Einleitung
Ein klarer Vorteil der Zusammenarbeit mit einem Google Cloud Premier Partner wie DoiT: Wir bekommen frühzeitig Zugang zu neuen Technologien – und diesmal geht es um
die N4A-Instanzfamilie, Arm-basierte Allzweck-VMs auf Basis der Google Axion Processors.
N4A ist die Weiterentwicklung von Googles Arm-Prozessor-Portfolio mit einem entscheidenden Unterschied: Während C4A im Oktober 2024 als performance-optimierte, Axion-basierte Instanzfamilie startete, geht N4A einen anderen Weg – als kostenoptimierte Arm-Allzweckfamilie. Damit fährt Google nun eine "better together"-Strategie rund um Axion:
- C4A = performance-optimiertes Arm für latenzkritische Workloads, 0,0449 $/Std. bei 1v/4GB
- N4A = kostenoptimiertes Arm für Allzweck-Compute-Flotten, 0,0385 $/Std. bei 1v/4GB
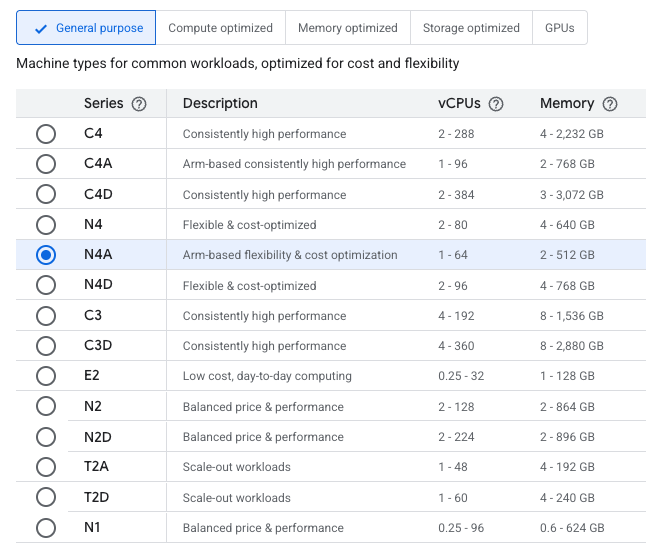
Compute Engine mit der N4A-Option
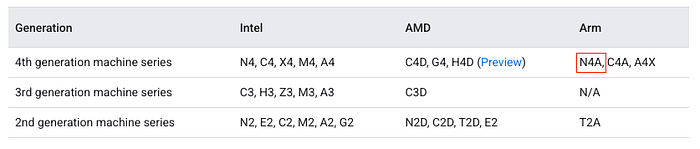
Google-Cloud-Dokumentation zur N4A-Serie
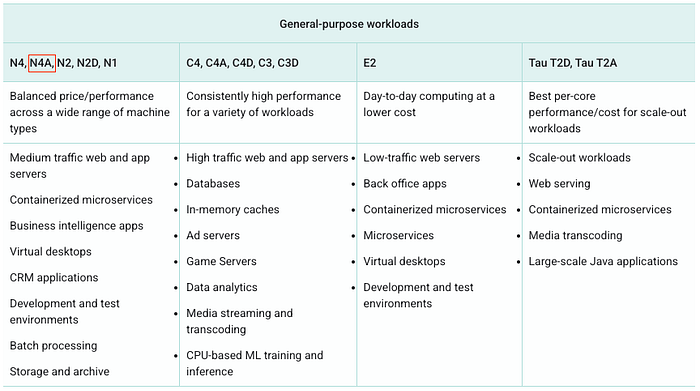
N4A für Allzweck-Workloads
Ich habe N4A in den letzten Tagen gegen N4, C4A und das Graviton4-basierte M8g von AWS antreten lassen. Was die Tests sagen – und ob N4A einen Platz in Ihrer Infrastruktur verdient – lesen Sie hier.

