数年前、私はAIと機械学習(ML)への理解を深め、自社で活用できるようになりたい、少なくとも社内のデータサイエンスやエンジニアリングのチームと中身のある会話ができるようになりたいと考え、学習を始めました。
オンライン講座を受け、動画を見て、試験にも合格しました。それでも、機械学習を実際に自分のビジネスに組み込んで活用する方法が腹落ちした実感はなく、疑問が山積みのままでした。心当たりがある方は、ぜひこの先もお読みください。
デモ
本記事と後編を読み進めるきっかけとして、まずは実際に動く機械学習パイプラインのデモをご覧ください。
MLパイプラインとは一般に、データを整理・加工し、それを用いて機械学習モデルを学習させ、そのモデルをアプリケーションで提供(利用)するまでの一連のステップを指します。これらの用語が今ピンとこなくても大丈夫です。
このデモでは、ユーザーの入力から構造化データを生成する仕組みになっており、プロセスを分かりやすくしています——少なくともそうなっていれば幸いです。次回の記事では、ソースコードと設計・構築のアプローチを共有します。
Google Cloud Platform上でホストしたカスタムMLパイプラインアプリの4分間デモ
ML用語のギャップを埋める
私のようにソフトウェアエンジニアリングやプロダクトを背景に持つ人は、クラス、メソッド、関数、パラメータ、入力、リクエスト、変数、ループ、出力、戻り値、レスポンスといったお馴染みの言葉でやり取りしています。
機械学習の世界では、これに対応する用語として観測(observation)、モデル、次元(dimension)、特徴量(feature)、フィット(fit)、トレーニング、テスト、そして推論(inference)などがあります。さらにシータのようなギリシャ文字の数学記号まで出てくると、頭がくらくらしてきますよね。最初は圧倒されるかもしれませんが、進めながら少しずつ慣れていきましょう。
もっとも単純に言えば、機械学習モデルとは数値を入力すると数値を返す数学的な関数です。
今の教え方の問題は、技術の使い方を理解するまでに時間がかかりすぎることだと私は考えています。そこで、まずは次の3つの問いから始めましょう。
- この関数を実生活でどう使うのか(いわゆるサービング)?
- この関数をどう作るのか(いわゆるトレーニング)?
- どの問題にどの手法が向いているのか?
要点だけ先に
では早速、多くの教材とは逆の順番で答えを見ていきましょう。
1. モデルのサービング(アプリで関数を使う)
機械学習モデル、つまり関数はファイルに保存されます。ソフトウェアライブラリでそのファイルを開いて実行し、入力を受け取って結果を返すことができます。
モデルファイルは小さな「スプレッドシート」のようなものだと考えてください。一部のセルには数式が入っており、「スプレッドシート」に入力を渡すと値がセル(下図の黄色いセル)に入り、戻り値である予測値(下図の緑のセル)が計算されます。
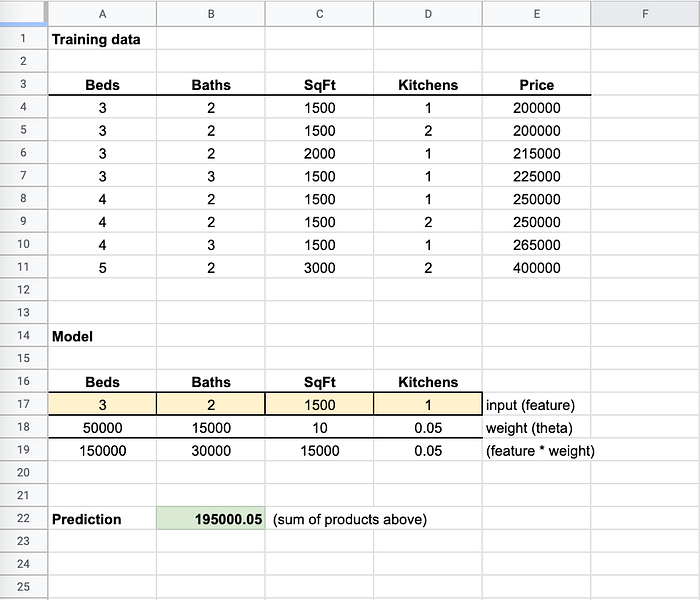
トレーニングは、予測値が実際の価格に近づくまで重みを変え続けます
下のトレーニングデータ(後ほど詳しく説明します)を見ると、キッチンが1つでも2つでも価格は変わっていません。そのため重み(係数)はほぼ0で、価格を決定するうえで重要な特徴量ではないことが分かります。
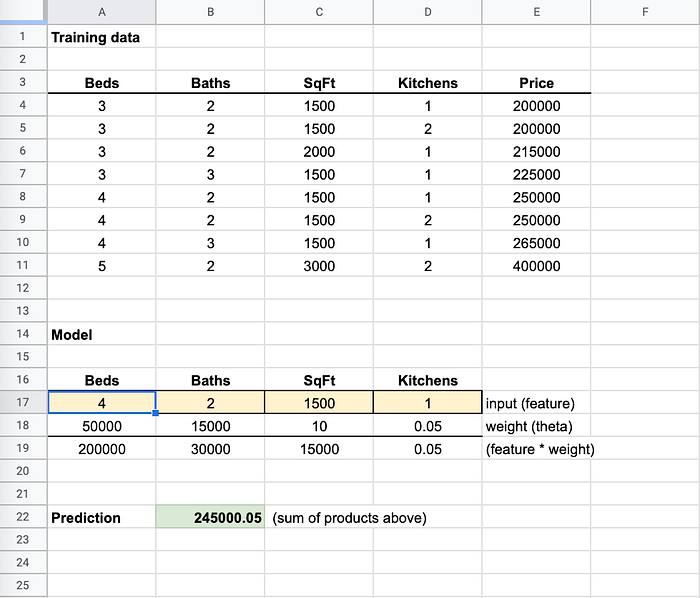
