Introduzione
Uno dei vantaggi di lavorare con un Google Cloud Premier Partner come DoiT è poter accedere in anteprima alle nuove tecnologie — e questa volta è il turno
della famiglia di istanze N4A: VM general-purpose basate su architettura Arm e alimentate dai Google Axion Processors.
N4A segna l'evoluzione del portfolio di processori Arm di Google, con una distinzione fondamentale. Se C4A, lanciato a ottobre 2024, è la famiglia Axion ottimizzata per le prestazioni, N4A si posiziona invece come la famiglia Arm general-purpose ottimizzata per i costi. Google propone così una vera strategia Axion "better together":
- C4A = Arm ottimizzato per le prestazioni, pensato per workloads sensibili alla latenza, a 0,0449 $/h per 1v/4GB
- N4A = Arm ottimizzato per i costi, pensato per fleet di calcolo general-purpose, a 0,0385 $/h per 1v/4GB
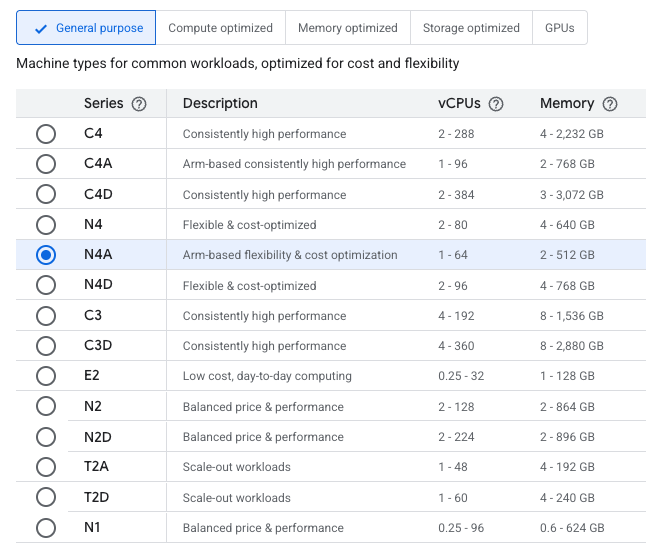
Compute Engine con l'opzione N4A in evidenza
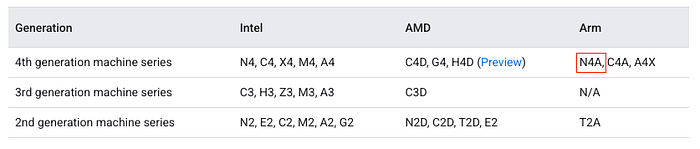
La documentazione di Google Cloud che illustra la serie N4A
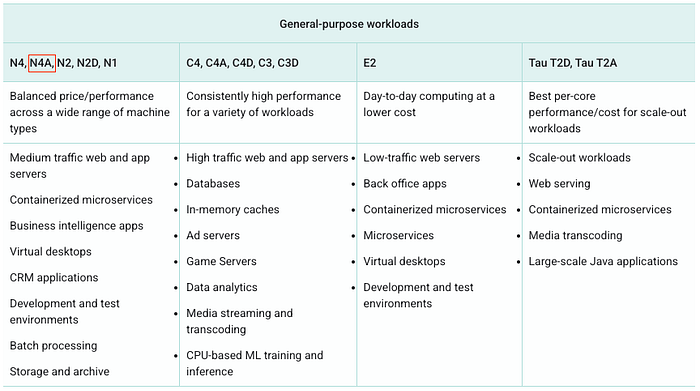
L'offerta N4A per workloads general-purpose
Negli ultimi giorni ho messo N4A sotto torchio, confrontandolo con N4, C4A e con la famiglia M8g di AWS basata su Graviton4. Ecco cosa raccontano i test, e se davvero N4A merita un posto nella Sua infrastruttura.

Elenco da CLI delle VM utilizzate per i test
Metodologia
Tutti i benchmark di questo articolo sono stati eseguiti su:
- N4: n4-standard-8 (Intel Xeon 5ª gen — Emerald Rapids)
- N4A: n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A: c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g: m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Configurazione:
- OS: Debian GNU/Linux 13 (trixie)
(ARM64 per le istanze Arm, x86_64 per N4)
- Kernel: 6.12.48+deb13-cloud-arm64
- Istanze appena create, senza tuning personalizzato.
