In meinem [vorherigen Beitrag](https://www.doit.com/blog/instant-on-scaling-eliminating-node-provisioning-delays-in-gke-with-active-buffer) habe ich gezeigt, wie der [Active Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer) von GKE eines der lästigsten Probleme im Kubernetes-Betrieb löst: die Latenz beim Node-Provisioning. Mit der deklarativen Ressource [`CapacityBuffer`](https://docs.cloud.google.com/kubernetes-engine/docs/reference/crds/capacitybuffer) hält Active Buffer vorgewärmte Nodes bereit, die Traffic-Spitzen sofort abfangen – Schluss mit minutenlangen Kaltstarts, Balloon-Pods und selbstgebauten `PriorityClass`-Verrenkungen.
Allerdings hat jedes Architekturmuster, bei dem reine On-Demand-Nodes im Leerlauf mitlaufen, seinen Preis – auch Active Buffer. Zwar ist er günstiger, als ein ganzes Cluster blind zu überdimensionieren, doch komplette virtuelle Maschinen rund um die Uhr bereitzuhalten, kostet einen Aufpreis. Wer ein großes Sicherheitsnetz braucht – sagen wir 50 CPUs und 50 GiB RAM in Reserve –, zahlt volle Compute-Preise für Nodes, die nichts tun.
Im Juni 2026 hat Google die Antwort darauf ausgeliefert: **[Standby Buffers](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#standby_buffer)**, eine neue `provisioningStrategy` für die `CapacityBuffer`-API, mit der GKE Nodes vorab bereitstellt, vollständig initialisiert und anschließend in einen Ruhezustand versetzt. Ab GKE-Version `1.36.0-gke.2253000` ermöglichen Standby Buffers Scheduling im Sekundenbruchteil für unvorhersehbare Workloads und senken gleichzeitig die Kosten für ungenutzte Infrastruktur um bis zu 90 % gegenüber vollständigem Over-Provisioning.
> **Hinweis:** Standby Buffers befinden sich derzeit in der **Preview**-Phase und unterliegen den "Pre-GA Offerings Terms". Prüfen Sie die [Anforderungen und Einschränkungen](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations), bevor Sie das Feature produktiv einsetzen.
## Die Evolution: Active vs. Standby Buffers
Um den Nutzen von Standby Buffers zu verstehen, hilft ein Vergleich, wie beide Strategien mit Compute-Infrastruktur umgehen:
**Active Buffers (`buffer.x-k8s.io/active-capacity`):** GKE erzeugt leichtgewichtige Platzhalter-Pods, die anstehenden Bedarf repräsentieren. Der Cluster Autoscaler fängt diese ab und stellt echte, voll laufende VMs bereit. Die Nodes sind aktiv, DaemonSets sind geladen und die Instanzen werden zum vollen Tarif abgerechnet. Sobald reale Workload-Pods hochskalieren, übernehmen sie diese vorgewärmte Kapazität sofort.
**Standby Buffers (`buffer.gke.io/standby-capacity`):** GKE stellt die Nodes bereit und initialisiert sie vollständig – fährt DaemonSets hoch und lässt Zeit, Container-Images vorzuladen – und **versetzt anschließend die zugrunde liegenden Compute-Instanzen in den Ruhezustand**. Der OS-Zustand bleibt auf der Festplatte erhalten, die Abrechnung von Compute und Arbeitsspeicher stoppt, und Sie zahlen nur noch für Persistent Disk und IP-Adresse. Steigt die Nachfrage, fahren diese pausierten Nodes **2–3x schneller** wieder hoch als eine frisch bereitgestellte VM, weil OS- und Kubernetes-Bootstrap bereits erledigt sind.
**Die Benchmarks:** Wie [erste Benchmarks](https://cloud.google.com/blog/products/containers-kubernetes/gke-standby-buffers-speed-up-autoscaling-for-less-spend) von Google zeigen, lieferte ein Cluster mit Standby Buffers für dynamische Workloads (etwa AI-Agent-Sandboxes) Scheduling-Latenzen im Sekundenbruchteil – und das bei bis zu 90 % geringeren Kosten als klassisches Over-Provisioning.

