Vor einigen Jahren wollte ich mehr über KI und Machine Learning (ML) lernen – und herausfinden, wie ich beides in meinen eigenen Unternehmen einsetzen oder zumindest auf Augenhöhe mit unseren Data-Science- und Engineering-Teams diskutieren könnte.
Ich habe Online-Kurse besucht, Videos angesehen und Prüfungen bestanden – und hatte trotzdem nicht das Gefühl, wirklich verstanden zu haben, wie sich Machine Learning praktisch anwenden und in mein Geschäft integrieren lässt. So viele Fragen blieben offen. Wenn Ihnen das bekannt vorkommt, lesen Sie weiter.
Demo
Damit Sie Lust bekommen, diesen Artikel und Teil 2 der Reihe zu lesen, lehnen Sie sich kurz zurück und schauen Sie sich zunächst diese Demo einer funktionierenden Machine-Learning-Pipeline an.
Eine ML-Pipeline beschreibt man meist als die Abfolge von Schritten, mit denen Daten aufbereitet werden, um damit Machine-Learning-Modelle zu trainieren und diese Modelle anschließend in einer Anwendung bereitzustellen. Keine Sorge, falls diese Begriffe noch nichts sagen.
Diese Demo erzeugt ihre strukturierten Daten direkt aus Benutzereingaben und vereinfacht so – zumindest hoffe ich das – den Einstieg. Im nächsten Artikel teile ich den Quellcode und den Ansatz hinter Design und Umsetzung.
Vierminütige Demo einer eigenen ML-Pipeline-App, gehostet auf Google Cloud Platform
Die Vokabel-Lücke im ML schließen
Die meisten, die wie ich aus dem Software-Engineering oder Produktbereich kommen, sprechen eine vertraute Sprache mit Begriffen wie Class, Method, Function, Parameter, Input, Request, Variable, Loop, Output, Return und Response.
In der Welt des Machine Learning gibt es entsprechende Begriffe wie Observation, Model, Dimension, Feature, Fit, Train, Test und Inference. Kommen dann noch griechische Symbole wie Theta hinzu, beginnt der Kopf zu rauchen. Das wirkt anfangs erschlagend, aber wir tasten uns Schritt für Schritt an diese Begriffe heran.
In seiner einfachsten Form ist ein Machine-Learning-Modell eine mathematische Funktion, die bei numerischen Eingaben einen numerischen Wert zurückgibt.
Ich glaube, ein Problem heutiger Lehrmethoden ist, dass es viel zu lange dauert, bis man versteht, wie man die Technologie tatsächlich einsetzt. Deshalb starten wir mit diesen Fragen:
- Wie nutze ich diese Funktion in der Praxis (auch Serving genannt)?
- Wie erstelle ich diese Funktion (auch Training genannt)?
- Welche Techniken eignen sich am besten für welche Probleme?
TL;DR
Legen wir direkt los – und beantworten diese Fragen in der umgekehrten Reihenfolge, in der sie üblicherweise vermittelt werden.
1. Modelle bereitstellen (Ihre Funktion in einer App nutzen)
Machine-Learning-Modelle, also Funktionen, werden in Dateien gespeichert. Software-Bibliotheken können sie öffnen, ausführen, Eingaben entgegennehmen und Ergebnisse zurückgeben.
Stellen Sie sich diese Modelldateien wie kleine "Tabellen" vor. Einige Zellen enthalten Formeln. Wenn Sie eine Eingabe an die "Tabelle" übergeben, landen Ihre Werte in bestimmten Zellen (etwa den gelben weiter unten), und es wird ein Rückgabewert berechnet – Ihre Prediction (wie die grüne Zelle unten).
