Introducción
Una gran ventaja de trabajar con un Google Cloud Premier Partner como DoiT es contar con acceso anticipado a nuevas tecnologías, y esta vez te quiero hablar de
la familia de instancias N4A: las VMs de propósito general basadas en Arm y potenciadas por Google Axion Processors.
N4A representa la evolución del portfolio de procesadores Arm de Google, con una distinción clave. Mientras que C4A se lanzó en octubre de 2024 como la familia de instancias con Axion optimizada para rendimiento, N4A toma un camino distinto: es la familia Arm de propósito general optimizada en costos. Así, Google ahora ofrece una estrategia Axion de "better together":
- C4A = Arm optimizado para rendimiento, ideal para workloads sensibles a la latencia, a $0.0449/hr por 1v/4GB
- N4A = Arm optimizado en costos, pensado para flotas de cómputo de propósito general, a $0.0385/hr por 1v/4GB
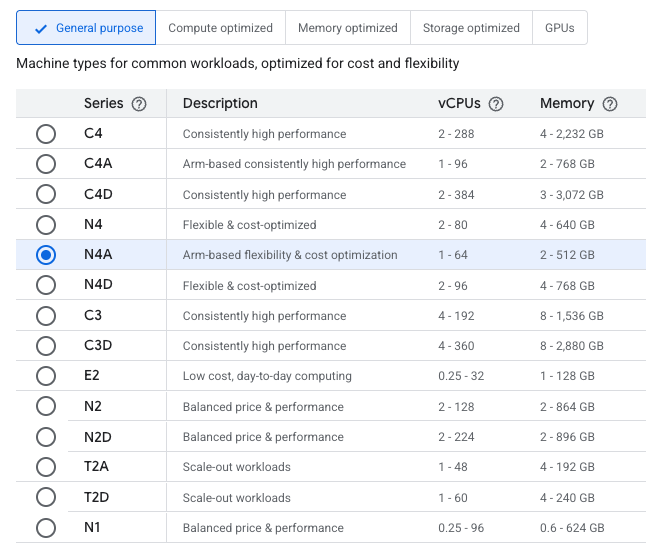
Compute Engine mostrando la opción N4A
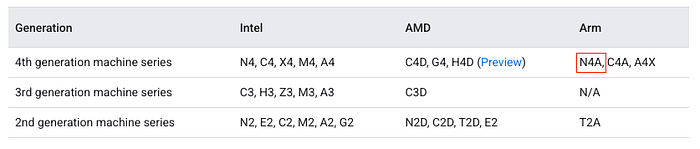
Documentación de Google Cloud con la serie N4A
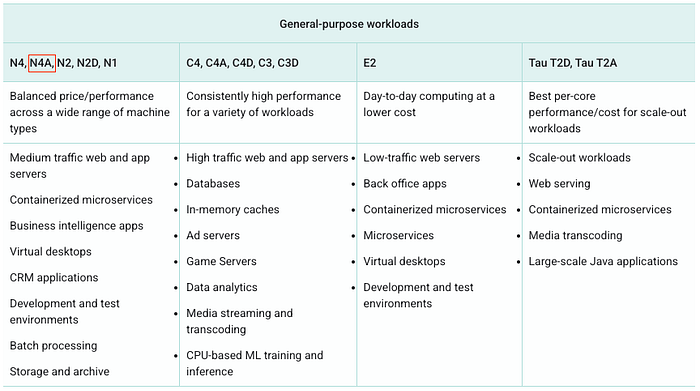
Oferta N4A para workloads de propósito general
Pasé los últimos días poniendo a prueba a N4A frente a N4, C4A y la M8g de AWS, esta última con Graviton4. Esto fue lo que arrojaron las pruebas sobre si N4A merece un lugar en tu infraestructura.

Listado por CLI de las VMs en ejecución para las pruebas
Metodología
Todos los benchmarks de este artículo se ejecutaron en:
- N4: n4-standard-8 (Intel Xeon 5ª Gen — Emerald Rapids)
- N4A: n4a-standard-8 (Google Axion / Arm Neoverse N3)
- C4A: c4a-standard-8 (Google Axion / Arm Neoverse V2)
- M8g: m8g.2xlarge (AWS Graviton4 / Arm Neoverse V2)
Configuración:
- SO: Debian GNU/Linux 13 (trixie)
(ARM64 para instancias Arm, x86_64 para N4)
- Kernel: 6.12.48+deb13-cloud-arm64
- Instancias nuevas, sin tuning personalizado.
