はじめに
DoiTのようなGoogle Cloud Premier Partnerに身を置く醍醐味のひとつは、新しいテクノロジーにいち早く触れられることです。今回取り上げるのは、
Googleの新しいN4Aインスタンスファミリー。Google Axion Processorsを搭載したArmベースの汎用VMです。
N4Aは、GoogleのArmプロセッサー戦略における新たな一手であり、明確な位置づけを持っています。2024年10月にリリースされたC4Aがパフォーマンス特化型のAxion搭載インスタンスファミリーであるのに対し、N4Aはコスト最適化型のArm汎用ファミリーとして、まったく異なるアプローチを取っています。これによりGoogleは、Axionで「better together(組み合わせて最適化)」戦略を実現できるようになりました。
- C4A=レイテンシー重視のworkloads向けパフォーマンス最適化Arm(1vCPU/4GBで時間単価$0.0449)
- N4A=汎用コンピュートフリート向けコスト最適化Arm(1vCPU/4GBで時間単価$0.0385)
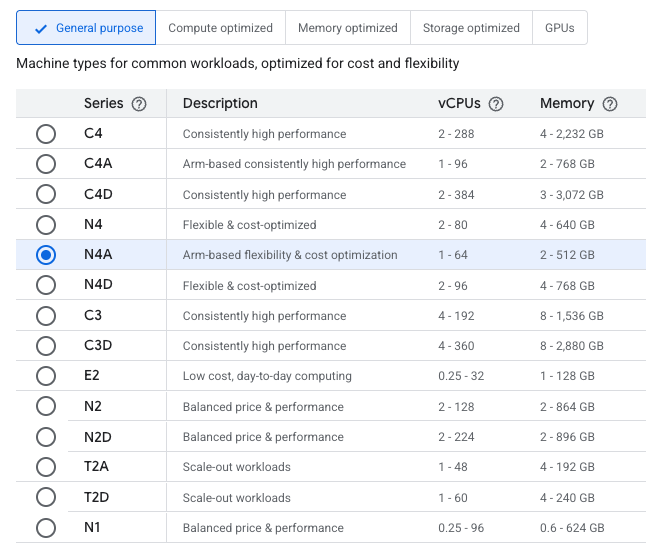
N4Aオプションが表示されたCompute Engineの画面
N4AシリーズについてのGoogle Cloud公式ドキュメント
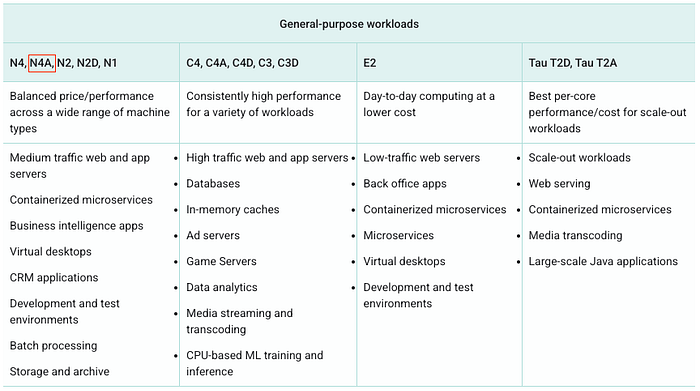
汎用workloads向けのN4A
ここ数日、N4AをN4、C4A、そしてAWSのGraviton4搭載M8gと徹底的に比較してみました。N4Aがあなたのインフラに加えるだけの価値があるのか——テスト結果から見えてきたことをご紹介します。

テストに使用したVMのCLI一覧
検証方法
本記事のベンチマークはすべて、以下の構成で実施しました。
- N4:n4-standard-8(Intel Xeon 第5世代 — Emerald Rapids)
- N4A:n4a-standard-8(Google Axion / Arm Neoverse N3)
- C4A:c4a-standard-8(Google Axion / Arm Neoverse V2)
- M8g:m8g.2xlarge(AWS Graviton4 / Arm Neoverse V2)
環境設定
- OS:Debian GNU/Linux 13(trixie)
(ArmインスタンスはARM64、N4はx86_64)
- カーネル:6.12.48+deb13-cloud-arm64
- 新規インスタンス、カスタムチューニングなし