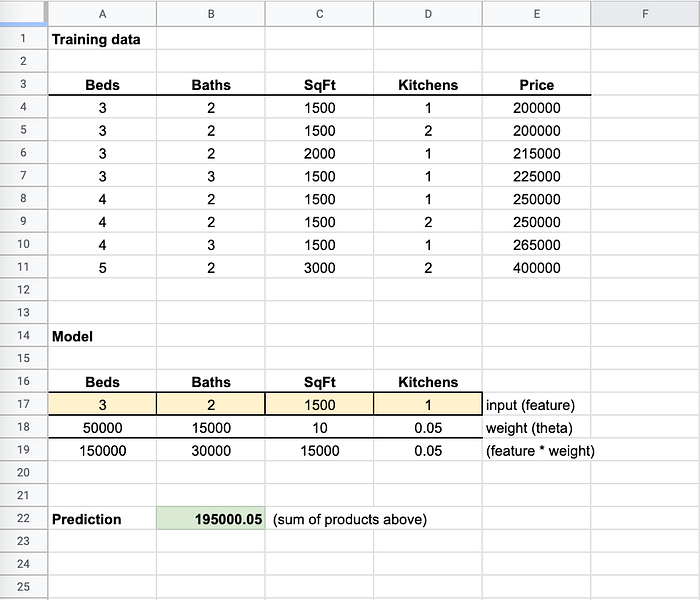
Beim Training werden die Gewichte so lange angepasst, bis die Vorhersage nah am tatsächlichen Preis liegt
In meinen Trainingsdaten (mehr dazu weiter unten) sehen Sie: Ob ich 1 oder 2 Küchen hatte, machte beim Preis keinen Unterschied. Das Gewicht (also der Multiplikator) liegt deshalb nahe 0, weil dieses Feature für die Preisbestimmung kaum relevant ist.
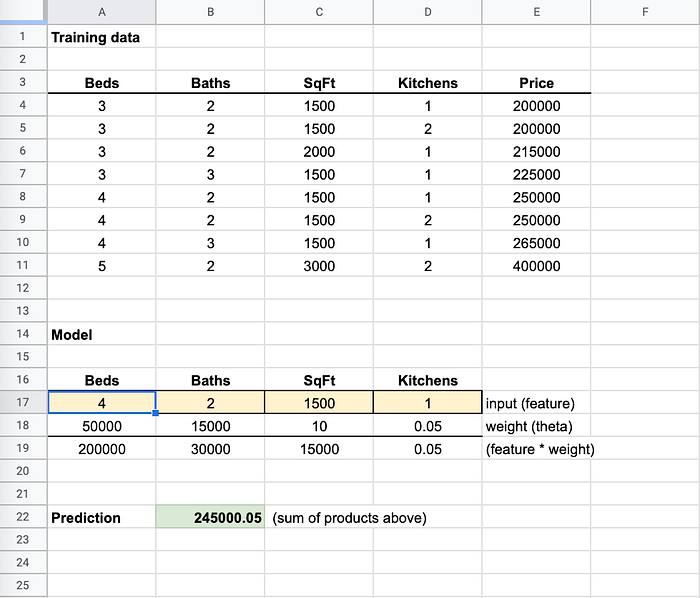
Ich ändere "Beds" auf "4" und das Ergebnis liegt ziemlich nah an den 250.000 aus den Trainingsdaten
Als ich "Beds" auf "4" gesetzt habe, kam die Vorhersage nah an den Wert 250.000 heran. ML-Algorithmen justieren die Gewichte in winzigen Bruchteilen, um über alle Eingaben hinweg möglichst genau zu treffen. Eine 100-prozentige Genauigkeit ist daher die absolute Ausnahme.
Ein verbreitetes Modelldateiformat ist pickle; ein Werkzeug zum Erstellen und Ausführen ist joblib. Andere Frameworks wie TensorFlow und PyTorch nutzen eigene Formate, und es gibt Bestrebungen für universelle Formate, um Modelle portabler zu machen.