Herramientas utilizadas:
Sysbench para medir el rendimiento computacional de la CPU
- Prueba multihilo con 8 hilos
- Duración de 120 segundos
- Cálculo de números primos (máx. 20000)
- Métrica clave: eventos por segundo
7-Zip para workloads reales de compresión
- Compresión y descompresión multihilo
- Mide el rendimiento tanto en compresión como en descompresión
- Métrica clave: rating total en MIPS
OpenSSL para rendimiento criptográfico
- Mide la aceleración criptográfica por hardware (una ventaja de Arm)
- Algoritmos AES-256-GCM y SHA256
- Métrica clave: throughput en MB/s
Cada prueba se ejecutó varias veces y los resultados corresponden a la mediana. El script está disponible en este Gist.
Benchmarks
Rendimiento de CPU con Sysbench
Throughput computacional puro de CPU mediante el cálculo de números primos: a mayor valor, mejor.
N4A entrega el mayor rendimiento bruto de CPU y supera tanto a C4A (+13.7%) como a M8g (+21.7%). La arquitectura Neoverse N3 muestra un desempeño computacional excelente.
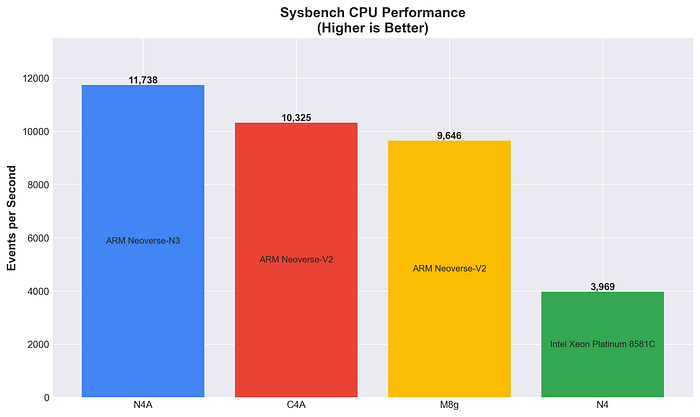
Rendimiento de CPU con Sysbench
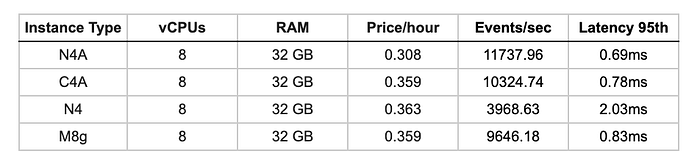
Relación precio-rendimiento
Las instancias Arm rinden entre 2.4 y 3 veces más que Intel x86 a nivel computacional. La arquitectura N3 de N4A entrega un ~14% más de rendimiento que la V2 de C4A, lo que confirma una sólida eficiencia computacional en workloads genéricos.
Compresión con 7-Zip
Rendimiento real de compresión y descompresión, muy frecuente en workloads en la nube: a mayor valor, mejor.
C4A lidera en workloads de compresión, mientras que el resto rinde de forma similar. Todas las instancias Arm superan claramente a N4 en tareas de descompresión (mejora del 75 al 87%), tal como se esperaba.
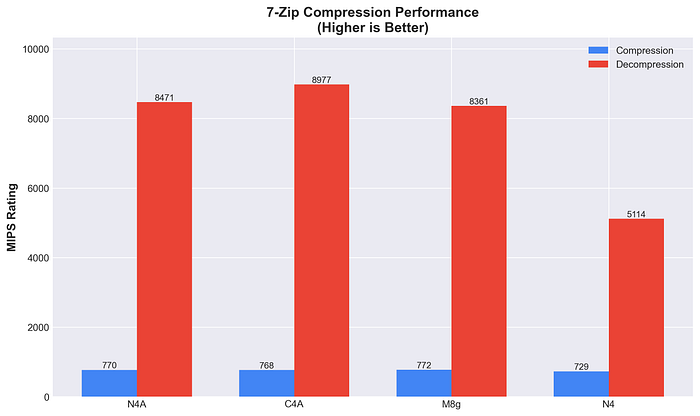
Rating en MIPS de compresión / descompresión con 7-Zip
- C4A: 768 comp / 8977 descomp
- M8g: 772 comp / 8361 descomp
- N4A: 770 comp / 8471 descomp
- N4: 729 comp / 5114 descomp
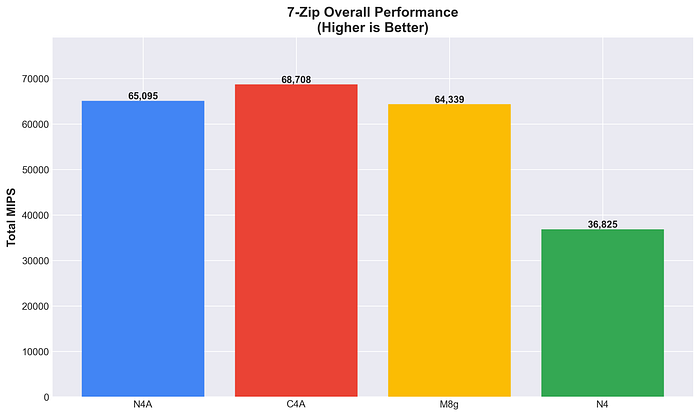
Rendimiento general de 7-Zip
La optimización de rendimiento de C4A se nota en los workloads de compresión. N4A rinde a la par de M8g a pesar de estar optimizada en costos, lo que muestra un gran balance. La ventaja consistente de Arm en compresión (más del 75% sobre x86) confirma su eficiencia arquitectónica.
