En mi [post anterior](https://www.doit.com/blog/instant-on-scaling-eliminating-node-provisioning-delays-in-gke-with-active-buffer) conté cómo el [Active Buffer](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer) de GKE resolvió uno de los dolores de cabeza más grandes en operaciones de Kubernetes: la latencia de aprovisionamiento de nodos. Al permitirte declarar un recurso [`CapacityBuffer`](https://docs.cloud.google.com/kubernetes-engine/docs/reference/crds/capacitybuffer), el Active Buffer mantiene nodos precalentados listos para absorber picos de tráfico al instante: se acabaron los arranques en frío de varios minutos, los balloon pods y las acrobacias artesanales con `PriorityClass`.
Pero, como ocurre con cualquier patrón arquitectónico que mantiene nodos on-demand corriendo en reposo, los Active Buffers tienen un costo. Aunque resulta más barato que sobreaprovisionar a ciegas un clúster entero, igual hay que pagar un sobreprecio por tener máquinas virtuales completas encendidas 24/7. Si necesitas una red de seguridad grande —digamos, 50 CPUs y 50 GiB de RAM en reserva— terminas pagando tarifas completas de compute por nodos que están ociosos.
Google lanzó la respuesta a ese problema en junio de 2026: **[Standby Buffers](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#standby_buffer)**, una nueva `provisioningStrategy` para la API `CapacityBuffer` que permite a GKE preaprovisionar e inicializar nodos por completo en estado suspendido. Disponibles a partir de la versión `1.36.0-gke.2253000` de GKE, los Standby Buffers permiten lograr scheduling en menos de un segundo para workloads impredecibles y, al mismo tiempo, reducir hasta en un 90% el costo de la infraestructura ociosa frente al sobreaprovisionamiento total.
> **Nota:** Los Standby Buffers están actualmente en **Preview** y sujetos a los "Pre-GA Offerings Terms". Revisa los [requisitos y limitaciones](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) antes de usarlos en producción.
## La evolución: Active vs. Standby Buffers
Para entender el valor de los Standby Buffers, conviene contrastar cómo trata cada estrategia la infraestructura de compute:
**Active Buffers (`buffer.x-k8s.io/active-capacity`):** GKE crea placeholder pods ligeros que representan la demanda pendiente. El Cluster Autoscaler intercepta esa señal y aprovisiona VMs reales y totalmente activas. Los nodos quedan arriba, los DaemonSets cargados y las instancias corren con facturación completa. Cuando los pods reales escalan, toman al instante esa capacidad ya caliente.
**Standby Buffers (`buffer.gke.io/standby-capacity`):** GKE aprovisiona e inicializa los nodos por completo —levantando DaemonSets y dejando tiempo para precargar imágenes de contenedor— y luego **suspende las instancias de compute subyacentes**. El estado del SO se conserva en disco, la facturación de compute y memoria se detiene, y solo pagas por el disco persistente y la dirección IP. Cuando llega el pico de demanda, esos nodos suspendidos se reanudan **de 2 a 3 veces más rápido** que aprovisionar una VM nueva desde cero, porque los pasos de bootstrap del SO y de Kubernetes ya están hechos.
**Los benchmarks:** Según los [primeros benchmarks](https://cloud.google.com/blog/products/containers-kubernetes/gke-standby-buffers-speed-up-autoscaling-for-less-spend) publicados por Google, un clúster con Standby Buffers logró una latencia de scheduling de menos de un segundo para workloads dinámicos (como AI Agent Sandboxes) a un costo hasta un 90% menor que el sobreaprovisionamiento clásico.

gke-cluster-3-nap-n4-highcpu-4-1b5c18-fb0115cd-mrfm True
```
Los tres estados posibles son:
- `` — el nodo está activo y nunca se suspendió (por ejemplo, un nodo regular del clúster o un nodo de Active Buffer)
- `False` — el nodo se suspendió antes, pero se reanudó para atender workloads
- `True` — el nodo está suspendido actualmente (Standby Buffer, pagando solo por disco e IP)
## Precarga de imágenes: no la dejes pasar
Un nodo suspendido se reanuda más rápido que un arranque en frío, pero las imágenes de tu workload igual tienen que estar presentes en el nodo cuando aterrice un pod real. La anotación `standby-capacity-init-time` le da al nodo una ventana de arranque antes de suspenderlo, pero las imágenes no se descargan automáticamente a menos que algo las pida de forma explícita durante esa ventana.
El enfoque soportado por GKE es desplegar un [DaemonSet](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#preload-images) de precarga de imágenes que corra durante la ventana de init. El detalle clave es la toleration para el taint `buffer.gke.io/standby-node-suspended`: con ella se garantiza que el DaemonSet se programe en los nodos de Standby Buffer, que de otro modo quedarían fuera. Un init container descarga entonces tu imagen objetivo, forzando a containerd a cachear las capas en disco local antes de que el nodo se suspenda.