CLI-Auflistung der getesteten VMs
Methodik
Alle Benchmarks in diesem Artikel liefen auf folgenden Instanzen:
- N4: n4-standard-8 (Intel Xeon 5th Gen – Emerald Rapids)
- N4A: n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A: c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g: m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Konfiguration:
- OS: Debian GNU/Linux 13 (trixie)
(ARM64 für Arm-Instanzen, x86_64 für N4)
- Kernel: 6.12.48+deb13-cloud-arm64
- Frische Instanzen, kein eigenes Tuning.
Eingesetzte Tools:
Sysbench für CPU-Rechenleistung
- Multi-Threaded-Test mit 8 Threads
- Dauer: 120 Sekunden
- Primzahlberechnung (max. 20000)
- Kennzahl: Events/Sekunde
7-Zip für praxisnahe Komprimierungs-Workloads
- Multi-Threaded-Komprimierung/-Dekomprimierung
- Misst Komprimierungs- und Dekomprimierungsleistung
- Kennzahl: Gesamt-MIPS-Wert
OpenSSL für Krypto-Leistung
- Misst Hardware-Krypto-Beschleunigung (Arm-Stärke)
- Algorithmen: AES-256-GCM und SHA256
- Kennzahl: Durchsatz in MB/s
Jeder Test lief mehrfach; angegeben sind die Medianwerte. Das Skript steht als Gist bereit.
Benchmarks
Sysbench CPU-Leistung
Reiner CPU-Rechendurchsatz über Primzahlberechnungen – höher ist besser.
N4A liefert die höchste Roh-CPU-Leistung und schlägt sowohl C4A (+13,7 %) als auch M8g (+21,7 %). Die Neoverse-N3-Architektur überzeugt mit hervorragender Rechenleistung.
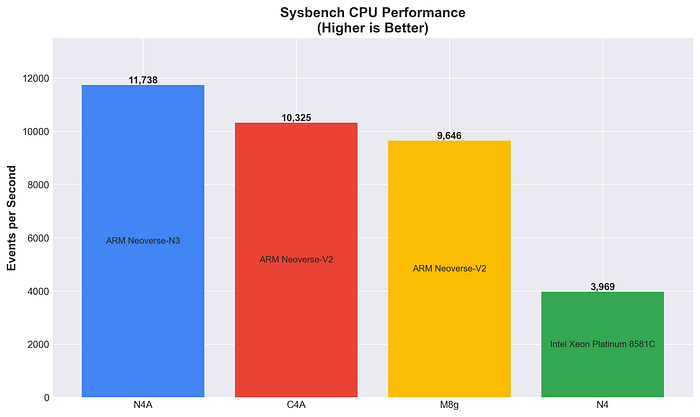
Sysbench CPU-Leistung
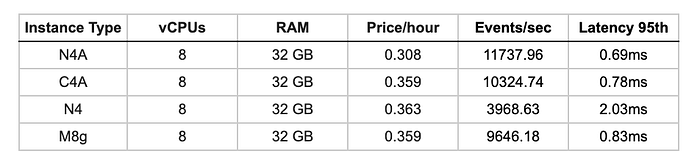
Preis-Leistungs-Verhältnis
Arm-Instanzen erreichen die 2,4- bis 3-fache Rechenleistung von Intel x86. Die N3-Architektur in N4A liefert ~14 % mehr Leistung als die V2 in C4A – ein deutlicher Beleg für hohe Recheneffizienz bei generischen Workloads.
7-Zip Komprimierung
Praxisnahe Komprimierungs-/Dekomprimierungsleistung – in Cloud-Workloads weit verbreitet, höher ist besser.
C4A führt bei Komprimierungs-Workloads, der Rest liegt eng beieinander. Bei Dekomprimierung schlagen alle Arm-Instanzen N4 klar (75–87 % Vorsprung) – wie erwartet.