Rendimiento criptográfico con OpenSSL
Rendimiento de criptografía acelerada por hardware.
C4A lidera en AES-256-GCM y N4 queda en segundo lugar (44.5 GB/s), por encima tanto de M8g como de N4A, y se mantiene competitiva en workloads de cifrado AES.
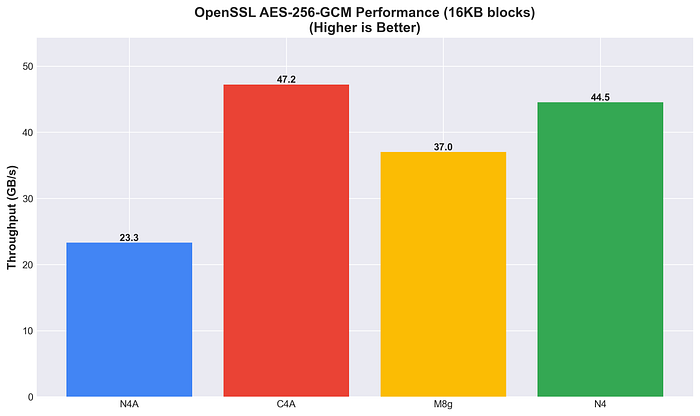
Rendimiento de OpenSSL en AES-256-GCM
Por su parte, N4A lidera en hashing SHA256 (19.2 GB/s), con un rendimiento 2.8 veces mayor que N4.
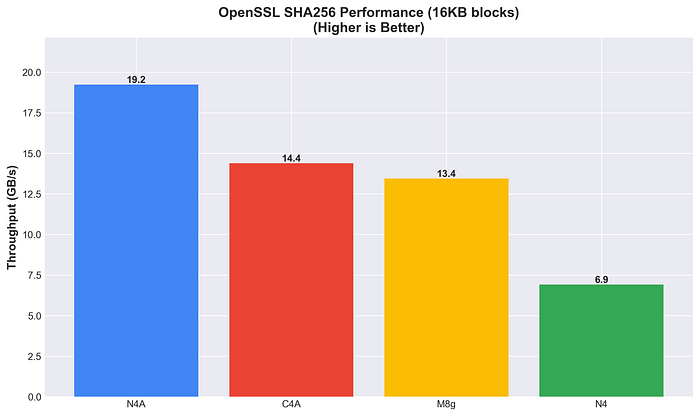
Rendimiento de OpenSSL en SHA256
La aceleración por hardware varía según el algoritmo. En hashing SHA256, Arm muestra ventajas claras (de 2 a 3 veces), mientras que en cifrado AES-256-GCM el panorama es más matizado.
Conclusiones del análisis
Veamos la comparación completa entre instancias Arm (N4A, C4A y M8g), con N4 Intel como referencia base.
Comparación Arm vs Arm
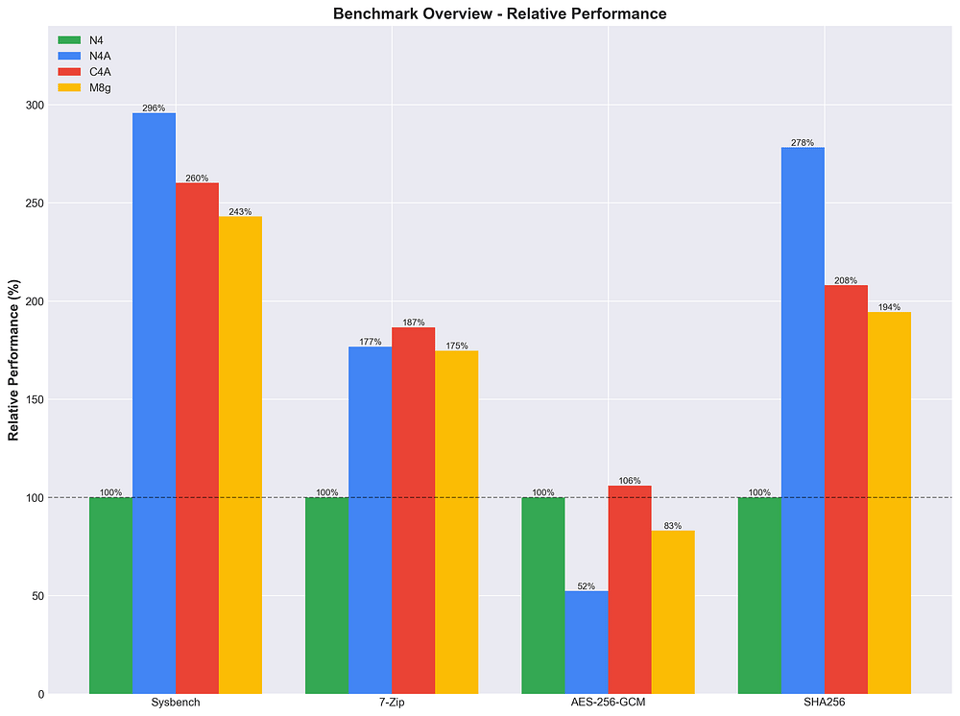
% de rendimiento relativo de las instancias N4, N4A, C4A y M8g en distintas pruebas de estrés.
