No meu [post anterior](https://www.doit.com/blog/instant-on-scaling-eliminating-node-provisioning-delays-in-gke-with-active-buffer), mostrei como o [Active Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer) do GKE resolveu um dos problemas mais incômodos da operação de Kubernetes: a latência no provisionamento de nós. Ao declarar um recurso [`CapacityBuffer`](https://docs.cloud.google.com/kubernetes-engine/docs/reference/crds/capacitybuffer), o Active Buffer mantém nós pré-aquecidos prontos para absorver picos de tráfego na hora — sem cold starts de vários minutos, sem balloon pods e sem ter que se virar com `PriorityClass` na mão.
Mas, como todo padrão arquitetural que deixa nós on-demand rodando ociosos, os active buffers cobram seu preço. Mesmo saindo mais barato do que superprovisionar o cluster inteiro às cegas, você ainda paga um adicional para manter máquinas virtuais completas de pé 24 horas por dia. Se a sua rede de segurança precisa ser grande — digamos, 50 CPUs e 50 GiB de RAM de reserva — você está pagando o preço cheio de computação por nós que ficam parados.
O Google entregou a resposta para esse problema em junho de 2026: **[Standby Buffers](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#standby_buffer)**, uma nova `provisioningStrategy` da API `CapacityBuffer` que permite ao GKE pré-provisionar e inicializar totalmente os nós em estado suspenso. Disponíveis a partir da versão `1.36.0-gke.2253000` do GKE, os standby buffers permitem agendamento em menos de um segundo para workloads imprevisíveis, reduzindo em até 90% o custo de infraestrutura ociosa em relação ao superprovisionamento total.
> **Observação:** os standby buffers estão atualmente em **Preview** e sujeitos aos "Pre-GA Offerings Terms". Revise os [requisitos e limitações](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) antes de usar em produção.
## A evolução: Active vs. Standby Buffers
Para entender o valor dos standby buffers, vale comparar como cada estratégia trata a infraestrutura de computação:
**Active Buffers (`buffer.x-k8s.io/active-capacity`):** o GKE cria pods placeholder leves para representar a demanda pendente. O Cluster Autoscaler intercepta isso e provisiona VMs reais, totalmente em execução. Os nós sobem, os DaemonSets são carregados e as instâncias rodam com cobrança cheia. Quando os pods de workload real escalam, eles assumem essa capacidade aquecida na hora.
**Standby Buffers (`buffer.gke.io/standby-capacity`):** o GKE provisiona e inicializa totalmente os nós — subindo DaemonSets e dando tempo de pré-carregar imagens de container — e então **suspende as instâncias de computação subjacentes**. O estado do SO fica preservado em disco, a cobrança de computação e memória para, e você paga só pelo disco persistente e pelo endereço IP. Quando a demanda dispara, esses nós suspensos retomam **2 a 3x mais rápido** do que provisionar uma VM do zero, porque o SO e as etapas de bootstrap do Kubernetes já estão prontas.
**Os benchmarks:** segundo os [primeiros benchmarks](https://cloud.google.com/blog/products/containers-kubernetes/gke-standby-buffers-speed-up-autoscaling-for-less-spend) divulgados pelo Google, um cluster usando standby buffers entregou latência de agendamento abaixo de um segundo para workloads dinâmicos (como sandboxes de AI Agent) com custo até 90% menor em comparação ao superprovisionamento clássico.

gke-cluster-3-nap-n4-highcpu-4-1b5c18-fb0115cd-mrfm True
```
Os três estados possíveis são:
- `` — o nó está ativo e nunca foi suspenso (ex.: nó comum do cluster ou nó de active buffer)
- `False` — o nó já foi suspenso antes, mas foi retomado para atender workloads
- `True` — o nó está suspenso no momento (standby buffer, pagando apenas por disco e IP)
## Pré-carregamento de imagens: não pule essa etapa
Um nó suspenso retoma mais rápido que um cold start, mas as imagens do seu workload ainda precisam estar no nó na hora em que um pod real chegar. A annotation `standby-capacity-init-time` dá ao nó uma janela de inicialização antes da suspensão, mas as imagens não são baixadas sozinhas — algo precisa solicitá-las explicitamente nessa janela.
A abordagem suportada pelo GKE é fazer o deploy de um [DaemonSet](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#preload-images) de pré-carregamento de imagens que rode durante essa janela de init. O detalhe importante é a tolerância ao taint `buffer.gke.io/standby-node-suspended` — é isso que garante que o DaemonSet seja agendado nos nós de standby buffer, que de outra forma seriam ignorados. Um init container então puxa a imagem alvo, forçando o containerd a colocar as camadas de imagem em cache no disco local antes de o nó suspender.
