Introdução
Uma das grandes vantagens de trabalhar com um Google Cloud Premier Partner como a DoiT é ter acesso antecipado a novas tecnologias — e desta vez vou falar sobre
a família de instâncias N4A, as VMs de uso geral baseadas em Arm e equipadas com os Google Axion Processors.
A N4A representa a evolução do portfólio de processadores Arm do Google, com uma diferença importante. Enquanto a C4A foi lançada em outubro de 2024 como a família de instâncias com Axion otimizada para performance, a N4A segue outro caminho: é a família Arm de uso geral otimizada para custo. Com isso, o Google passa a oferecer uma estratégia Axion "better together":
- C4A = Arm otimizado para performance, voltado a workloads sensíveis à latência, a US$ 0,0449/h por 1v/4GB
- N4A = Arm otimizado para custo, voltado a frotas de computação de uso geral, a US$ 0,0385/h por 1v/4GB
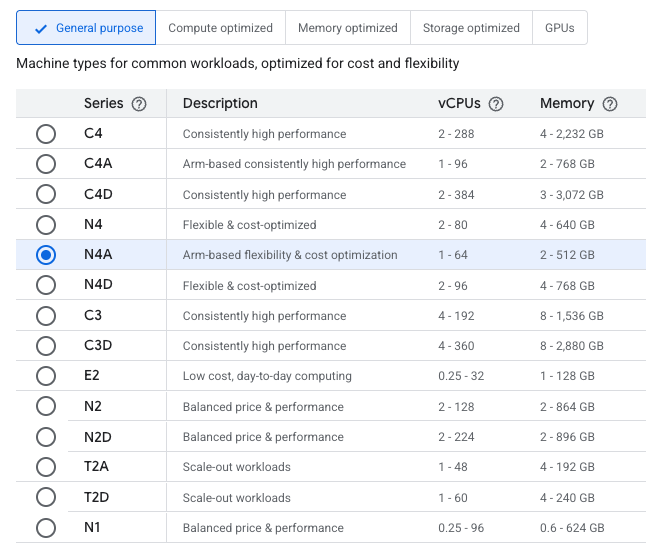
Compute Engine exibindo a opção N4A
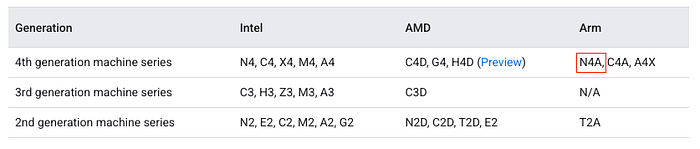
Documentação do Google Cloud mostrando a série N4A
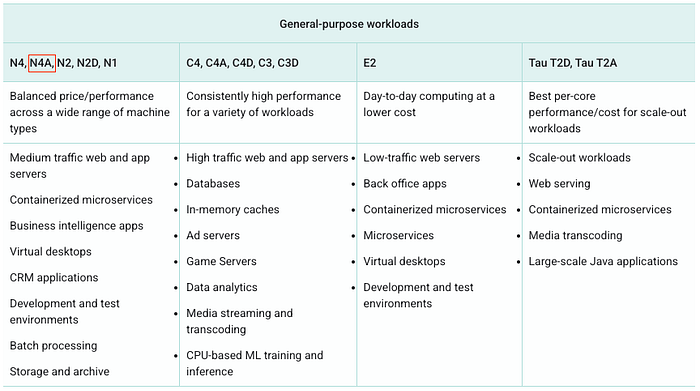
Oferta N4A para workloads de uso geral
Passei os últimos dias colocando a N4A à prova contra a N4, a C4A e a M8g da AWS, equipada com Graviton4. Veja o que os testes revelaram sobre se a N4A merece um espaço na sua infraestrutura.

Listagem via CLI das VMs em execução para os testes
Metodologia
Todos os benchmarks deste artigo foram executados em:
- N4: n4-standard-8 (Intel Xeon 5ª geração — Emerald Rapids)
- N4A: n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A: c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g: m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Configuração:
- SO: Debian GNU/Linux 13 (trixie)
(ARM64 para instâncias Arm, x86_64 para a N4)
- Kernel: 6.12.48+deb13-cloud-arm64
- Instâncias novas, sem ajustes personalizados.
