Introduction
L'un des grands avantages de collaborer avec un Google Cloud Premier Partner comme DoiT, c'est de pouvoir accéder en avant-première aux nouvelles technologies — et cette fois, je vous parle
de la famille d'instances N4A, les VM polyvalentes basées sur Arm et propulsées par les processeurs Google Axion.
N4A marque l'évolution du portefeuille de processeurs Arm de Google, avec une distinction essentielle. Alors que C4A a été lancée en octobre 2024 comme la famille d'instances Axion optimisée pour la performance, N4A adopte une approche différente : c'est la famille Arm polyvalente optimisée pour le coût. Google propose désormais une stratégie Axion better together :
- C4A = Arm optimisé pour la performance, pour les workloads sensibles à la latence, à 0,0449 $/h pour 1v/4 Go
- N4A = Arm optimisé pour le coût, pour les flottes de calcul polyvalent, à 0,0385 $/h pour 1v/4 Go
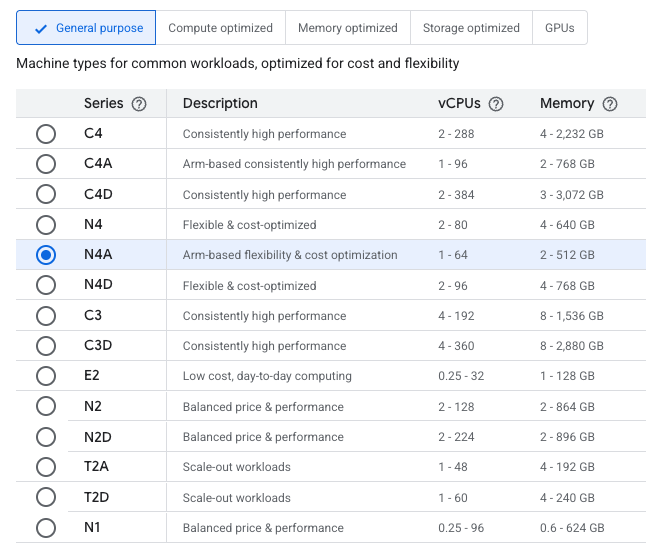
Compute Engine affichant l'option N4A
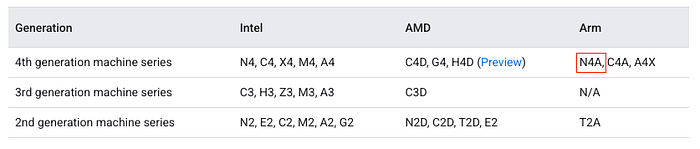
Documentation Google Cloud présentant la série N4A
Offre N4A pour les workloads polyvalents
J'ai passé ces derniers jours à confronter N4A à N4, C4A et la M8g d'AWS propulsée par Graviton4. Voici ce que les tests révèlent sur la place que mérite N4A dans votre infrastructure.

Liste CLI des VM lancées pour les tests
Méthodologie
Tous les benchmarks de cet article ont été réalisés sur :
- N4 : n4-standard-8 (Intel Xeon 5e génération — Emerald Rapids)
- N4A : n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A : c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g : m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Configuration :
- OS : Debian GNU/Linux 13 (trixie)
(ARM64 pour les instances Arm, x86_64 pour N4)
- Noyau : 6.12.48+deb13-cloud-arm64
- Instances neuves, sans tuning personnalisé.
Outils utilisés :
Sysbench pour les performances de calcul CPU
- Test multi-thread avec 8 threads
- Durée de 120 secondes
- Calcul de nombres premiers (max 20000)
- Métrique clé : événements / seconde
7-Zip pour un workload de compression en conditions réelles
- Compression/décompression multi-thread
- Mesure les performances en compression et en décompression
- Métrique clé : score MIPS total
OpenSSL pour les performances cryptographiques
- Mesure l'accélération crypto matérielle (un atout d'Arm)
- Algorithmes AES-256-GCM et SHA256
- Métrique clé : débit en Mo/s
Tous les tests ont été exécutés plusieurs fois, et les résultats correspondent aux valeurs médianes. Le script est disponible sur ce Gist.