Um Ihr Modell in Ihrer Anwendung zu nutzen (Serving) – wie oben gezeigt – importieren Sie die kompatible Bibliotheksversion, mit der die Datei erstellt wurde, laden sie per load() und rufen predict() auf, genau wie jede andere Funktion in Ihren Programmen. Ein lauffähiges Beispiel zeige ich später – aber im Kern ist das schon alles!
2. Modelle trainieren (Ihre Funktion erstellen)
Wir gehen später ins Detail, aber stellen Sie sich vor, Sie wollten ein Lebensmittel als Eingabe nehmen und vorhersagen, ob Ihr Kind es mag – wir alle ahnen, wie das ausgeht! ;-)
Klassisch würden Sie eine Funktion von Hand schreiben, mit Regeln, die Sie kennen:
Ihre Eingaben (Features) könnten Attribute des Lebensmittels sein, etwa Typ, Geruch, Schärfe, Temperatur, Zuckergehalt oder Farbe. Die vorhergesagte Ausgabe (Inference) ist entweder "gut" oder "schlecht".
Das Problem dabei: Wissen Sie wirklich, was die ideale Temperatur, Süße oder der ideale Geruch ist – und welche Faktoren für ein Kind am wichtigsten sind, wenn es zwischen "gut" und "schlecht" entscheidet? Dieser Ansatz bleibt bestenfalls Trial-and-Error.
Stellen Sie sich nun vor, Ihre Daten umfassen zehntausend Datensätze. Ihr Gehirn kann unmöglich all diese Werte behalten und so korrelieren, dass sich Schwellenwerte für Schärfe, Temperatur, Geruch und Süße ableiten lassen. Übergeben Sie diese Daten dagegen einem Computer, schafft er das in der Regel innerhalb von Sekunden und definiert eine mathematische Funktion, die korrekte Vorhersagen liefert. Genau dabei hilft uns Machine Learning.
Überblick über das Training eines ML-Modells
Halten wir es zunächst einfach mit dem Code unten:
Das ist ein bewusst vereinfachtes Beispiel, um zu "entmystifizieren", was Machine Learning eigentlich ist. Statt Funktion und Regeln selbst zu schreiben, nutzen Sie einen Algorithmus, der iterativ verschiedene Gewichte mit jedem Eingabewert multipliziert, bis er meistens die richtigen Antworten liefert (denken Sie an die Tabelle oben).
Angenommen, Sie geben 100 Datensätze ein und es zeigt sich ein Muster: Immer wenn die Farbe des Lebensmittels 4 war, lag das Ergebnis bei 0 ("schlecht"). Die Funktion beginnt sich quasi selbst zu schreiben, indem sie diese Regeln entdeckt – genau wie Ihre handgeschriebene Funktion Regeln enthielt. Die Antwort (Inference) ist meist korrekt, weil Sie die Funktion (Ihr Modell trainiert) auf Basis vorhandener Daten mit korrekten Antworten (Labels) erstellt haben.
Stellen Sie sich vor, einen Monat später sagt Ihr Kind, es mag Brokkoli. Brokkoli ist grün – also müssen Sie überlegen, wie Sie Ihre erste Funktion umschreiben, um das zu berücksichtigen. Sobald sich Daten ändern, wird das immer mühsamer. Mit Machine Learning füttern Sie die neuen Informationen einfach ein und retrainieren Ihr Modell, bis die Vorhersagen wieder stimmen. Genau das ist seine Stärke.
3. Welche Techniken eignen sich am besten für welche Probleme?
Diesen Punkt überspringen wir. Die meisten KI-Kurse beginnen mit Kategorien von ML-Algorithmen, und meiner Meinung nach verkompliziert das den Einstieg unnötig. Lassen Sie es vorerst beiseite. Bauen Sie zuerst ein Verständnis auf und vertiefen Sie Ihr Wissen später.
Zusammenfassung des bisher Gelernten
Was Sie hoffentlich mitnehmen: Sie können manuell eine Funktion wie oben erstellen, Bedingungen wie "wenn ein Gemüse, dann schlecht" raten und damit durchaus brauchbare Ergebnisse erzielen.