ベッド数を「4」に変更すると、トレーニングデータの250000にかなり近い値になります
「Beds」を「4」に変更すると、予測値は250,000に近づきました。MLアルゴリズムは、すべての入力でできるだけ正確な結果が出るよう、重みを微小な小数単位で調整します。そのため100%の精度になることはまずありません。
よく使われるモデルファイル形式にpickleがあり、それを作成・実行するツールにjoblibがあります。TensorFlowやPyTorchといった他のフレームワークは独自の形式を持ち、モデルの可搬性を高めるための統一形式の取り組みもあります。
上図のようにアプリケーションでモデルを使う(サービング)には、ファイル作成時に使ったライブラリと互換性のあるバージョンをインポートし、load()してから、他のソフトウェアの関数と同じようにpredict()を呼び出すだけ。後ほど動作するサンプルもお見せしますが、本当にこれだけです!
2. モデルのトレーニング(関数を作る)
後ほど詳しく説明しますが、食べ物を入力すると子どもがそれを気に入るかどうかを予測したい、と仮定してみてください。どこに着地するかは皆さんお察しの通りです(笑)
従来であれば、既知のルールを使って次のように手作業で関数を書いていたでしょう。
入力(特徴量)は、食べ物の属性——種類、匂い、辛さ、温度、糖度、色などです。予測される出力(推論)は「good」または「bad」のいずれかになります。
この関数を手作業で書く際の難点は、理想的な温度・甘さ・匂いを本当に把握できているのか、また子どもが「good」「bad」を判断するうえでどの要素が最も効くのかを見極められるのか、という点です。このやり方はせいぜい試行錯誤の域を出ません。
では、データが1万件あったらどうでしょう。それらすべての値を覚え、相関を取って、辛さ・温度・匂い・甘さの境目を見極めるのは、人の頭脳では到底不可能です。コンピュータにそのデータを渡せば、たいてい数秒で答えを導き出し、正しい予測を返す数学的関数を定義してくれます。これこそが機械学習の助けになる部分です。
MLモデルのトレーニング概要
ここではシンプルに、以下のコードで進めましょう。
これは機械学習とは何かを「解き明かす」ための単純化した例です。関数とルールを自分で書く代わりに、各入力値に異なる重みを反復的に掛けながら、ほとんどの場合に正しい答えを返すように調整していくアルゴリズムを使います(先ほどのスプレッドシートを思い出してください)。
仮に100件のレコードを入力したところ、食べ物の色が4のときは必ず結果が0(「bad」)になるというパターンが現れたとします。手作業で書いた関数にルールがあったように、関数自身がそうしたルールを発見しながら自らを書き上げていきます。応答(推論)が概ね正しくなるのは、すでに正解(ラベル)の付いたデータをもとに関数を作成(モデルをトレーニング)したからです。
1か月後、子どもが「ブロッコリーが好き」と言い出したとします。ブロッコリーは緑色なので、それを反映するように最初の関数を書き直さなければなりません。データが変われば変わるほど、この作業はどんどん大変になります。機械学習を使えば、新しい情報を投入し、精度の高い予測ができるようになるまで再トレーニングするだけで済みます。それが機械学習のもたらす力です。
3. どの問題にどの手法が向いているのか?