Strumenti utilizzati:
Sysbench per le prestazioni computazionali della CPU
- Test multi-thread con 8 thread
- Durata 120 secondi
- Calcolo di numeri primi (max 20000)
- Metrica chiave: eventi al secondo
7-Zip per workloads reali di compressione
- Compressione/decompressione multi-thread
- Misura le prestazioni sia in compressione sia in decompressione
- Metrica chiave: punteggio MIPS totale
OpenSSL per le prestazioni crittografiche
- Misura l'accelerazione crittografica hardware (vantaggio di Arm)
- Algoritmi AES-256-GCM e SHA256
- Metrica chiave: throughput in MB/s
Ogni test è stato eseguito più volte e i risultati riportati sono i valori mediani. Lo script è disponibile in questo Gist.
Benchmark
Prestazioni CPU con Sysbench
Throughput computazionale puro della CPU tramite calcolo di numeri primi: più alto, meglio è.
N4A registra le prestazioni CPU grezze più elevate, superando sia C4A (+13,7%) sia M8g (+21,7%). L'architettura Neoverse N3 si dimostra ottima sul piano computazionale.
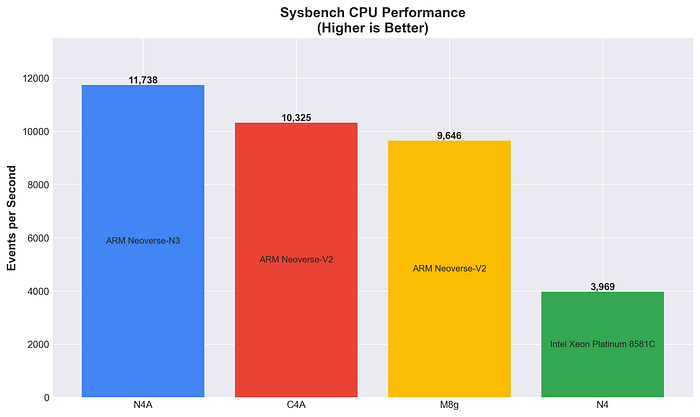
Prestazioni CPU con Sysbench
Rapporto prezzo/prestazioni
Le istanze Arm offrono prestazioni computazionali da 2,4 a 3 volte superiori rispetto a Intel x86. L'architettura N3 di N4A garantisce circa il 14% in più rispetto alla V2 di C4A, a conferma di un'ottima efficienza computazionale sui workloads generici.
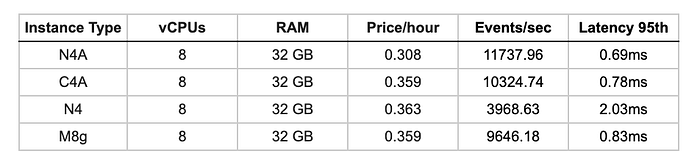
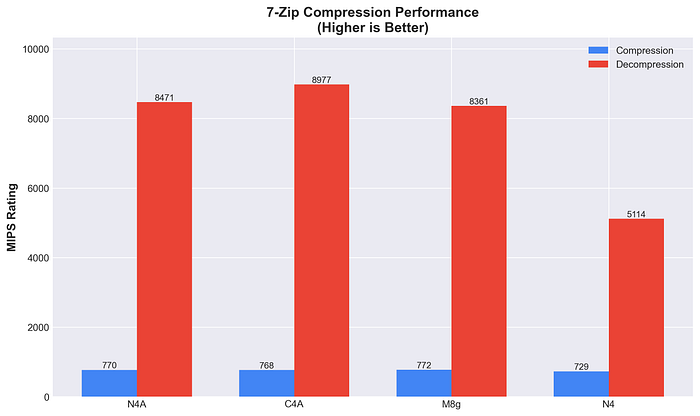
Compressione 7-Zip
Prestazioni reali di compressione/decompressione, scenario molto comune nei workloads in cloud: più alto, meglio è.
C4A guida nei workloads di compressione, mentre gli altri si attestano su valori simili. Tutte le istanze Arm staccano nettamente N4 in decompressione (miglioramento del 75–87%), come ci si poteva aspettare.
Punteggio MIPS in compressione/decompressione 7-Zip
- C4A: 768 comp / 8977 decomp
- M8g: 772 comp / 8361 decomp
- N4A: 770 comp / 8471 decomp
- N4: 729 comp / 5114 decomp
Prestazioni complessive 7-Zip
L'ottimizzazione prestazionale di C4A si vede nei workloads di compressione. N4A, pur essendo orientato al risparmio, regge il confronto con M8g, segno di un equilibrio notevole. Il vantaggio costante di Arm in compressione (oltre il 75% rispetto a x86) conferma l'efficienza dell'architettura.