Sobald die Vorhersagen jedoch komplexer werden, Geschwindigkeit zählt oder mehr Datenpunkte ins Spiel kommen, übersteigt das schnell die Fähigkeit, im Kopf zuverlässig zu schätzen – und genau hier kommt Machine Learning ins Spiel.
Terminologie
- Model – eine mathematische Funktion, die von einem Computerprogramm erzeugt wird, individuelle Gewichte auf numerische Eingabewerte anwendet und ein numerisches Ergebnis zurückgibt.
- Feature – ein numerischer Eingabewert oder Parameter (auch Dimension), den Sie an Ihre Funktion übergeben, damit sie eine Vorhersage zurückliefert.
- Label – eine bekannte Antwort für vergangene Daten (auch Class). In unserem Beispiel mit den Vorlieben des Kindes wussten wir bereits, dass es Pizza und Kuchen mag, Spinat aber nicht – also bekamen Pizza und Kuchen den Wert 1 für "gut" und Spinat den Wert 0 für "schlecht".
- Observation – ein Satz von Features, die zu einer bestimmten Eingabe gesammelt wurden, etwa die Features, die wir aus der Pizza extrahiert haben.
- Feature Engineering – das Identifizieren der Attribute einer Observation, die das Ergebnis voraussichtlich beeinflussen, und deren Umwandlung in Zahlenwerte, damit sich daraus eine mathematische Funktion bauen lässt – statt einer manuell geschriebenen. So haben wir Farben und Lebensmitteltypen über ihren Array-Index in Zahlen überführt, statt mit ihrem String-Wert zu arbeiten (auch Feature Extraction).
- Training – das wiederholte Durchlaufen eines Datensatzes und das Ausprobieren verschiedener Gewichte (Theta) für jedes Feature, bis die meisten Ergebnisse korrekt sind.
- Fit – im Hintergrund versucht Ihr ML-Algorithmus, die Koordinaten einer Linie zu finden, die "gute" von "schlechten" Datensätzen trennt – sodass künftige Datensätze auf einer Seite der Linie als "gut" und auf der anderen als "schlecht" gelten. Im Grunde ist genau das, was Training tut – aber das müssen Sie sich jetzt nicht im Detail merken.
- Inference – technisch gesehen der "Akt des Vorhersagens". Der Einfachheit halber verstehen Sie es einfach als das Ergebnis bzw. die Vorhersage, die Ihre Modellfunktion zurückgibt (also: gegeben diese Parameter, schließe ich auf diese Antwort).
- Serving – die Nutzung Ihrer Funktion in einem Programm: Sie laden die Modelldatei und übergeben ihr Parameter, damit sie Vorhersagen zurückgibt.
- Testing – Sie übergeben dem Modell Test-Features, erhalten Vorhersagen und vergleichen das Ergebnis mit den bekannten Werten (Labels) für eine Gruppe von Datensätzen.
- Accuracy – der Anteil der Vorhersagen, die mit dem erwarteten Ergebnis übereinstimmen, bezogen auf alle Testdatensätze. Begriffe für später: Precision und Recall.
Aktuell weniger wichtig, aber später relevant:
- Theta – das Gewicht, mit dem jedes Feature multipliziert wird, um auf Basis seines vermuteten Einflusses auf das Ergebnis eine Vorhersage zurückzugeben. Ein gutes Beispiel ist die Vorhersage von Immobilienwerten: Vielleicht liegt der Verkaufspreis für ein 3-Zimmer-Haus mit 2 Küchen bei 200.000 $. Ein anderer Verkauf eines 3-Zimmer-Hauses mit 1 Küche liegt ebenfalls bei 200.000 $. Ein 4-Zimmer-Haus bringt 250.000 $. Das Modell weist dem Feature "Anzahl der Schlafzimmer" ein höheres Theta (auch Gewicht oder Wichtigkeit) zu, weil es den Preis beeinflusst, und ein niedrigeres Theta der Anzahl der Küchen, weil sie kaum Einfluss hatte.