Benchmarks
Performances CPU Sysbench
Débit de calcul CPU pur via le calcul de nombres premiers : plus c'est élevé, mieux c'est.
N4A offre les meilleures performances CPU brutes, devançant à la fois C4A (+13,7 %) et M8g (+21,7 %). L'architecture Neoverse N3 affiche d'excellentes performances de calcul.
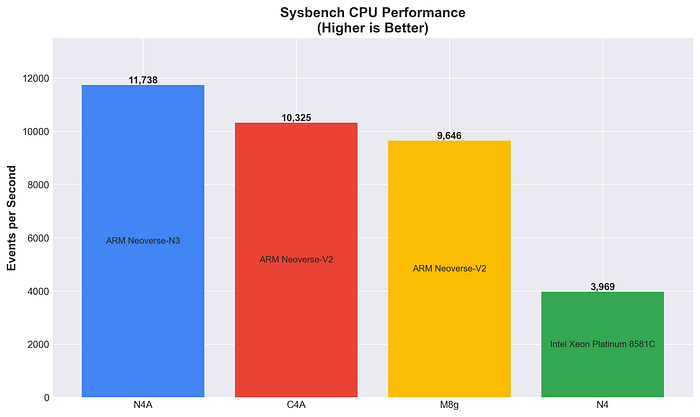
Performances CPU Sysbench
Rapport prix/performance
Les instances Arm affichent des performances de calcul 2,4 à 3 fois supérieures à celles d'Intel x86. L'architecture N3 de N4A délivre ~14 % de performances en plus que la V2 de C4A, signe d'une forte efficacité de calcul sur des workloads génériques.
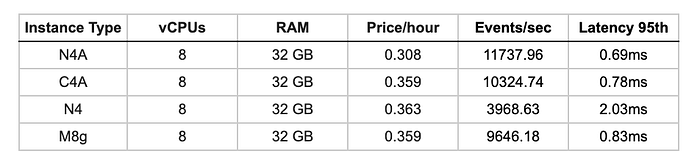
Compression 7-Zip
Performances réelles de compression/décompression, très courantes dans les workloads cloud : plus c'est élevé, mieux c'est.
C4A domine sur les workloads de compression, les autres affichant des performances similaires. Toutes les instances Arm surpassent largement N4 en décompression (75 à 87 % d'amélioration), comme on pouvait s'y attendre.
Score MIPS de compression / décompression 7-Zip
- C4A : 768 comp / 8977 décomp
- M8g : 772 comp / 8361 décomp
- N4A : 770 comp / 8471 décomp
- N4 : 729 comp / 5114 décomp
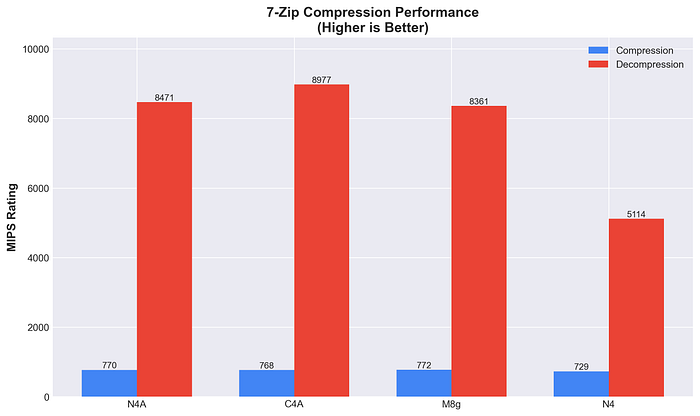
Performances globales 7-Zip
L'orientation performance de C4A se manifeste sur les workloads de compression. N4A se montre comparable à M8g malgré son orientation coût, signe d'un excellent équilibre. L'avantage constant d'Arm en compression (plus de 75 % par rapport à x86) traduit une réelle efficacité architecturale.
