke.io/standby-capacity` e, facoltativamente, regolare due nuove annotation che controllano i tempi di sospensione e la frequenza di refresh. ### Prerequisiti Per sfruttare gli standby buffer, assicurati che il tuo cluster GKE Standard esegua la versione `1.36.0-gke.2253000` o successiva. Il node auto-provisioning è **obbligatorio**. Consulta la [documentazione ufficiale](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) per requisiti e limitazioni completi. ### Step 1: creare un Namespace e una ComputeClass Se vuoi configurare priorità di calcolo di fallback, definisci una [`ComputeClass`](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes): ```YAML apiVersion: v1 kind: Namespace metadata: name: platform-scaling --- apiVersion: cloud.google.com/v1 kind: ComputeClass metadata: name: high-perf-compute namespace: platform-scaling spec: priorities: - machineFamily: n4 - machineFamily: n4d - machineFamily: c4 - machineFamily: c4d nodePoolAutoCreation: enabled: true ``` ### Step 2: definire l'unità di buffer Crea un `PodTemplate` che rispecchi il profilo di risorse dei workloads che intendi scalare. GKE lo utilizza per stabilire quanta capacità di calcolo richiede ogni unità di buffer. ```YAML apiVersion: v1 kind: PodTemplate metadata: name: app-buffer-template namespace: platform-scaling template: spec: terminationGracePeriodSeconds: 0 containers: - name: buffer-container image: registry.k8s.io/pause:3.9 resources: requests: cpu: "1" memory: "1Gi" limits: cpu: "1" memory: "1Gi" nodeSelector: cloud.google.com/compute-class: high-perf-compute ``` ### Step 3: creare lo Standby Buffer Il campo `provisioningStrategy` è l'unica aggiunta rilevante rispetto a un active buffer. Le due [annotation](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#customize-standby-behavior) controllano quanto a lungo un nodo resta attivo prima della sospensione e con quale frequenza i nodi sospesi vengono aggiornati per restare allineati alle versioni dei DaemonSet e ai layer delle immagini. ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-standby-buffer namespace: platform-scaling annotations: # Per quanto tempo un nodo resta attivo dopo l'init prima di essere sospeso (default: 5m) # Aumenta il valore se il workload deve precaricare immagini pesanti o modelli ML buffer.gke.io/standby-capacity-init-time: "5m" # Con quale frequenza i nodi sospesi vengono ricreati per restare aggiornati (default: 1d) buffer.gke.io/standby-capacity-refresh-frequency: "1d" spec: podTemplateRef: name: app-buffer-template limits: cpu: "50" memory: "50Gi" provisioningStrategy: "buffer.gke.io/standby-capacity" ``` ### Step 4: abbinare un piccolo active buffer (consigliato) Un active buffer da 5 CPU e 5 GB di RAM ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-active-buffer namespace: platform-scaling spec: podTemplateRef: name: app-buffer-template limits: cpu: "5" memory: "5Gi" provisioningStrategy: "buffer.x-k8s.io/active-capacity" ``` ### Step 5: verificare i nodi sospesi Puoi verificare che il tuo capacity buffer gestisca nativamente i nodi sospesi tramite `kubectl`. I nodi sospesi si identificano dalla condizione Suspended. ```bash kubectl get nodes -o custom-columns=\ 'NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status' ``` Output di esempio: ```yaml NAME SUSPENDED gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-4v2z False gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-pdbs