Quando ocorre um evento de escala, o nó desperta do standby com a imagem já no armazenamento local — o pod sobe na hora, sem esperar por um pull no registry.
## Resumo
O standby buffer fecha a história dos capacity buffers do GKE. O active buffer resolve a latência de provisionamento de nós mantendo capacidade aquecida e em execução. O standby buffer resolve o custo de manter essa rede de segurança em escala.
Ao adotar uma estratégia declarativa de capacity buffers em duas camadas, ativa e em standby, você constrói uma infraestrutura auto-recuperável que responde à demanda dos usuários em milissegundos e deixa seu time de FinOps muito feliz.
Comece com um pequeno standby buffer ao lado de um active buffer, observe como seus padrões de tráfego interagem com a janela de retomada e cresça a partir daí. O Google também criou um [simulador de dimensionamento de buffers](https://github.com/gke-labs/buffers-simulator) que é realmente útil para ajustar o tamanho dos buffers às suas metas de performance. A referência completa de configuração está nos [docs de capacity buffer do GKE](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer).
Fonte: Google Cloud Blog
Em testes de latência sob cargas de tráfego idênticas, um cluster sem buffers ficou com latências de agendamento P95 e P99 travadas entre 4 e 6 minutos. Já o cluster com standby buffers manteve P50 na casa dos poucos segundos, com P95/P99 atingindo brevemente um minuto antes de normalizar por completo. 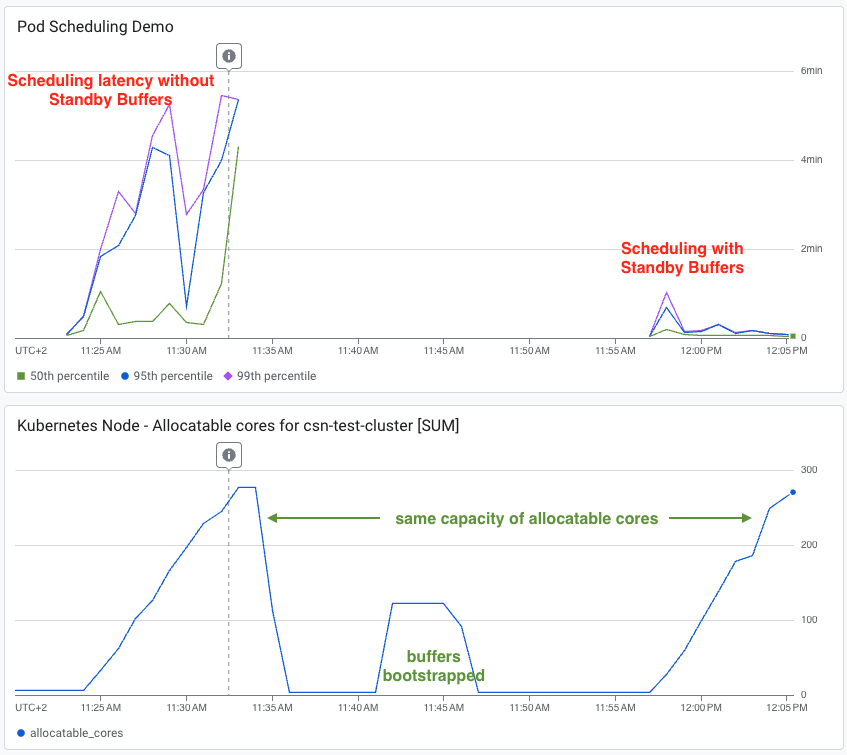Fonte: Google Cloud Blog
## Escolhendo a estratégia de buffer certa Se a sua aplicação exige a menor latência possível no agendamento de pods, não dá para contar só com standby buffers. Retomar um nó suspenso é rápido (cerca de 30 segundos, contra vários minutos de um cold start), mas ainda existe uma pequena janela de latência para picos imediatos e imprevisíveis. O padrão arquitetural definitivo é um sistema de buffers híbrido, em duas camadas: 1. **Active Buffer (o amortecedor):** um pequeno pool de nós totalmente em execução, com capacidade reservada, absorve o pico imediato e imprevisível com latência de agendamento abaixo de um segundo. 2. **Standby Buffer (o grande reservatório):** um pool maior de nós suspensos retoma em cerca de 30 segundos para cobrir picos prolongados de tráfego. À medida que as unidades do active buffer são consumidas, os nós em standby vão acordando e repondo a camada ativa. ```text [ Pico de tráfego recebido ] │ ▼ ┌──────────────────────────────────────┐ │ Camada 1: Active Buffer (Instantâneo)│ ──► Absorve o pico imediato └──────────────────────────────────────┘ │ (Conforme a Camada 1 esgota...) ▼ ┌──────────────────────────────────────┐ │ Camada 2: Standby Buffer (~30s) │ ──► Acorda para cobrir pico prolongado └──────────────────────────────────────┘ ``` **Filosofia de dimensionamento:** mantenha o active buffer enxuto e barato — só o suficiente para cobrir os 30 segundos que os nós em standby levam para acordar. Mantenha o standby buffer grande o bastante para cobrir o volume completo e prolongado de um pico sustentado de tráfego. ## Configuração declarativa: como implementar Standby Buffers A mudança de configuração em relação a um active buffer é mínima. Basta acrescentar o campo `provisioningStrategy` à spec do CapacityBuffer, defini-lo como `buffer.gke.io/standby-capacity` e, opcionalmente, ajustar duas novas annotations