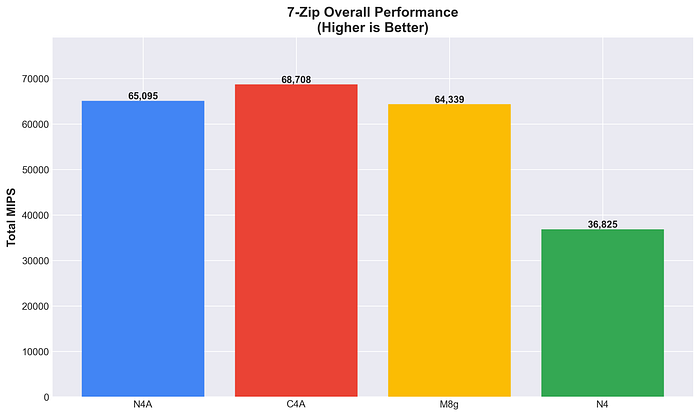
Performances cryptographiques OpenSSL
Performances de cryptographie avec accélération matérielle.
C4A domine en AES-256-GCM, et N4 arrive en deuxième position (44,5 Go/s), devançant à la fois M8g et N4A, tout en restant compétitif sur les workloads de chiffrement AES.
Performances OpenSSL AES-256-GCM
N4A, en revanche, prend la tête sur le hachage SHA256 (19,2 Go/s), avec des performances 2,8 fois supérieures à celles de N4.
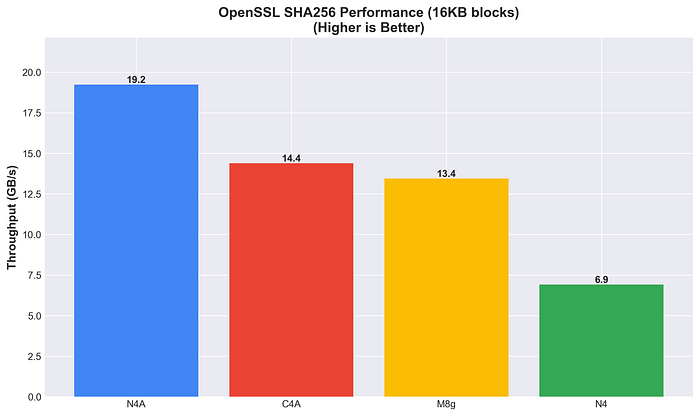
Performances OpenSSL SHA256
L'accélération matérielle varie selon l'algorithme. Le hachage SHA256 met en évidence un avantage net pour Arm (2 à 3x), tandis que le chiffrement AES-256-GCM est plus nuancé.
Analyses
Comparaison Arm complète (N4A, C4A et M8g), avec N4 Intel comme référence de base.
Comparaison Arm contre Arm
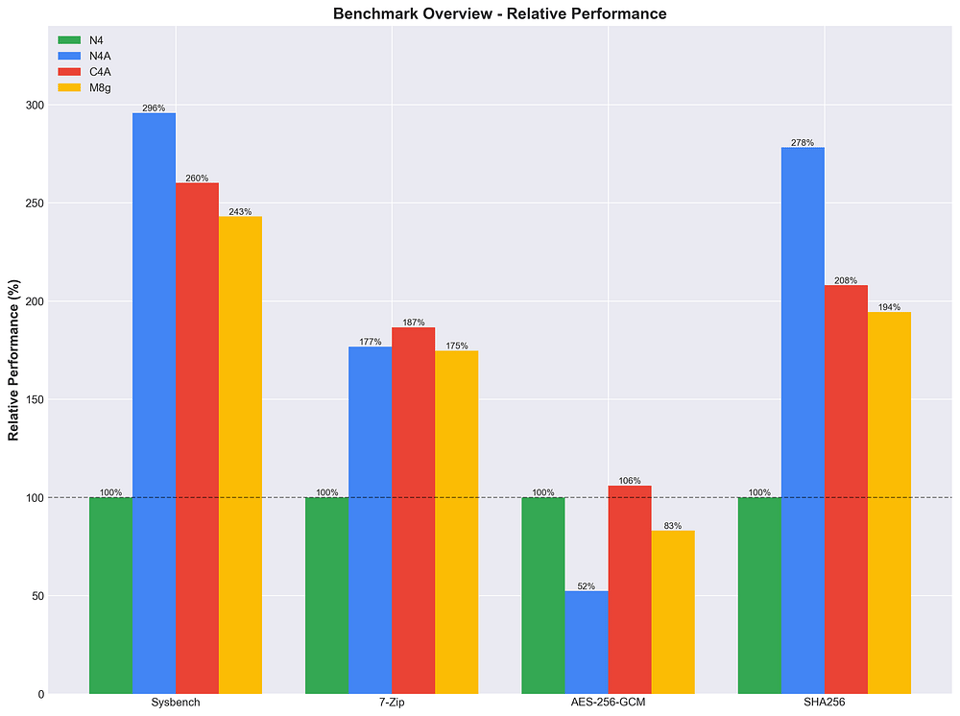
Performances relatives en % des instances N4, N4A, C4A et M8g sur plusieurs stress tests.