これは飛ばします。多くのAI講座はMLアルゴリズムの分類から入りますが、それは学習の妨げになると私は考えています。今は気にしないでください。まず全体像をつかみ、知識を広げるのは後からで十分です。
ここまでの振り返り
ここまでで押さえていただきたいのは、上のような関数を手作業で作り、「野菜なら悪い」といった条件を当て推量で設定しても、ある程度は正確な結果を得られるかもしれない、という点です。
予測の種類が複雑になり、スピードが求められ、考慮すべきデータ点が増えてくると、頭の中で安全に推測できる範囲を超えてきます。そこで機械学習の出番です。
用語
- モデル — 数値入力に固有の重みを掛けて数値結果を返す、コンピュータプログラムが生成する数学的関数。
- 特徴量(Feature) — 関数に渡して予測値を得るための数値入力またはパラメータ(次元とも呼ばれる)。
- ラベル(Label) — 過去データに対する既知の答え(クラスとも呼ばれる)。たとえば子どもの食の好みの例では、ピザとケーキは好き、ほうれん草は嫌いと分かっていたので、ピザとケーキにはgoodの値1を、ほうれん草にはbadの値0を割り当てました。
- 観測(Observation) — ある入力について収集された特徴量の集合。たとえばピザから抽出した特徴量がそれにあたります。
- 特徴量エンジニアリング — ある観測について結果に影響しそうな属性を特定し、それを数値に変換することで、手書きの関数ではなく数学的関数を構築できるようにする作業。今回の例では、色や食べ物の種類を文字列ではなく配列のインデックスで数値化しました(特徴量抽出とも呼ばれます)。
- トレーニング — データセットを繰り返し走査し、ほとんどの結果が正しくなるまで各特徴量にさまざまな重み(シータ)を試すこと。
- フィット(Fit) — 裏側でMLアルゴリズムが行っているのは、「good」と「bad」のレコードを分けられる線の座標を見つけることです。これにより、将来のレコードがその線の片側にプロットされれば「good」、反対側であれば「bad」と判定できます。実質的にこれがトレーニングの中身ですが、今は気にしなくて大丈夫です。
- 推論(Inference) — 厳密には「予測する行為」を指しますが、分かりやすさのため、ここではモデル関数が返す結果や予測値そのものと考えてください(つまり、これらのパラメータを与えると、この答えを推論する、ということ)。
- サービング — モデルファイルを読み込み、パラメータを渡して予測を返してもらうことで、関数をプログラムの中で利用すること。
- テスト — モデルにテスト用の特徴量を渡して予測を取得し、レコード群について既知の値(ラベル)と照合すること。
- 精度(Accuracy) — テストレコード全体のうち、期待された結果と一致した予測結果の割合。今後調べると良い用語:適合率(precision)と再現率(recall)。
今は重要度が低めですが、いずれ出てくる用語:
- シータ(Theta) — 結果への影響度合いに応じて各特徴量に掛け合わされる重み。分かりやすい例が住宅価格の予測です。寝室3部屋・キッチン2つの家の販売価格が20万ドル、寝室3部屋・キッチン1つでも20万ドル、寝室4部屋なら25万ドルだとします。モデルは、価格に効く寝室数の特徴量に高いシータ(重みまたは重要度)を、ほとんど影響のないキッチン数には低いシータを割り当てる、といった具合です。
- ハイパーパラメータチューニング — どの特徴量が結果により重要か(あるいは重要でないか)を把握している場合は、前処理や特徴量エンジニアリングのステップで自分なりの重みを適用し、予測精度をさらに高められます。狙いは、誤った予測に対する損失(ペナルティ)を最小化し、入力のばらつきに左右されにくい予測にすることです。マニアックな話なので、今は気にしなくて結構です。
プロセス
サービングとは、保存したモデルファイルを読み込んで実行できるソフトウェアライブラリ(たとえばjoblib)を使うことだと学びました。たとえばWeb APIで食べ物の種類、辛さ、甘さなどのパラメータを受け取る場合、モデルをload()してこれらのパラメータを渡すと、1か0をpredict()してくれます。APIはユーザーへのレスポンスで1を「good」、0を「bad」と解釈します。
また、モデルのトレーニングには特徴量エンジニアリングが必要になることも学びました。これは、対象の食べ物(観測)に関連し結果に影響を与えそうな値を特定し、その一部を数値に変換して数学的関数に投入できるようにする作業です。次に、精度を測るために既知(ラベル付き)のレコードを一部取り分けておき、精度が向上するまでモデルをトレーニング(フィット)させます。
では、実際の実装に入る前に、実用的な応用例を見ていきましょう。
ビジネス課題への機械学習の適用
身近な題材で説明するのが理解の近道です。あなたがWebサイトを運営していて、登録者(何かにサインアップしてくれる人)をもっと増やしたいとします。これまではGoogle、Facebook、テレビ、ラジオ、印刷広告に同額を投じてきました。来年も広告予算は同じで、新規純増の登録者を20%増やすために、どこにお金を使うのが最適かを知りたい、という状況です。
新規登録者を最大化するために、各媒体への広告費の配分割合を割り出す必要があります。
昨年の月別の新規登録者数を分析し、それぞれの流入元、コスト、登録件数を調べたところ、最も多い登録者がGoogle経由で、次にFacebook、テレビと続き、ラジオと印刷からは少数だと分かりました。ただし、その数は季節や月によって変動します。
同じ媒体で昨年と違う配分にしていたら、もっと登録者を獲得できたのでは?