Ferramentas usadas:
Sysbench para performance computacional de CPU
- Teste multithread com 8 threads
- Duração de 120 segundos
- Cálculo de números primos (máx. 20000)
- Métrica principal: eventos por segundo
7-Zip para workloads reais de compressão
- Compressão/descompressão multithread
- Avalia a performance tanto de compressão quanto de descompressão
- Métrica principal: total de MIPS
OpenSSL para performance criptográfica
- Avalia a aceleração criptográfica em hardware (vantagem do Arm)
- Algoritmos AES-256-GCM e SHA256
- Métrica principal: throughput em MB/s
Todos os testes foram executados várias vezes e os resultados representam os valores medianos. O script está disponível neste Gist.
Benchmarks
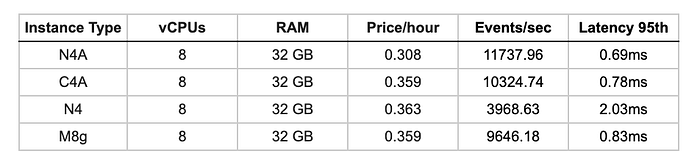
Performance de CPU no Sysbench
Throughput puro de CPU usando cálculo de números primos — quanto maior, melhor.
A N4A entrega a maior performance bruta de CPU, superando tanto a C4A (+13,7%) quanto a M8g (+21,7%). A arquitetura Neoverse N3 mostra uma performance computacional excelente.
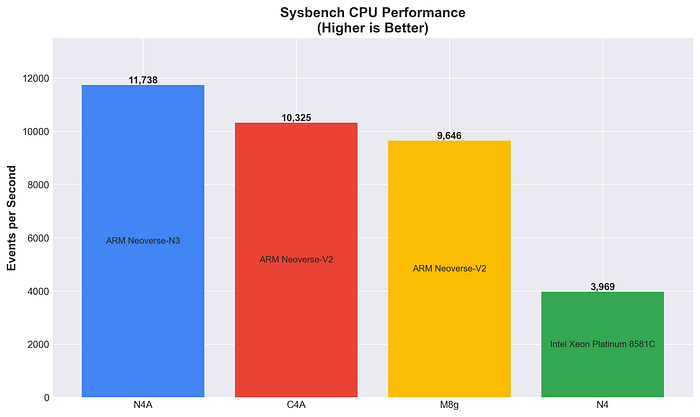
Performance de CPU no Sysbench
Relação preço/performance
As instâncias Arm têm performance computacional de 2,4 a 3x melhor que as Intel x86. A arquitetura N3 da N4A entrega ~14% mais performance que a V2 da C4A, mostrando uma eficiência computacional sólida em workloads genéricos.
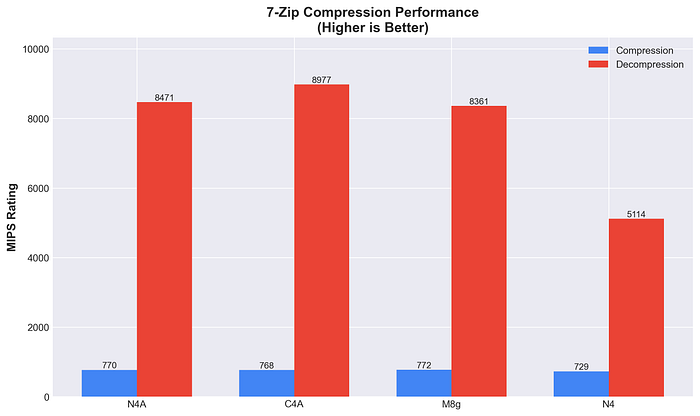
Compressão com 7-Zip
Performance real de compressão/descompressão, muito comum em workloads em nuvem — quanto maior, melhor.
A C4A lidera nos workloads de compressão, com as demais apresentando performance parecida. Todas as instâncias Arm superam significativamente a N4 em tarefas de descompressão (ganho de 75 a 87%), como esperado.
MIPS de compressão / descompressão no 7-Zip
- C4A: 768 comp / 8977 descomp
- M8g: 772 comp / 8361 descomp
- N4A: 770 comp / 8471 descomp
- N4: 729 comp / 5114 descomp
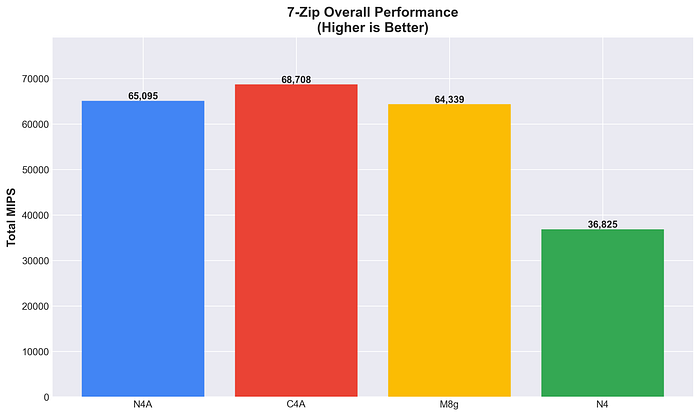
Performance geral no 7-Zip
A otimização de performance da C4A se reflete nos workloads de compressão. A N4A tem performance parecida com a da M8g, mesmo sendo otimizada para custo, e mostra um ótimo equilíbrio. A vantagem consistente do Arm em compressão (mais de 75% sobre o x86) comprova a eficiência da arquitetura.