Cuando ocurre un evento de escalado, el nodo despierta del standby con la imagen ya en almacenamiento local: el pod arranca de inmediato, sin tener que esperar una descarga desde el registry.
## Resumen
El Standby Buffer cierra la historia del capacity buffer de GKE. El Active Buffer resuelve la latencia de aprovisionamiento de nodos al mantener capacidad caliente y en ejecución. El Standby Buffer resuelve el costo de sostener esa red de seguridad a escala.
Al adoptar una estrategia declarativa de capacity buffer en dos niveles (active y standby), puedes construir una infraestructura self-healing que responde a la demanda de los usuarios en milisegundos y, a la vez, mantiene a tu equipo de FinOps increíblemente contento.
Empieza con un Standby Buffer pequeño junto a un Active Buffer, observa cómo interactúan tus patrones de tráfico con la ventana de reanudación y crece desde ahí. Google también creó un [simulador de dimensionamiento de buffers](https://github.com/gke-labs/buffers-simulator) que resulta genuinamente útil para dimensionar los buffers según tus objetivos de rendimiento. La referencia completa de configuración está en la [documentación de capacity buffer de GKE](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer).
Fuente: Google Cloud Blog
En pruebas de latencia bajo cargas de tráfico idénticas, un clúster sin buffers mostró latencias de scheduling P95 y P99 estancadas entre 4 y 6 minutos. El clúster con Standby Buffers mantuvo un P50 de pocos segundos, con P95/P99 alcanzando brevemente un minuto antes de normalizarse por completo. 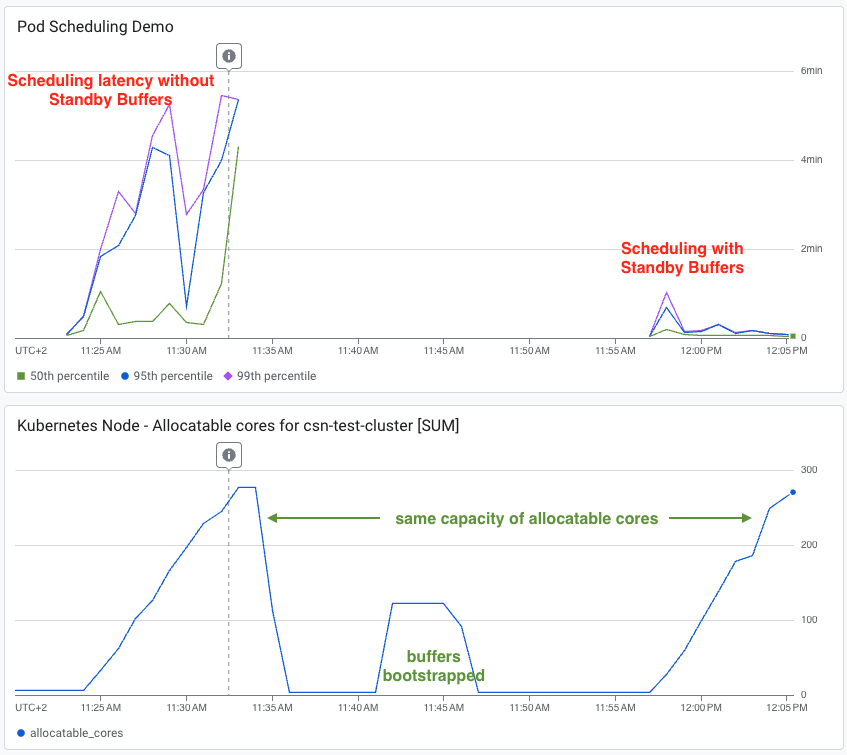Fuente: Google Cloud Blog
## Cómo elegir la estrategia de buffer adecuada Si tu aplicación necesita la mínima latencia posible al programar pods, no te conviene apoyarte solo en Standby Buffers. Aunque reanudar un nodo suspendido es rápido (cerca de 30 segundos frente a varios minutos de un arranque en frío), aún introduce una breve ventana de latencia ante picos inmediatos e impredecibles. El patrón arquitectónico definitivo es un sistema híbrido de buffers en dos niveles: 1. **Active Buffer (el amortiguador):** un pool pequeño de nodos completamente activos con capacidad reservada absorbe el pico inmediato e impredecible con latencia de scheduling de menos de un segundo. 2. **Standby Buffer (el reservorio profundo):** un pool más grande de nodos suspendidos se reanuda en unos 30 segundos para cubrir picos de tráfico prolongados. A medida que se consumen las unidades del Active Buffer, los nodos en standby despiertan y vuelven a llenar el nivel activo. ```text [ Pico de tráfico entrante ] │ ▼ ┌──────────────────────────────────────┐ │ Nivel 1: Active Buffer (Instantáneo)│ ──► Absorbe el pico inmediato └──────────────────────────────────────┘ │ (A medida que el Nivel 1 se agota...) ▼ ┌──────────────────────────────────────┐ │ Nivel 2: Standby Buffer (~30s) │ ──► Despierta para cubrir el pico extendido └──────────────────────────────────────┘ ``` **Filosofía de dimensionamiento:** mantén el Active Buffer ligero y económico, lo justo para cubrir los 30 segundos que tardan los nodos en standby en despertar. Mantén el Standby Buffer lo suficientemente grande para absorber el volumen completo y prolongado de un pico de tráfico sostenido. ## Configuración declarativa: cómo implementar Standby Buffers El cambio de configuración respecto a un Active Buffer es mínimo. Basta con agregar el campo `provisioningStrategy` a tu spec de CapacityBuffer, asignarle el valor `buffer.gke.io/standby-capacity` y, de manera