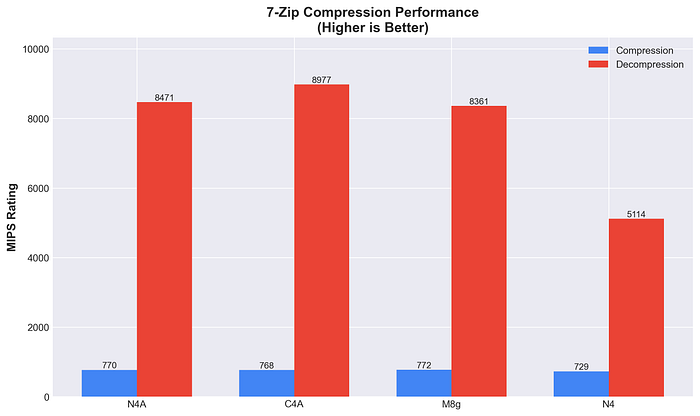
7-Zip Komprimierung/Dekomprimierung – MIPS-Wert
- C4A: 768 Komp. / 8977 Dekomp.
- M8g: 772 Komp. / 8361 Dekomp.
- N4A: 770 Komp. / 8471 Dekomp.
- N4: 729 Komp. / 5114 Dekomp.
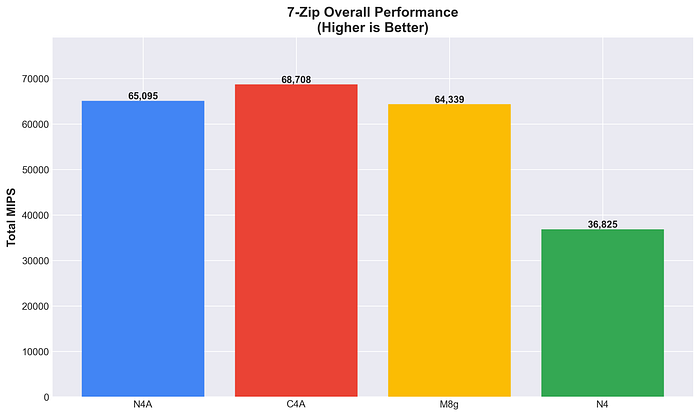
7-Zip Gesamtleistung
Die Performance-Optimierung von C4A wirkt sich bei Komprimierungs-Workloads aus. N4A liegt trotz Kostenoptimierung auf dem Niveau von M8g – eine sehr ausgewogene Vorstellung. Der durchgängige Arm-Vorsprung bei der Komprimierung (über 75 % gegenüber x86) belegt die architektonische Effizienz.
OpenSSL Krypto-Leistung
Hardware-beschleunigte Kryptografie.
C4A führt bei AES-256-GCM. N4 belegt mit 44,5 GB/s Platz zwei und schlägt damit sowohl M8g als auch N4A – auch bei AES-Verschlüsselungs-Workloads bleibt N4 konkurrenzfähig.
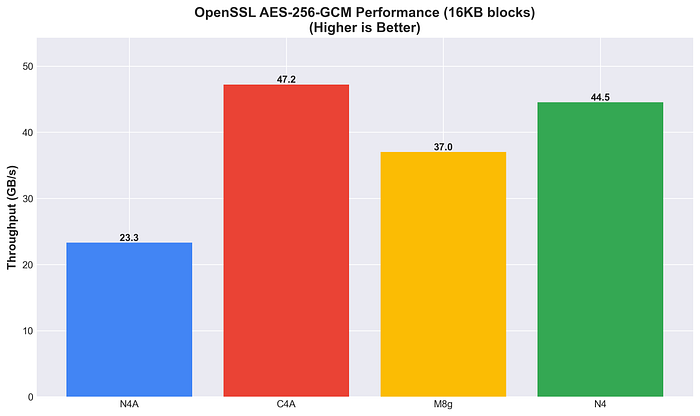
OpenSSL AES-256-GCM-Leistung
N4A hingegen führt beim SHA256-Hashing (19,2 GB/s) und ist damit 2,8-mal schneller als N4.