Performance criptográfica no OpenSSL
Performance de criptografia acelerada por hardware.
A C4A lidera no AES-256-GCM e a N4 aparece em segundo lugar (44,5 GB/s), superando tanto a M8g quanto a N4A, e ainda se mantém competitiva em workloads de criptografia AES.
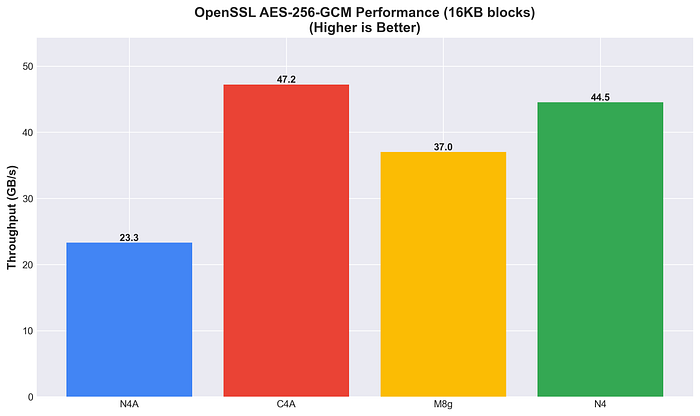
Performance OpenSSL AES-256-GCM
Já a N4A lidera no hashing SHA256 (19,2 GB/s), com performance 2,8x melhor que a N4.
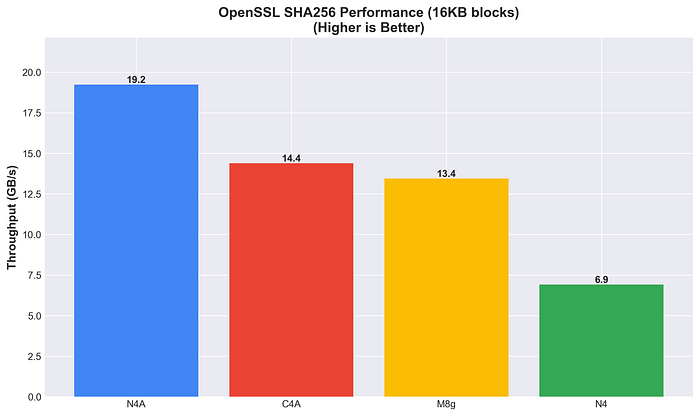
Performance OpenSSL SHA256
A aceleração por hardware varia conforme o algoritmo. O hashing SHA256 mostra vantagens claras do Arm (2 a 3x), enquanto na criptografia AES-256-GCM o cenário é mais sutil.
Insights
Olhando para a comparação completa entre as Arm (N4A, C4A e M8g), com a N4 Intel servindo de referência base.
Comparação Arm vs. Arm
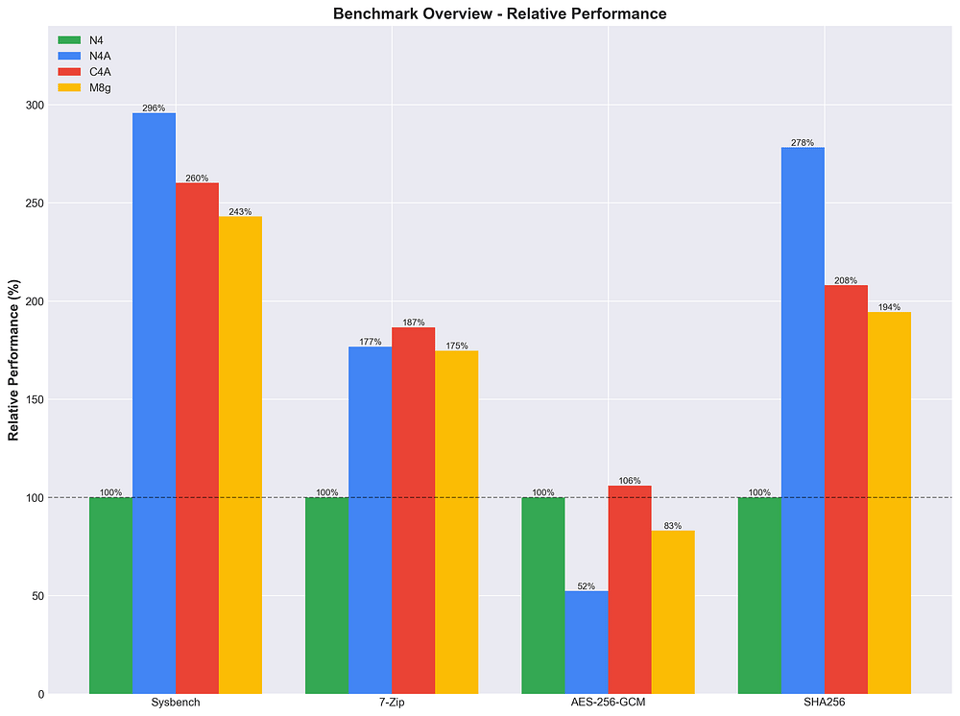
Performance relativa em % das instâncias N4, N4A, C4A e M8g em diversos testes de stress.