- Hyperparameter Tuning – wenn Sie wissen, dass bestimmte Features mehr oder weniger wichtig für das Ergebnis sind, können Sie schon beim Pre-Processing oder Feature Engineering eigene Gewichte anwenden, um die Genauigkeit Ihrer Vorhersagen zu verbessern. Ziel ist es, den Loss (auch Penalty) bei schlechten Vorhersagen zu minimieren, sodass die Vorhersagen weniger empfindlich auf Eingabevariationen reagieren. Ist nerdig, ich weiß – ignorieren Sie es vorerst.
Prozess
Wir haben gelernt, dass Serving bedeutet, eine Software-Bibliothek zu nutzen, die Ihre gespeicherte Modelldatei lesen und ausführen kann (z. B. joblib). Hätten Sie eine Web-API, die Parameter wie Lebensmitteltyp, Schärfe, Süße usw. entgegennimmt, könnten Sie Ihr Modell mit load() laden, diese Parameter übergeben, und mit predict() käme eine 1 oder 0 zurück. Ihre API interpretiert in der Antwort an die Nutzer 1 = "gut" und 0 = "schlecht".
Wir haben außerdem gelernt: Um Ihr Modell zu trainieren, müssen Sie unter Umständen Feature Engineering betreiben. Dabei identifizieren Sie Werte rund um das Lebensmittel (Observation), die das Ergebnis beeinflussen könnten, und überführen einige davon in Zahlen, damit sie in eine mathematische Funktion einfließen können. Anschließend legen Sie einige bekannte (gelabelte) Datensätze beiseite, um die Genauigkeit zu testen, und trainieren (fitten) Ihr Modell, bis sich die Genauigkeit verbessert.
Schauen wir uns nun ein praxisnahes Beispiel an, bevor wir in die eigentliche Umsetzung eintauchen.
Machine Learning auf ein Geschäftsproblem anwenden
Es hilft, Dinge an Beispielen zu erklären, mit denen man sich identifizieren kann. Stellen Sie sich vor, Sie haben eine Website und möchten mehr Abonnenten gewinnen (für irgendetwas anmelden). Bisher haben Sie gleich viel für Google, Facebook, Fernsehen, Radio und Print ausgegeben. Im nächsten Jahr steht das gleiche Werbebudget zur Verfügung, und Sie müssen wissen, wo Sie Ihr Geld am besten investieren, um die Zahl neuer Abonnenten um zwanzig Prozent zu steigern.
Sie müssen herausfinden, welchen Anteil Ihres Werbebudgets Sie jedem Anbieter zuweisen sollten, um die meisten neuen Abonnenten zu gewinnen.
Sie haben Ihre neuen Abonnenten Monat für Monat aus dem Vorjahr analysiert, einschließlich Quelle, Kosten und Anmeldezahlen. Das Ergebnis: Die meisten Abonnenten kamen von Google, gefolgt von Facebook und Fernsehen, einige wenige von Radio und Print – aber die Zahlen schwanken je nach Saison oder sogar von Monat zu Monat.
Hätte ich bei diesen Anbietern andere Beträge als im Vorjahr ausgegeben, hätte ich dann mehr Abonnenten gewinnen können?
Haben Sie schon einmal die "Zielwertsuche" in Excel verwendet?
Klassisch hätten Sie versucht, die Budgetverteilung zu optimieren – ausgehend von einer Vermutung oder Hypothese, gefolgt von ein paar Simulationen in einer Tabellenkalkulation. Sie fügen die Vorjahresergebnisse ein, jede Zeile zeigt den Betrag pro Anbieter, die daraus resultierenden neuen Abonnenten und deren Kosten, dazu vielleicht weitere relevante Datenpunkte. Sie ändern diese Werte immer wieder, um zu sehen, ob sich mehr Abonnenten gewinnen lassen.