Excelの「ゴールシーク」を使ったことはありますか?
従来、予算配分を最適化しようとすると、まずは推測や仮説から始め、スプレッドシートでシミュレーションを試みたかもしれません。昨年の結果を貼り付け、各行に各媒体への支出額、新規登録者数、獲得単価、その他重要そうなデータ点を並べ、値を何度も変えながら登録者数が増えるかを確かめていく、という具合です。
これがまさに、Excelに組み込まれている「ゴールシーク」機能が自動でやってくれることなのですが、利用している人や、機能の存在を知っている人は意外と多くありません。下の例のように目標を設定すると、出力セルが目標値に達するまで他のセルの値を反復的に変更してくれます。
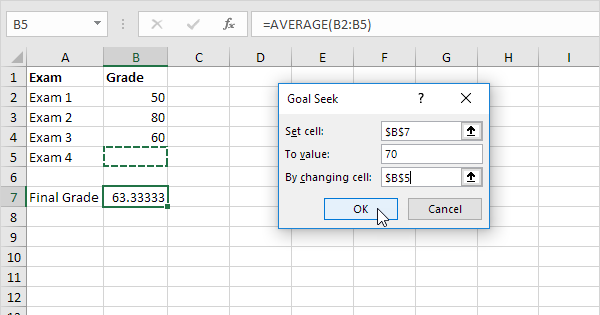
ゴールシークで最適値を探す
広告の例で言えば、各広告タイプの相対的な重要度を見極め、総予算に対する割合(または重み)を割り当てようとしているわけです。昨年の登録者数は分かっていて、同じ予算でその20%増を実現したい、という前提です。
これを目標値として設定し、各媒体への支出%を変えて目標達成を目指します。これがまさに機械学習モデルのトレーニング方法そのもの——データを反復処理し、値(入力パラメータに掛け合わされる重み)を変えながら、既知の答え(ラベル)に近づけていくのです。
すべてが理解できなくても心配いりません。実際にアプリケーションを触り、後編でさらに学んでからこの部分を読み返すと、(願わくば)腑に落ちてくるはずです。
機械学習は「ゴールシーク」を次のレベルへ
多くの試行錯誤の末、目標を達成する正しい組み合わせ(各広告タイプへの重みや割合)を見つけ出します。とはいえ、データが1日100件、365日で計36,500件あり、日によって特定の媒体が他より多くの登録を生み出すとしたらどうでしょう。媒体、曜日、年内日数、表示回数、クリック数、コンバージョン、登録、クリック単価や表示単価などを含む36,500行のデータの違いを把握するのは、ほぼ不可能です。
ある種の問題は人間が解くのに向いていない、ということが見えてきたかと思います。子どもの食の好みとは違い、こうした関数こそ自動化に最適な対象です。機械学習アルゴリズムは「ゴールシーク」によく似ていますが、複数のセルの値を一度に反復的に変更し、変更ごとに結果を試して、入力に対する出力値が既知の答え(ラベルまたはクラス)に近づくかをチェックできます。
上のデモがどう作られたか、ソースコードへのリンクとあわせて後編でご覧ください。
あとはあなたの番です!
- 興味を持ちそうな方に、ぜひシェアしてください。その方の役に立ちますし、私にとっても大きな励みになります!
- 50回の拍手をお願いします!(拍手ボタンを長押しするだけです。)
- お気軽にコメント 💬 もどうぞ。