使用ツール
Sysbench:CPU演算性能の測定
- 8スレッドのマルチスレッドテスト
- 実行時間120秒
- 素数計算(最大20000)
- 主要指標:イベント数/秒
7-Zip:実環境に近い圧縮workloadの測定
- マルチスレッドの圧縮/解凍
- 圧縮・解凍の両方の性能を計測
- 主要指標:総合MIPSレーティング
OpenSSL:暗号処理性能の測定
- ハードウェア暗号アクセラレーションを検証(Armの強み)
- AES-256-GCMおよびSHA256アルゴリズム
- 主要指標:MB/秒スループット
すべてのテストを複数回実行し、中央値を結果として採用しています。スクリプトはこちらのGistで公開しています。
ベンチマーク結果
SysbenchによるCPU性能
素数計算による純粋なCPU演算スループット(数値が高いほど優秀)。
N4Aが最も高い素のCPU性能を発揮し、C4A(+13.7%)とM8g(+21.7%)の両方を上回りました。Neoverse N3アーキテクチャの演算性能の高さが際立っています。
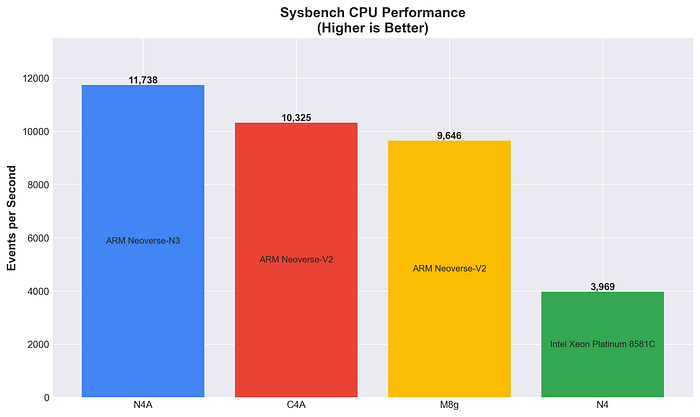
SysbenchによるCPU性能
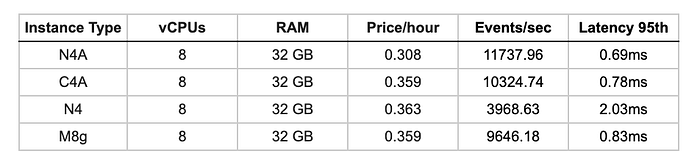
価格性能比
ArmインスタンスはIntel x86の2.4〜3倍の演算性能を示しました。N4AのN3アーキテクチャはC4AのV2より約14%高い性能を発揮しており、汎用workloadsにおける優れた演算効率を裏付けています。
7-Zip圧縮
クラウドworkloadsで頻繁に発生する、実環境に近い圧縮/解凍性能(数値が高いほど優秀)。
圧縮workloadsではC4Aが首位、その他は同程度の性能でした。解凍タスクでは予想通り、すべてのArmインスタンスがN4を大きく上回っています(75〜87%向上)。
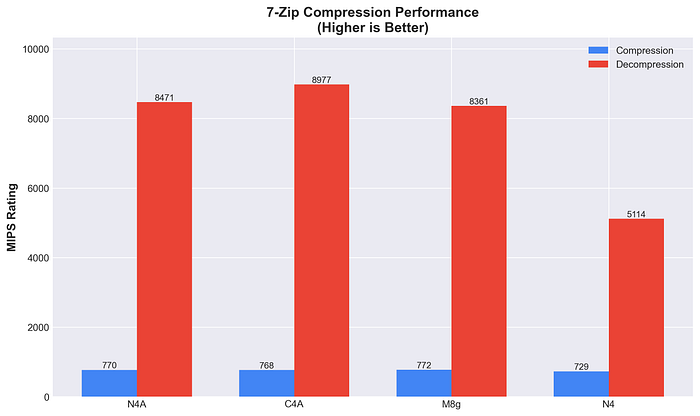
7-Zip 圧縮/解凍 MIPSレーティング
- C4A:圧縮768 / 解凍8977
- M8g:圧縮772 / 解凍8361
- N4A:圧縮770 / 解凍8471
- N4:圧縮729 / 解凍5114
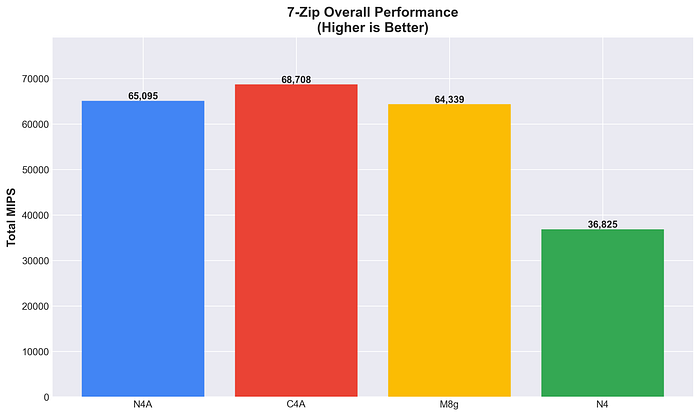
7-Zip 総合パフォーマンス
C4Aのパフォーマンス最適化は、圧縮workloadsで明確に表れています。N4Aはコスト最適化モデルでありながらM8gと肩を並べる性能を発揮し、優れたバランスを示しました。圧縮処理におけるArmの一貫した優位性(x86比75%以上)は、アーキテクチャ効率の高さを物語っています。