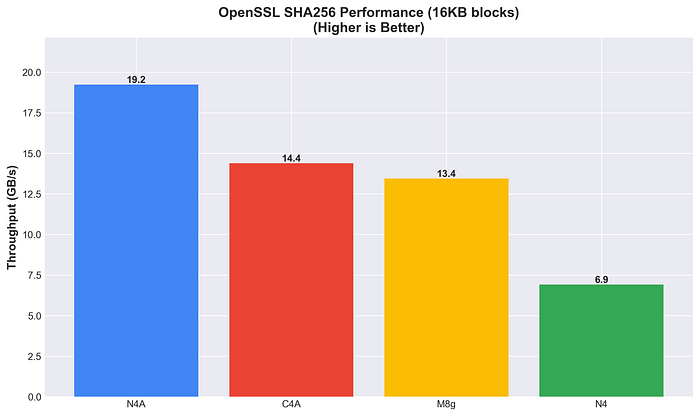
OpenSSL SHA256-Leistung
Die Hardware-Beschleunigung hängt stark vom Algorithmus ab. Beim SHA256-Hashing zeigt sich ein klarer Arm-Vorteil (Faktor 2–3), bei AES-256-GCM fällt das Bild differenzierter aus.
Erkenntnisse
Ein Blick auf den vollständigen Arm-Vergleich (N4A, C4A und M8g) mit dem Intel-basierten N4 als Baseline.
Arm gegen Arm im Vergleich
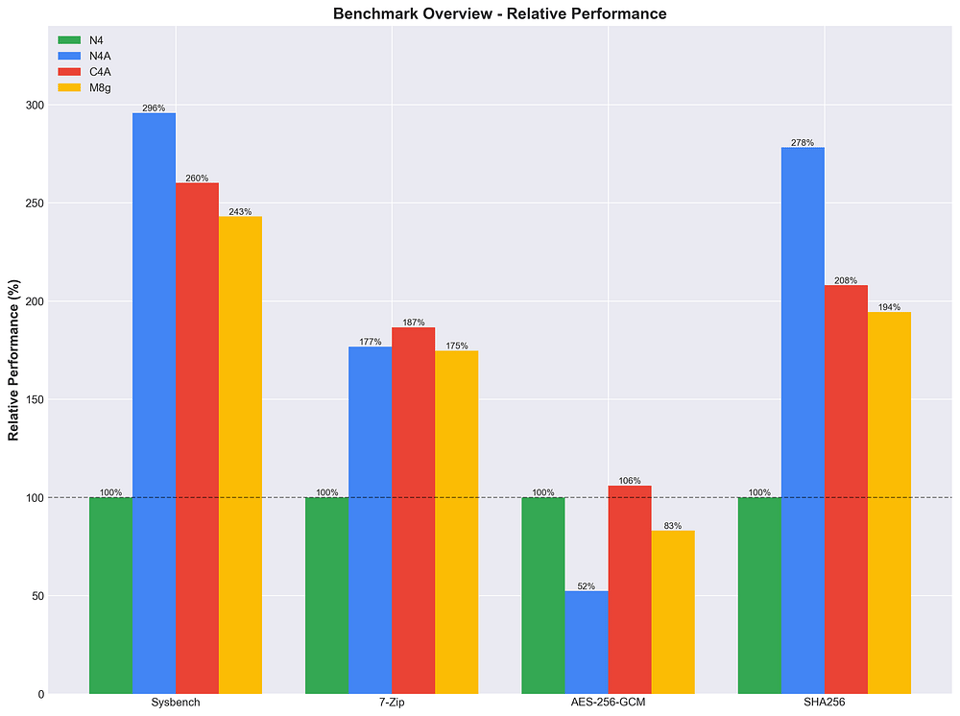
Relative Leistung in % der Instanzen N4, N4A, C4A und M8g über mehrere Stresstests hinweg.