opcional, ajustar dos nuevas anotaciones que controlan el timing de suspensión y la frecuencia de refresco. ### Requisitos previos Para aprovechar los Standby Buffers, tu clúster GKE Standard debe correr la versión `1.36.0-gke.2253000` o superior. El node auto-provisioning es **obligatorio**. Consulta la [documentación oficial](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/capacity-buffer#requirements_and_limitations) para ver todos los requisitos y limitaciones. ### Paso 1: crear un Namespace y un ComputeClass Si quieres configurar prioridades de compute de fallback, define un [`ComputeClass`](https://docs.cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes): ```YAML apiVersion: v1 kind: Namespace metadata: name: platform-scaling --- apiVersion: cloud.google.com/v1 kind: ComputeClass metadata: name: high-perf-compute namespace: platform-scaling spec: priorities: - machineFamily: n4 - machineFamily: n4d - machineFamily: c4 - machineFamily: c4d nodePoolAutoCreation: enabled: true ``` ### Paso 2: definir la unidad de buffer Crea un `PodTemplate` que refleje el perfil de recursos de los workloads que vas a escalar. GKE lo usa para determinar cuánta capacidad de compute requiere cada unidad de buffer. ```YAML apiVersion: v1 kind: PodTemplate metadata: name: app-buffer-template namespace: platform-scaling template: spec: terminationGracePeriodSeconds: 0 containers: - name: buffer-container image: registry.k8s.io/pause:3.9 resources: requests: cpu: "1" memory: "1Gi" limits: cpu: "1" memory: "1Gi" nodeSelector: cloud.google.com/compute-class: high-perf-compute ``` ### Paso 3: crear el Standby Buffer El campo `provisioningStrategy` es el único agregado relevante respecto a un Active Buffer. Las dos [anotaciones](https://docs.cloud.google.com/kubernetes-engine/docs/how-to/configure-capacity-buffer#customize-standby-behavior) controlan cuánto tiempo permanece activo un nodo antes de suspenderse y con qué frecuencia se refrescan los nodos suspendidos para mantenerse al día con las versiones de DaemonSet y las capas de imagen. ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-standby-buffer namespace: platform-scaling annotations: # Cuánto tiempo permanece activo un nodo después del init antes de suspenderse (default: 5m) # Auméntalo si tu workload necesita tiempo para precargar imágenes pesadas o modelos de ML buffer.gke.io/standby-capacity-init-time: "5m" # Con qué frecuencia se recrean los nodos suspendidos para mantenerlos al día (default: 1d) buffer.gke.io/standby-capacity-refresh-frequency: "1d" spec: podTemplateRef: name: app-buffer-template limits: cpu: "50" memory: "50Gi" provisioningStrategy: "buffer.gke.io/standby-capacity" ``` ### Paso 4: combinar con un Active Buffer pequeño (recomendado) Un Active Buffer de 5 CPUs y 5 GB de RAM ```yaml apiVersion: autoscaling.x-k8s.io/v1beta1 kind: CapacityBuffer metadata: name: my-active-buffer namespace: platform-scaling spec: podTemplateRef: name: app-buffer-template limits: cpu: "5" memory: "5Gi" provisioningStrategy: "buffer.x-k8s.io/active-capacity" ``` ### Paso 5: verificar los nodos suspendidos Puedes verificar de forma nativa que tu capacity buffer está gestionando nodos suspendidos mediante `kubectl`. Los nodos suspendidos se identifican por la condición Suspended. ```bash kubectl get nodes -o custom-columns=\ 'NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status' ``` Salida de ejemplo: ```yaml NAME SUSPENDED gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-4v2z False gke-cluster-3-nap-n4-highcpu-2-nm9ieq-586f2c73-pdbs