que controlam o tempo de suspensão e a frequência de atualização. ### Pré-requisitos Para aproveitar os standby buffers, garanta que seu cluster GKE Standard esteja rodando a versão `1.36.0-gke.2253000` ou superior. O node auto-provisioning é **obrigatório** para standby buffers. Consulte a [documentação oficial](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) para ver todos os requisitos e limitações. ### Passo 1: criar um Namespace e uma ComputeClass Se quiser configurar prioridades de fallback de computação, defina uma [`ComputeClass`](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes): ```YAML apiVersion: v1 kind: Namespace metadata: name: platform-scaling --- apiVersion: cloud.google.com/v1 kind: ComputeClass metadata: name: high-perf-compute namespace: platform-scaling spec: priorities: - machineFamily: n4 - machineFamily: n4d - machineFamily: c4 - machineFamily: c4d nodePoolAutoCreation: enabled: true ``` ### Passo 2: definir a unidade de buffer Crie um `PodTemplate` que espelhe o perfil de recursos dos workloads que você pretende escalar. É a partir disso que o GKE determina quanta capacidade de computação cada unidade de buffer exige. ```YAML apiVersion: v1 kind: PodTemplate metadata: name: app-buffer-template namespace: platform-scaling template: spec: terminationGracePeriodSeconds: 0 containers: - name: buffer-container image: registry.k8s.io/pause:3.9 resources: requests: cpu: "1" memory: "1Gi" limits: cpu: "1" memory: "1Gi" nodeSelector: cloud.google.com/compute-class: high-perf-compute ``` ### Passo 3: criar o Standby Buffer O campo `provisioningStrategy` é a única adição relevante em relação a um active buffer. As duas [annotations](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#customize-standby-behavior) controlam por quanto tempo um nó permanece ativo antes da suspensão e com que frequência os nós suspensos são atualizados para acompanhar versões de DaemonSets e camadas de imagem. ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-standby-buffer namespace: platform-scaling annotations: # Quanto tempo o nó fica ativo após o init antes de ser suspenso (padrão: 5m) # Aumente se o workload precisar de tempo para pré-carregar imagens pesadas ou modelos de ML buffer.gke.io/standby-capacity-init-time: "5m" # Com que frequência os nós suspensos são recriados para se manterem atualizados (padrão: 1d) buffer.gke.io/standby-capacity-refresh-frequency: "1d" spec: podTemplateRef: name: app-buffer-template limits: cpu: "50" memory: "50Gi" provisioningStrategy: "buffer.gke.io/standby-capacity" ``` ### Passo 4: combinar com um pequeno active buffer (recomendado) Um active buffer de 5 CPUs e 5 GB de RAM ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-active-buffer namespace: platform-scaling spec: podTemplateRef: name: app-buffer-template limits: cpu: "5" memory: "5Gi" provisioningStrategy: "buffer.x-k8s.io/active-capacity" ``` ### Passo 5: verificar os nós suspensos Você pode confirmar que seu capacity buffer está gerenciando nós suspensos de forma nativa pelo `kubectl`. Os nós suspensos podem ser identificados pela condição Suspended. ```bash kubectl get nodes -o custom-columns=\ 'NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status' ``` Exemplo de saída: ```yaml NAME SUSPENDED gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-4v2z False gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-pdbs