Stärken von N4A
- Führend bei CPU-Berechnung (+13,7 % vs. C4A) und SHA256-Hashing (+34 % vs. C4A)
- Konkurrenzfähig bei der 7-Zip-Komprimierung
- Geringerer AES-256-GCM-Durchsatz (-51 % vs. C4A)
- Right-Sizing-Vorteil durch Custom Machine Types (CMT) zur Kostenoptimierung – ein Alleinstellungsmerkmal von N4A unter allen verfügbaren Arm-Plattformen. Graviton 4 etwa bietet ausschließlich vordefinierte Instanzgrößen.
Stärken von C4A
- Führend bei AES-256-GCM-Verschlüsselung (+102 % vs. N4A) und 7-Zip-Komprimierung (+6 % vs. N4A)
- Starke CPU-Leistung, liegt aber hinter N4A
Position von M8g
- Mittelfeld in den meisten Benchmarks
- Liegt bei CPU- und Hashing-Leistung sowohl hinter N4A als auch C4A
N4A ist – wie vom Neoverse N3 versprochen – auf Effizienz und Rechen-Workloads zu kostenoptimierten Preisen ausgelegt. C4A mit Neoverse V2 ist auf maximalen Durchsatz bei bandbreitenintensiven Operationen zu Performance-Tier-Preisen getrimmt.
Warum führt N4A bei SHA256, aber nicht bei AES-256-GCM?
Die Krypto-Ergebnisse legen die architektonischen Trade-offs offen.
N4A führt beim SHA256-Hashing (+34 % vs. C4A), schwächelt aber spürbar bei AES-256-GCM-Verschlüsselung (-51 % vs. C4A).
AES-256-GCM – durchsatzintensive AEAD-Chiffre, die Verschlüsselung und Authentifizierung verbindet
- Erfordert hohe Speicherbandbreite und Parallelverarbeitung
- Profitiert von breiten Execution-Pipelines und Dual-Issue-Krypto-Instruktionen
SHA256 – rechenintensives, iteratives Hashing
- Sequenzielle Operationen mit begrenzter Parallelität (64 Runden pro Block)
- Geringe Speicherbandbreite, profitiert von effizienter Befehlsausführung
Verschiedene Krypto-Operationen bevorzugen unterschiedliche Architekturen – wählen Sie für Ihren Workload also die passende Instanz!
Mit N4A bringt Google Cloud die neueste effizienzoptimierte Arm-Architektur (Neoverse N3) in einem kostenoptimierten Paket auf den Markt. Unsere Benchmarks zeigen: N4A schlägt sowohl C4A als auch AWS Graviton4 (M8g) bei CPU-Leistung und SHA256-Hashing – und ist preislich auf große Flotten zugeschnitten.
N4A kostet 0,0385 $/Std. (1v/4GB) in us-central1 – das sind 14 % weniger als die 0,0449 $/Std. bei C4A. Zusammen mit der höheren CPU-Leistung ergibt das ein um rund ~33 % besseres Preis-Leistungs-Verhältnis für Ihre Compute-Workloads.
Wer C4A für performance-kritische und N4A für Allzweck-Workloads einsetzt, senkt die TCO deutlich und hält die Anwendungsleistung mindestens stabil – oder verbessert sie sogar. Eine Flotte aus 100 Instanzen, die auf diesen "better together"-Ansatz wechselt, spart jährlich über 48.000 $.
Ressourcen: Benchmark-Tool | Google Cloud Axion | Arm Neoverse N3
Unsere Mission bei DoiT: Kunden dabei zu unterstützen, ihre Cloud-Infrastruktur kontinuierlich zu optimieren – und das neue Axion-Portfolio ist dafür ein wirkungsvoller Hebel. Mit dieser neuen Arm-Kombination lässt sich eine "better together"-Strategie umsetzen: C4A für performance-kritische Workloads und N4A, um die Compute-TCO bei den größten Flotten zu drücken.

Sie wollen Ihre Compute-Flotte mit der "better together"-Axion-Strategie optimieren? Dann schreiben Sie mir – sprechen wir darüber!