Genau das macht die in Excel eingebaute Funktion "Zielwertsuche" automatisch – auch wenn sie nur wenige nutzen oder überhaupt kennen. Sie definieren ein Ziel wie im Beispiel unten, und Excel ändert iterativ die Werte in anderen Zellen, bis der gewünschte Wert in der Ausgabezelle erreicht ist.
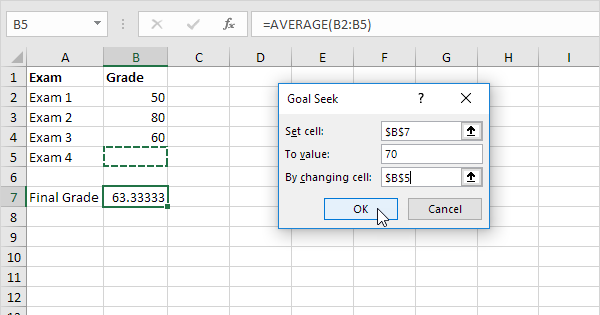
Mit der Zielwertsuche optimale Werte finden
Im Werbebeispiel versuchen Sie, die relative Bedeutung jeder Werbeart zu bestimmen und einen Prozentsatz (oder ein Gewicht) Ihres Gesamtbudgets zuzuweisen. Sie wissen, wie viele Abonnenten Sie im Vorjahr hatten, und möchten beim gleichen Budget 20 % mehr.
Sie setzen das als Zielwert und ändern dann die Anteile pro Anbieter, bis Sie Ihr Ziel erreichen. Genau so werden Machine-Learning-Modelle trainiert: Sie iterieren durch die Daten und passen Werte (Gewichte, die mit den Eingabeparametern multipliziert werden) so lange an, bis sie sich den bekannten Antworten (Labels) annähern.
Keine Sorge, falls noch nicht alles Sinn ergibt. Wenn Sie die Anwendung erkunden, mehr in Teil 2 erfahren und dann diesen Teil noch einmal lesen, wird vieles "klick" machen (so hoffe ich).
Machine Learning hebt die "Zielwertsuche" auf das nächste Level
Nach viel Trial-and-Error finden Sie die richtige Mischung (Gewicht oder Prozentsatz pro Werbeart), um Ihr Ziel zu erreichen. Angenommen, Ihre Daten umfassen jedoch 100 Anmeldungen pro Tag an 365 Tagen im Jahr, und an unterschiedlichen Tagen lieferte mal der eine, mal der andere Anbieter mehr Anmeldungen. Es wäre schlicht zu aufwendig, in 36.500 Datenzeilen mit Anbieter, Wochentag, Tag im Jahr, Views, Klicks, Conversions, Anmeldungen, Cost-per-Click oder Impression usw. die entscheidenden Unterschiede zu erkennen.
Es wird hoffentlich klar: Manche Probleme sind schlicht nicht für menschliche Lösungen geeignet – und das hier ist – anders als die Geschmacksvorlieben Ihres Kindes – eine dieser Funktionen, die sich am besten automatisieren lassen. Machine-Learning-Algorithmen funktionieren ähnlich wie die "Zielwertsuche", können aber iterativ Werte in vielen Zellen gleichzeitig ändern und jede Anpassung testen, bis sich der Ausgabewert dem bekannten Wert (Label oder Class) für eine beliebige Eingabe annähert.
Weiter zu Teil 2 – dort sehen Sie, wie die obige Demo entstanden ist, inklusive Links zum Quellcode.
Sie wissen, was zu tun ist!
- Teilen Sie diesen Artikel gerne mit allen, die sich dafür interessieren könnten. Es hilft ihnen – und mir wirklich sehr!
- Bitte geben Sie mir 50 Claps! (Halten Sie einfach den Clap-Button gedrückt.)
- Hinterlassen Sie gerne einen Kommentar 💬.