gke-cluster-3-nap-n4-highcpu-4-1b5c18-fb0115cd-mrfm True
```
Mögliche Zustände sind:
- `` – Node ist aktiv und wurde nie pausiert (z. B. regulärer Cluster-Node oder Active-Buffer-Node)
- `False` – Node war zuvor pausiert, wurde aber wieder aktiviert, um Workloads zu bedienen
- `True` – Node ist aktuell pausiert (Standby Buffer, es fallen nur Kosten für Disk und IP an)
## Image-Preloading: Bitte nicht überspringen
Ein pausierter Node fährt schneller hoch als ein Kaltstart, doch Ihre Workload-Images müssen weiterhin auf dem Node vorhanden sein, sobald ein echter Pod dort landet. Die Annotation `standby-capacity-init-time` räumt dem Node ein Startfenster vor der Suspendierung ein – Images werden in diesem Fenster jedoch nur dann gezogen, wenn sie aktiv angefordert werden.
Der von GKE empfohlene Ansatz ist ein Image-Preloading-[DaemonSet](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#preload-images), das während des Init-Fensters läuft. Entscheidend ist die Toleration für den Taint `buffer.gke.io/standby-node-suspended` – nur damit landet das DaemonSet auch auf Standby-Buffer-Nodes, die sonst übersprungen würden. Ein Init-Container zieht anschließend Ihr Ziel-Image und zwingt containerd, die Image-Layer vor der Suspendierung lokal auf der Festplatte zu cachen.
Tritt ein Skalierungsereignis ein, erwacht der Node aus dem Standby und hat das Image bereits lokal vorliegen – der Pod startet sofort, statt auf einen Registry-Pull zu warten.
## Fazit
Standby Buffer macht die Capacity-Buffer-Story von GKE komplett. Active Buffer löst die Latenz beim Node-Provisioning, indem er warme, laufende Kapazität bereithält. Standby Buffer löst die Frage, wie sich dieses Sicherheitsnetz im großen Maßstab bezahlbar halten lässt.
Mit einer deklarativen, zweistufigen Strategie aus Active und Standby Capacity Buffer bauen Sie eine selbstheilende Infrastruktur, die in Millisekunden auf Nutzerbedarf reagiert – und Ihr FinOps-Team rundum zufrieden stellt.
Starten Sie mit einem kleinen Standby Buffer parallel zu einem Active Buffer, beobachten Sie, wie Ihre Traffic-Muster mit dem Wake-Fenster zusammenspielen, und bauen Sie von dort aus weiter aus. Google stellt zudem einen [Buffer-Sizing-Simulator](https://github.com/gke-labs/buffers-simulator) bereit, der wirklich hilfreich ist, um die Buffer passend zu Ihren Performance-Zielen zu dimensionieren. Die vollständige Konfigurationsreferenz finden Sie in der [GKE-Capacity-Buffer-Dokumentation](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer).