Fortalezas de N4A
- Lidera en cómputo de CPU (+13.7% vs C4A) y en hashing SHA256 (+34% vs C4A)
- Competitiva en compresión con 7-Zip
- Menor throughput en AES-256-GCM (-51% vs C4A)
- Beneficio de right-sizing con Custom Machine Types (CMT) para optimizar costos; una característica única de N4A entre el resto de plataformas Arm disponibles. Por ejemplo, Graviton 4 solo ofrece tamaños de instancia predefinidos.
Fortalezas de C4A
- Lidera en cifrado AES-256-GCM (+102% vs N4A) y en compresión 7-Zip (+6% vs N4A)
- Sólido rendimiento de CPU, aunque por detrás de N4A
Posición de M8g
- Punto medio en la mayoría de los benchmarks
- Queda por detrás de N4A y C4A en rendimiento de CPU y hashing
N4A, tal como prometía el Neoverse N3, está optimizada para eficiencia y workloads computacionales con precios optimizados en costos. C4A, con el Neoverse V2, está optimizada para máximo throughput en operaciones intensivas en ancho de banda, con precios de gama de rendimiento.
¿Por qué N4A lidera en SHA256 y no en AES-256-GCM?
Los resultados criptográficos también revelan compensaciones arquitectónicas.
N4A lidera en hashing SHA256 (+34% vs C4A), pero se queda corta en cifrado AES-256-GCM (-51% vs C4A).
AES-256-GCM — Cifrado AEAD intensivo en throughput que combina cifrado y autenticación
- Requiere alto ancho de banda de memoria y procesamiento paralelo
- Se beneficia de pipelines de ejecución amplios e instrucciones criptográficas de doble emisión.
SHA256 — Hashing iterativo intensivo en cómputo
- Operaciones secuenciales con paralelismo limitado (64 rondas por bloque)
- Bajo ancho de banda de memoria; se beneficia de una ejecución eficiente de instrucciones
Las distintas operaciones criptográficas favorecen a distintas arquitecturas, así que conviene asignar cada workload a la instancia adecuada.
Con N4A, Google Cloud trae al mercado la última arquitectura Arm optimizada para eficiencia (Neoverse N3) en un paquete optimizado en costos. Nuestros benchmarks muestran que supera tanto a C4A como a AWS Graviton4 (M8g) en rendimiento de CPU y hashing SHA256, con un precio pensado para optimizar flotas a gran escala.
N4A tiene un precio de $0.0385/hr (1v/4GB) en us-central1, un 14% menos que los $0.0449/hr de C4A. Sumado a su mayor rendimiento de CPU, esto se traduce en una relación precio-rendimiento ~33% mejor para tus workloads de cómputo.
Al usar C4A para los workloads críticos en rendimiento y N4A para los de propósito general, se logra una reducción importante de TCO sin sacrificar (e incluso mejorando) el rendimiento de tus aplicaciones. Una flota de 100 instancias que adopte este enfoque "better together" puede ahorrar más de $48,000 al año.
Recursos: Herramienta de benchmark | Google Cloud Axion | Arm Neoverse N3
Nuestra misión en DoiT es ayudar a los clientes a optimizar de forma continua su infraestructura en la nube, y el nuevo portfolio Axion es una palanca poderosa para esa optimización. Con esta nueva combinación Arm, podemos diseñar una estrategia "better together": usar C4A para los workloads críticos en rendimiento y aprovechar N4A para reducir el TCO de cómputo en las flotas más grandes de nuestros clientes.

¿Te interesa optimizar tu flota de cómputo con la estrategia "better together" de Axion? Si es así, escríbeme y conversemos.