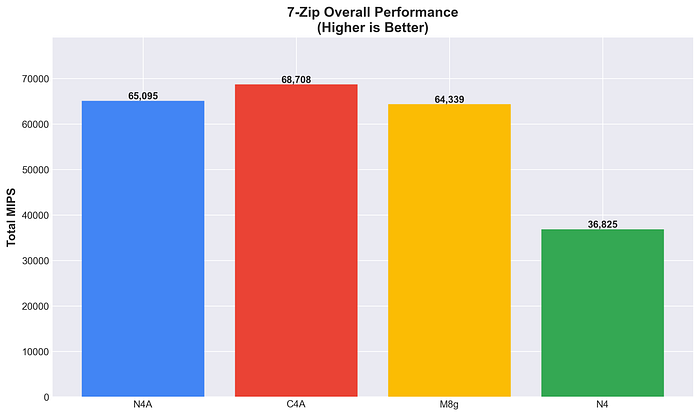
Prestazioni crittografiche con OpenSSL
Prestazioni crittografiche con accelerazione hardware.
C4A guida in AES-256-GCM, mentre N4 si piazza al secondo posto (44,5 GB/s) superando sia M8g sia N4A e restando comunque competitivo nei workloads di cifratura AES.
Prestazioni OpenSSL AES-256-GCM
N4A, dal canto suo, primeggia nell'hashing SHA256 (19,2 GB/s), con prestazioni 2,8 volte superiori a quelle di N4.
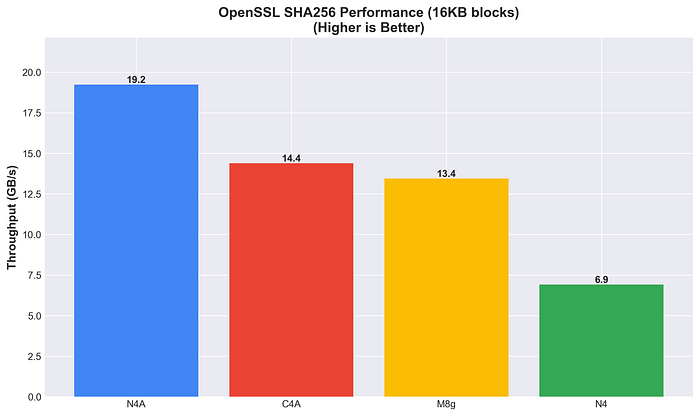
Prestazioni OpenSSL SHA256
L'accelerazione hardware varia a seconda dell'algoritmo. Nell'hashing SHA256 il vantaggio di Arm è netto (2–3x), mentre per la cifratura AES-256-GCM il quadro è più sfumato.
Approfondimenti
Vediamo il confronto completo tra le architetture Arm (N4A, C4A e M8g), tenendo come riferimento la N4 Intel.
Confronto Arm vs Arm
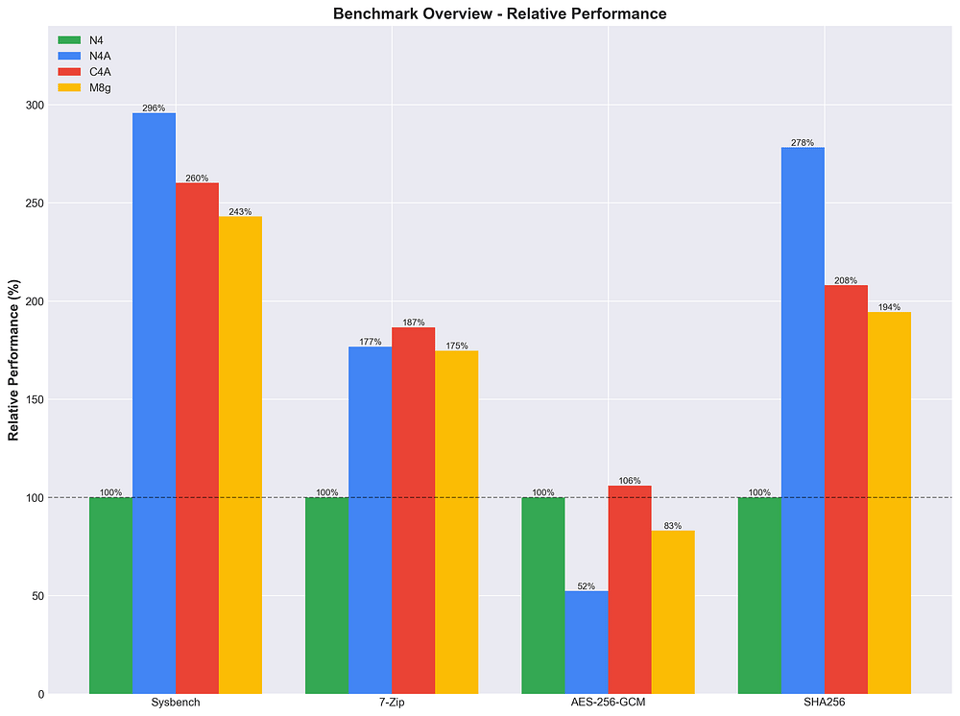
Prestazioni relative in % delle istanze N4, N4A, C4A e M8g in vari stress test.