Quelle: Google Cloud Blog
In Latenztests unter identischen Lastbedingungen blieben P95- und P99-Scheduling-Latenzen eines Clusters ohne Buffer zwischen 4 und 6 Minuten hängen. Der Cluster mit Standby Buffers hielt einen P50 im einstelligen Sekundenbereich; P95/P99 stiegen kurzzeitig auf eine Minute, bevor sie sich vollständig normalisierten. 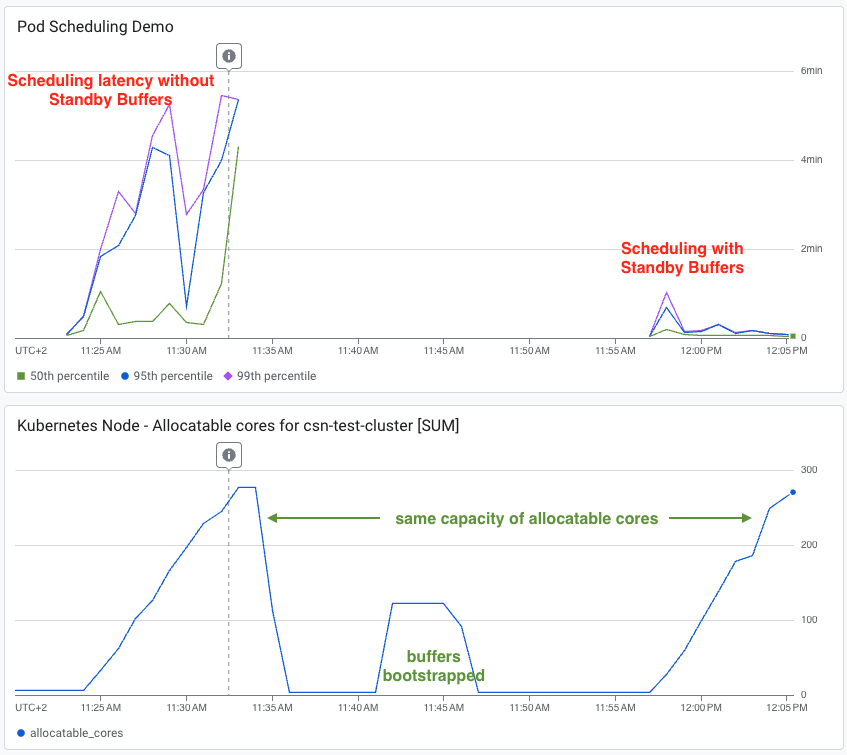Quelle: Google Cloud Blog
## Die richtige Buffer-Strategie wählen Wenn Ihre Anwendung die absolut niedrigste Pod-Scheduling-Latenz braucht, sollten Sie sich nicht ausschließlich auf Standby Buffers verlassen. Das Aufwecken eines pausierten Nodes geht zwar schnell (rund 30 Sekunden statt mehrerer Minuten Kaltstart), bringt aber dennoch ein kurzes Latenzfenster bei unmittelbaren, unvorhersehbaren Lastspitzen mit sich. Das optimale Architekturmuster ist ein hybrides, zweistufiges Buffer-System: 1. **Active Buffer (der Stoßdämpfer):** Ein kleiner Pool vollständig laufender, kapazitätsreservierter Nodes fängt die unmittelbare, unvorhersehbare Spitze mit Scheduling-Latenzen im Sekundenbruchteil ab. 2. **Standby Buffer (das tiefe Reservoir):** Ein größerer Pool pausierter Nodes wird in rund 30 Sekunden aktiviert und deckt anhaltende Lastspitzen ab. Werden die Active-Buffer-Einheiten verbraucht, füllen aufwachende Standby-Nodes die aktive Ebene wieder auf. ```text [ Eingehender Traffic-Spike ] │ ▼ ┌──────────────────────────────────────┐ │ Tier 1: Active Buffer (sofort) │ ──► Fängt unmittelbare Spitze ab └──────────────────────────────────────┘ │ (Sobald Tier 1 erschöpft ist...) ▼ ┌──────────────────────────────────────┐ │ Tier 2: Standby Buffer (~30s Wake) │ ──► Wacht auf, um anhaltenden Spike zu decken └──────────────────────────────────────┘ ``` **Sizing-Philosophie:** Halten Sie Ihren Active Buffer schlank und günstig – gerade groß genug, um die 30-Sekunden-Lücke zu überbrücken, bis die Standby-Nodes hochfahren. Dimensionieren Sie Ihren Standby Buffer so, dass er das gesamte Volumen einer anhaltenden Traffic-Spitze abdeckt. ## Deklarative Konfiguration: So implementieren Sie Standby Buffers Der Konfigurationsunterschied zum Active Buffer ist minimal. Sie ergänzen lediglich das Feld `provisioningStrategy` in Ihrer CapacityBuffer-Spec, setzen es auf `buffer.gke.io/standby-capacity` und justieren optional zwei neue Annotationen, die Suspension-Timing und Refresh-Frequenz steuern. ### Voraussetzungen Um Standby Buffers nutzen zu können, muss Ihr GKE-Standard-Cluster mindestens Version `1.36.0-gke.2253000` ausführen. Node Auto-Provisioning ist für Standby Buffers **zwingend erforderlich**. Die vollständigen Anforderungen und Einschränkungen finden Sie in der [offiziellen Dokumentation](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations). ### Schritt 1: Namespace und ComputeClass anlegen Wenn Sie Fallback-Compute-Prioritäten konfigurieren möchten, definieren