OpenSSLによる暗号処理性能
ハードウェアアクセラレーションを活用した暗号処理性能。
AES-256-GCMではC4Aが首位、続く2位はN4(44.5 GB/s)で、M8gとN4Aの両方を上回りました。AES暗号化workloadsでも十分な競争力を維持しています。
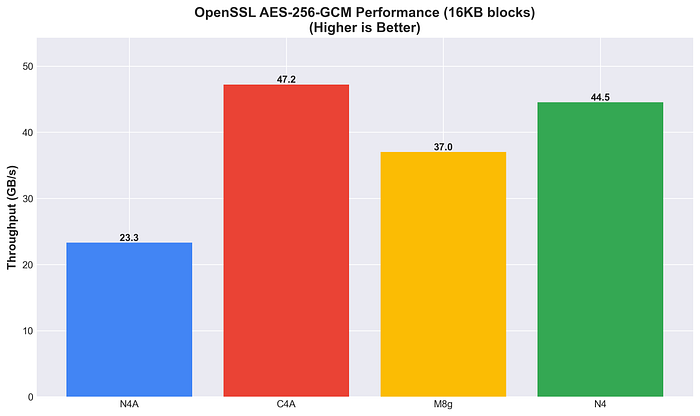
OpenSSL AES-256-GCM性能
一方、SHA256ハッシュ処理ではN4Aが首位(19.2 GB/s)に立ち、N4の2.8倍の性能を記録しました。
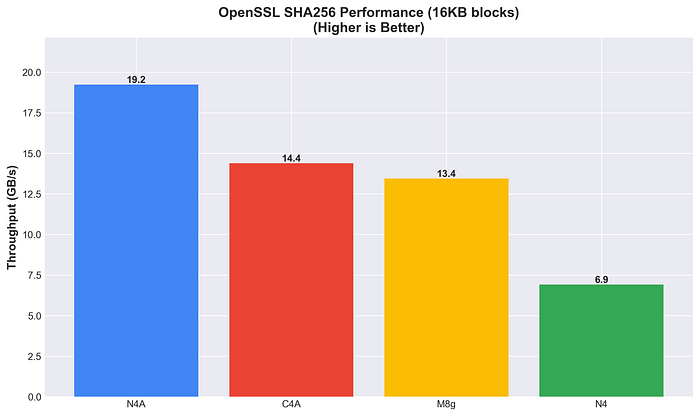
OpenSSL SHA256性能
ハードウェアアクセラレーションの効果はアルゴリズムによって大きく異なります。SHA256ハッシュ処理ではArmが明確な優位性(2〜3倍)を示しましたが、AES-256-GCM暗号化はもう少し複雑な様相です。
考察
N4 Intelをベースラインに、Arm勢(N4A、C4A、M8g)を比較してみましょう。
Arm同士の比較
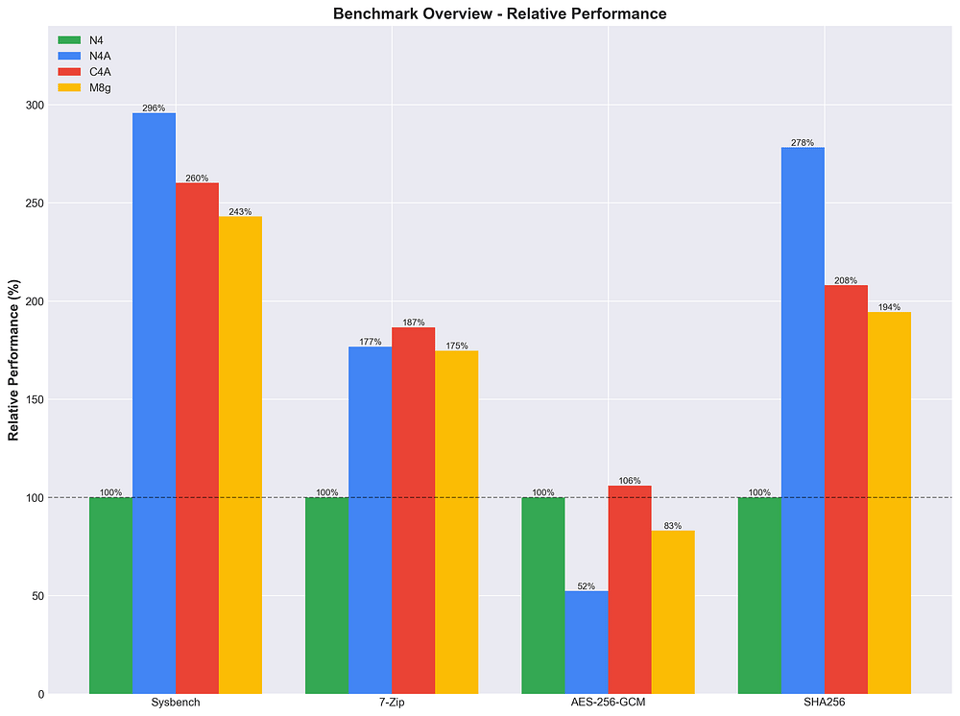
各種ストレステストにおけるN4、N4A、C4A、M8gの相対パフォーマンス(%)
N4Aの強み
- CPU演算(C4A比+13.7%)とSHA256ハッシュ(C4A比+34%)でリード
- 7-Zip圧縮でも十分な競争力
- AES-256-GCMスループットは控えめ(C4A比-51%)
- カスタムマシンタイプ(CMT)によるライトサイジングでコスト最適化が可能。これは現行のArmプラットフォームの中でもN4A独自の強みです——たとえばGraviton 4は事前定義されたインスタンスサイズしか提供されていません。
C4Aの強み
- AES-256-GCM暗号化(N4A比+102%)と7-Zip圧縮(N4A比+6%)でリード
- CPU性能も高水準だが、N4Aには一歩及ばず
M8gの位置づけ
- 多くのベンチマークで中間的なポジション
- CPUおよびハッシュ処理性能ではN4A、C4Aの両方を下回る
N4AはNeoverse N3が掲げる通り、コスト最適化された価格帯で効率性と演算workloadsに最適化されています。一方、Neoverse V2を搭載したC4Aは、パフォーマンス重視の価格帯で帯域幅集約型処理の最大スループットに最適化されています。
なぜN4AはSHA256でリードしAES-256-GCMでは劣るのか?