Pontos fortes da N4A
- Lidera em computação de CPU (+13,7% vs. C4A) e hashing SHA256 (+34% vs. C4A)
- Competitiva na compressão com 7-Zip
- Throughput menor em AES-256-GCM (-51% vs. C4A)
- Vantagem de right-sizing com Custom Machine Types (CMT) para otimização de custos; um recurso exclusivo da N4A entre todas as plataformas Arm disponíveis — o Graviton 4, por exemplo, só oferece tamanhos predefinidos de instância.
Pontos fortes da C4A
- Lidera em criptografia AES-256-GCM (+102% vs. N4A) e na compressão com 7-Zip (+6% vs. N4A)
- Boa performance de CPU, mas atrás da N4A
Posição da M8g
- Meio-termo na maior parte dos benchmarks
- Fica atrás de N4A e C4A em performance de CPU e hashing
A N4A, conforme prometido pelo Neoverse N3, é otimizada para eficiência e workloads computacionais, com preço otimizado para custo. Já a C4A, com o Neoverse V2, é otimizada para máxima vazão em operações intensivas em largura de banda, com preço de nível performance.
Por que a N4A lidera no SHA256, mas não no AES-256-GCM?
Os resultados de criptografia também revelam trade-offs arquiteturais.
A N4A lidera no hashing SHA256 (+34% vs. C4A), mas fica bem atrás na criptografia AES-256-GCM (-51% vs. C4A).
AES-256-GCM — cifra AEAD intensiva em throughput, que combina criptografia + autenticação
- Exige alta largura de banda de memória e processamento paralelo
- Aproveita pipelines de execução amplos e instruções criptográficas dual-issue.
SHA256 — hashing iterativo intensivo em computação
- Operações sequenciais com paralelismo limitado (64 rounds por bloco)
- Baixa largura de banda de memória; aproveita execução eficiente de instruções
Operações criptográficas diferentes favorecem arquiteturas diferentes, então o ideal é casar cada workload com a instância certa!
Com a N4A, o Google Cloud traz ao mercado a arquitetura Arm mais recente otimizada para eficiência (Neoverse N3) em um pacote pensado para custo. Nossos benchmarks mostram que ela supera tanto a C4A quanto o AWS Graviton4 (M8g) em performance de CPU e hashing SHA256, com preço pensado para otimização de frotas em larga escala.
A N4A custa US$ 0,0385/h (1v/4GB) na região us-central1, ou seja, 14% menos que os US$ 0,0449/h da C4A. Somado à performance superior de CPU, isso entrega cerca de ~33% mais preço-performance para os seus workloads de computação.
Usando a C4A nos workloads críticos em performance e a N4A nos de uso geral, dá para reduzir o TCO de forma significativa, mantendo — ou até melhorando — a performance da aplicação. Uma frota de 100 instâncias que adote essa abordagem "better together" pode economizar mais de US$ 48.000 por ano.
Recursos: Ferramenta de Benchmark | Google Cloud Axion | Arm Neoverse N3
Nossa missão na DoiT é ajudar os clientes a otimizar continuamente sua infraestrutura em nuvem, e o novo portfólio Axion é uma alavanca poderosa para isso. Com essa nova combinação Arm, dá para arquitetar uma estratégia "better together", usando a C4A nos workloads críticos em performance e a N4A para ajudar os clientes a reduzir o TCO de computação nas frotas maiores.

Quer otimizar sua frota de computação com a estratégia Axion "better together"? Então me chame e vamos conversar!