Punti di forza di N4A
- In testa nel calcolo CPU (+13,7% vs C4A) e nell'hashing SHA256 (+34% vs C4A)
- Competitivo nella compressione 7-Zip
- Throughput AES-256-GCM più basso (-51% vs C4A)
- Vantaggio del right-sizing grazie ai Custom Machine Types (CMT) per l'ottimizzazione dei costi: una funzionalità esclusiva di N4A rispetto a tutte le altre piattaforme Arm sul mercato — Graviton 4, ad esempio, prevede solo dimensioni di istanza predefinite.
Punti di forza di C4A
- In testa nella cifratura AES-256-GCM (+102% vs N4A) e nella compressione 7-Zip (+6% vs N4A)
- Buone prestazioni CPU, ma inferiori a N4A
Posizionamento di M8g
- Posizione intermedia nella maggior parte dei benchmark
- Inferiore sia a N4A sia a C4A in CPU e hashing
N4A, come promesso dal Neoverse N3, è ottimizzato per efficienza e workloads computazionali, con un prezzo orientato al risparmio. C4A, con il Neoverse V2, punta al massimo throughput nelle operazioni a forte richiesta di banda, con un prezzo da fascia alta.
Perché N4A guida in SHA256 ma non in AES-256-GCM?
I risultati crittografici mettono in luce anche dei trade-off architetturali.
N4A primeggia nell'hashing SHA256 (+34% vs C4A) ma resta indietro nella cifratura AES-256-GCM (-51% vs C4A).
AES-256-GCM — cifrario AEAD ad alto throughput che combina cifratura e autenticazione
- Richiede elevata larghezza di banda della memoria ed elaborazione parallela
- Trae vantaggio da pipeline di esecuzione ampie e da istruzioni crittografiche dual-issue.
SHA256 — hashing iterativo a forte intensità di calcolo
- Operazioni sequenziali con parallelismo limitato (64 round per blocco)
- Bassa richiesta di banda di memoria, beneficia di un'esecuzione efficiente delle istruzioni
Operazioni crittografiche diverse prediligono architetture diverse: meglio abbinare il workload all'istanza giusta!
Con N4A, Google Cloud porta sul mercato l'ultima architettura Arm orientata all'efficienza (Neoverse N3) in una proposta pensata per il risparmio. I nostri benchmark mostrano che supera sia C4A sia AWS Graviton4 (M8g) nelle prestazioni CPU e nell'hashing SHA256, con un prezzo studiato per ottimizzare fleet su larga scala.
N4A è disponibile a 0,0385 $/h (1v/4GB) in us-central1, ovvero il 14% in meno rispetto ai 0,0449 $/h di C4A. Sommando questo dato a prestazioni CPU superiori, si ottiene un rapporto prezzo/prestazioni migliore di circa il 33% per i Suoi workloads di calcolo.
Usando C4A per i workloads performance-critical e N4A per quelli general-purpose, è possibile ridurre sensibilmente il TCO mantenendo, o addirittura migliorando, le prestazioni applicative. Una fleet di 100 istanze che adotta questo approccio "better together" può risparmiare oltre 48.000 $ all'anno.
Risorse: Tool di benchmark | Google Cloud Axion | Arm Neoverse N3
La missione di DoiT è aiutare i clienti a ottimizzare in modo continuo la propria infrastruttura cloud, e il nuovo portfolio Axion è una leva potentissima in questa direzione. Con questa nuova combinazione Arm possiamo progettare una strategia "better together": C4A per i workloads performance-critical e N4A per ridurre il TCO di calcolo sulle fleet più estese.

Le interessa ottimizzare la Sua fleet di calcolo con la strategia Axion "better together"? Mi scriva e ne parliamo!