暗号処理の結果は、アーキテクチャ上のトレードオフも浮き彫りにしています。
N4AはSHA256ハッシュ処理ではリード(C4A比+34%)する一方、AES-256-GCM暗号化では大きく差をつけられています(C4A比-51%)。
AES-256-GCM——暗号化と認証を統合したスループット集約型のAEAD暗号
- 高いメモリ帯域幅と並列処理が必要
- 幅広い実行パイプラインとデュアル発行の暗号命令で性能を発揮
SHA256——演算集約型の反復ハッシュ処理
- 並列性が限定的な逐次演算(1ブロックあたり64ラウンド)
- メモリ帯域幅は低く、効率的な命令実行が効いてくる
暗号処理の種類によって最適なアーキテクチャは変わります。workloadに合わせて最適なインスタンスを選びましょう。
N4Aは、Armの最新の効率重視アーキテクチャ(Neoverse N3)を、コスト最適化されたパッケージで投入したGoogle Cloudの新製品です。今回のベンチマークでは、CPU性能とSHA256ハッシュ処理においてC4AとAWS Graviton4(M8g)の両方を上回りつつ、大規模フリートの最適化にふさわしい価格設定を実現していることが確認できました。
N4Aはus-central1リージョンで時間単価$0.0385(1vCPU/4GB)。これはC4Aの$0.0449より14%安い水準です。優れたCPU性能と組み合わせれば、コンピュートworkloadsの価格性能比は約33%向上します。
パフォーマンスが重要なworkloadsにはC4Aを、汎用workloadsにはN4Aを使い分けることで、アプリケーション性能を維持、あるいは向上させながらTCOを大幅に削減できます。100インスタンスのフリートをこの「better together」アプローチに切り替えれば、年間$48,000以上のコスト削減が見込めます。
関連リソース:ベンチマークツール | Google Cloud Axion | Arm Neoverse N3
DoiTのミッションは、お客様のクラウドインフラの継続的な最適化を支援することです。新しいAxionポートフォリオは、その実現に向けた強力な選択肢となります。今回登場したArmの新たな組み合わせを活用し、パフォーマンスが重要なworkloadsにはC4Aを、最大規模のフリートにはN4Aを使い分ける「better together」戦略を設計することで、コンピュートTCOの削減をお客様にご提案できます。

「better together」Axion戦略でコンピュートフリートの最適化にご興味のある方は、ぜひお気軽にご連絡ください!