Atouts de N4A
- En tête sur le calcul CPU (+13,7 % vs C4A) et le hachage SHA256 (+34 % vs C4A)
- Compétitif en compression 7-Zip
- Débit AES-256-GCM plus faible (-51 % vs C4A)
- Avantage du right-sizing avec les Custom Machine Types (CMT) pour l'optimisation des coûts ; une fonctionnalité propre à N4A parmi toutes les autres plateformes Arm disponibles — Graviton 4, par exemple, ne propose que des tailles d'instance prédéfinies.
Atouts de C4A
- En tête sur le chiffrement AES-256-GCM (+102 % vs N4A) et la compression 7-Zip (+6 % vs N4A)
- Solides performances CPU, mais derrière N4A
Position de M8g
- Position intermédiaire sur la majorité des benchmarks
- Derrière N4A et C4A en performances CPU et hachage
Conformément à la promesse du Neoverse N3, N4A privilégie l'efficacité et les workloads de calcul à un tarif optimisé pour le coût. C4A, avec le Neoverse V2, vise le débit maximal sur les opérations gourmandes en bande passante, à un tarif positionné sur la performance.
Pourquoi N4A domine sur SHA256 mais pas sur AES-256-GCM ?
Les résultats crypto révèlent aussi des arbitrages architecturaux.
N4A est en tête sur le hachage SHA256 (+34 % vs C4A) mais accuse un net retard sur le chiffrement AES-256-GCM (-51 % vs C4A).
AES-256-GCM — Chiffrement AEAD intensif en débit, combinant chiffrement et authentification
- Exige une bande passante mémoire élevée et du traitement parallèle
- Tire parti de pipelines d'exécution larges et d'instructions crypto à double émission.
SHA256 — Hachage itératif intensif en calcul
- Opérations séquentielles à parallélisme limité (64 rounds par bloc)
- Faible bande passante mémoire, tire parti d'une exécution d'instructions efficace
Chaque opération cryptographique a son architecture de prédilection : mieux vaut donc associer chaque workload à l'instance adéquate !
Avec N4A, Google Cloud apporte sur le marché la dernière architecture Arm optimisée pour l'efficacité (Neoverse N3), dans un format pensé pour le coût. Nos benchmarks montrent qu'elle surpasse à la fois C4A et AWS Graviton4 (M8g) sur les performances CPU et le hachage SHA256, tout en étant tarifée pour l'optimisation de flottes à grande échelle.
N4A est facturée 0,0385 $/h (1v/4 Go) en us-central1, soit 14 % de moins que les 0,0449 $/h de C4A. Combiné à des performances CPU supérieures, cela représente environ ~33 % de meilleur rapport prix/performance pour vos workloads de calcul.
En réservant C4A aux workloads critiques en performance et N4A aux workloads polyvalents, vous pouvez réduire substantiellement votre TCO tout en maintenant — voire en améliorant — les performances applicatives. Une flotte de 100 instances qui bascule sur cette approche better together peut économiser plus de 48 000 $ par an.
Ressources : Outil de benchmark | Google Cloud Axion | Arm Neoverse N3
Chez DoiT, notre mission est d'aider nos clients à optimiser en continu leur infrastructure cloud, et le nouveau portefeuille Axion offre un puissant levier supplémentaire pour cette optimisation. Avec cette nouvelle combinaison Arm, nous pouvons concevoir une stratégie better together : C4A pour les workloads critiques en performance, et N4A pour aider les clients à réduire le TCO de calcul sur leurs plus grandes flottes.

Vous souhaitez optimiser votre flotte de calcul avec la stratégie Axion better together ? Dans ce cas, contactez-moi, parlons-en !