Sie eine [`ComputeClass`](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes): ```YAML apiVersion: v1 kind: Namespace metadata: name: platform-scaling --- apiVersion: cloud.google.com/v1 kind: ComputeClass metadata: name: high-perf-compute namespace: platform-scaling spec: priorities: - machineFamily: n4 - machineFamily: n4d - machineFamily: c4 - machineFamily: c4d nodePoolAutoCreation: enabled: true ``` ### Schritt 2: Buffer-Einheit definieren Legen Sie ein `PodTemplate` an, das das Ressourcenprofil der Workloads abbildet, die Sie skalieren möchten. GKE bestimmt daraus, wie viel Compute-Kapazität jede Buffer-Einheit benötigt. ```YAML apiVersion: v1 kind: PodTemplate metadata: name: app-buffer-template namespace: platform-scaling template: spec: terminationGracePeriodSeconds: 0 containers: - name: buffer-container image: registry.k8s.io/pause:3.9 resources: requests: cpu: "1" memory: "1Gi" limits: cpu: "1" memory: "1Gi" nodeSelector: cloud.google.com/compute-class: high-perf-compute ``` ### Schritt 3: Standby Buffer erstellen Das Feld `provisioningStrategy` ist die einzige wesentliche Ergänzung gegenüber einem Active Buffer. Die beiden [Annotationen](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#customize-standby-behavior) steuern, wie lange ein Node aktiv bleibt, bevor er pausiert wird, und wie häufig pausierte Nodes erneuert werden, damit sie mit aktuellen DaemonSet-Versionen und Image-Layern Schritt halten. ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-standby-buffer namespace: platform-scaling annotations: # Wie lange ein Node nach der Initialisierung aktiv bleibt, bevor er pausiert wird (Standard: 5m) # Erhöhen, falls Ihr Workload Zeit zum Vorladen großer Images oder ML-Modelle braucht buffer.gke.io/standby-capacity-init-time: "5m" # Wie häufig pausierte Nodes neu erstellt werden, um aktuell zu bleiben (Standard: 1d) buffer.gke.io/standby-capacity-refresh-frequency: "1d" spec: podTemplateRef: name: app-buffer-template limits: cpu: "50" memory: "50Gi" provisioningStrategy: "buffer.gke.io/standby-capacity" ``` ### Schritt 4: Mit einem kleinen Active Buffer kombinieren (empfohlen) Ein Active Buffer mit 5 CPUs und 5 GB RAM ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-active-buffer namespace: platform-scaling spec: podTemplateRef: name: app-buffer-template limits: cpu: "5" memory: "5Gi" provisioningStrategy: "buffer.x-k8s.io/active-capacity" ``` ### Schritt 5: Pausierte Nodes prüfen Über `kubectl` lässt sich nachvollziehen, dass Ihr Capacity Buffer pausierte Nodes nativ verwaltet. Erkennbar sind sie an der Condition `Suspended`. ```bash kubectl get nodes -o custom-columns=\ 'NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status' ``` Beispielausgabe: ```yaml NAME SUSPENDED gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-4v2z False gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-pdbs