Il y a quelques années, je me suis lancé dans l'apprentissage de l'IA et du machine learning (ML) pour comprendre comment l'appliquer dans mes propres entreprises, ou au moins échanger intelligemment avec nos équipes data science et engineering.
J'ai suivi des cours en ligne, regardé des vidéos et passé des examens, mais je n'avais toujours pas le sentiment de savoir comment appliquer et intégrer le machine learning à mon activité. Tant de questions restaient sans réponse. Si cela vous parle, lisez la suite.
Démo
Pour vous donner envie de lire cet article ainsi que la partie 2 de cette série, installez-vous confortablement et regardez d'abord cette démo d'un pipeline de machine learning fonctionnel.
La plupart décrivent un pipeline ML comme la suite d'étapes permettant d'organiser et d'affiner des données, de s'en servir pour entraîner des modèles de machine learning, puis de servir, ou d'utiliser, ces modèles au sein d'une application. Pas d'inquiétude si ces termes ne vous parlent pas encore.
Cette démo génère ses propres données structurées à partir des saisies utilisateur, ce qui simplifie le processus pour en faciliter la compréhension — du moins je l'espère. Je partagerai le code source et la démarche de conception dans mon prochain article.
Démo de quatre minutes d'une application de pipeline ML personnalisée hébergée sur Google Cloud Platform
Combler le fossé du vocabulaire ML
La plupart des personnes qui, comme moi, viennent du software engineering ou du produit manient un vocabulaire familier : class, method, function, parameter, input, request, variable, loop, output, return et response.
Dans l'univers du machine learning, on retrouve des termes analogues : observation, model, dimension, feature, fit, train, test et inference. Ajoutez-y des symboles grecs comme theta, et la tête se met à tourner. C'est déroutant au premier abord, mais nous allons nous familiariser progressivement avec ces termes.
Dans sa forme la plus simple, un modèle de machine learning est une fonction mathématique qui, à partir d'entrées numériques, renvoie une sortie numérique.
À mes yeux, le problème de l'enseignement actuel, c'est qu'il faut trop de temps avant de comprendre comment se servir de cette technologie. Nous allons donc commencer par ces questions :
- Comment utiliser cette fonction dans la vraie vie (autrement dit, le serving) ?
- Comment créer cette fonction (autrement dit, l'entraînement) ?
- Quelles techniques sont les mieux adaptées à tel ou tel problème ?
TL;DR
Entrons dans le vif du sujet, en abordant ces réponses dans l'ordre inverse de celui qu'on enseigne d'habitude.
1. Servir vos modèles (utiliser votre fonction dans une application)
Les modèles de machine learning, autrement dit les fonctions, sont stockés dans des fichiers. Des bibliothèques logicielles permettent de les ouvrir, de les exécuter, d'accepter des entrées et de renvoyer des résultats.
Voyez ces fichiers de modèle comme de mini-tableurs. Ils contiennent des cellules avec des formules. Lorsque vous transmettez votre entrée au tableur, il place vos valeurs dans certaines cellules (comme les cellules jaunes ci-dessous) et calcule une valeur de retour qui constitue votre prédiction (comme la cellule verte ci-dessous).
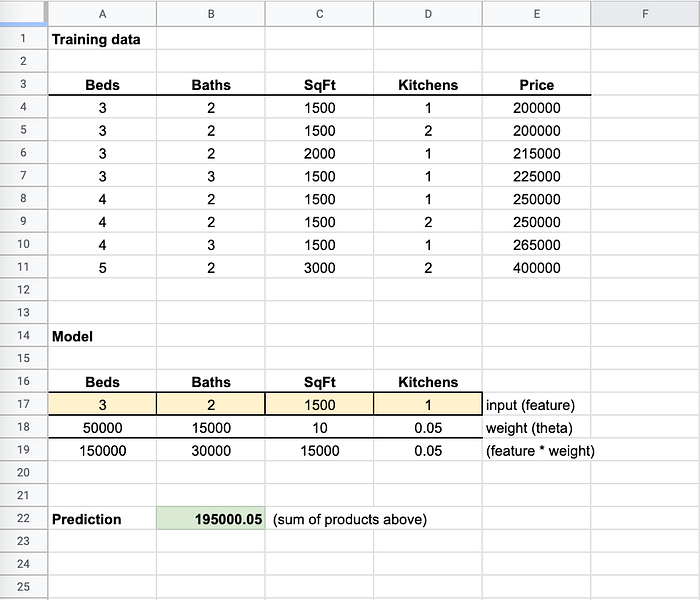
L'entraînement ajuste les pondérations en continu jusqu'à ce que la prédiction se rapproche du prix réel
Remarquez dans mes données d'entraînement (nous y reviendrons plus en détail) que le fait d'avoir 1 ou 2 cuisines ne changeait rien au prix. La pondération (multiplicateur) est donc quasi nulle, car ce n'est pas une feature déterminante pour le prix.
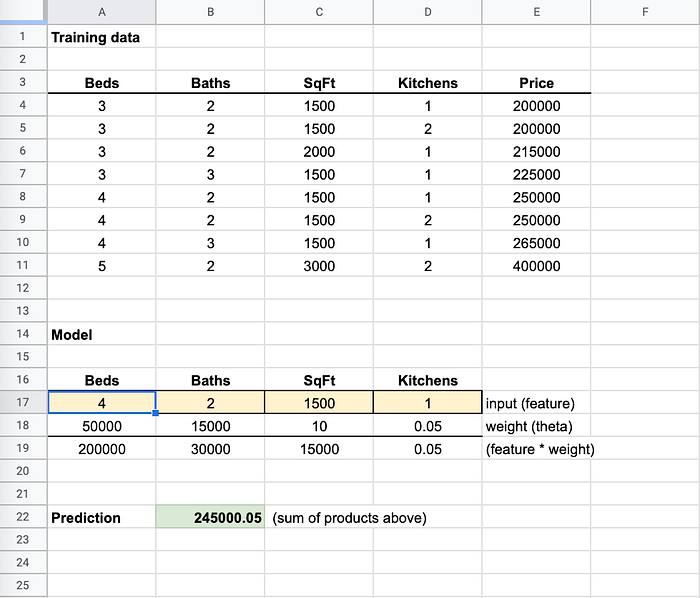
Je passe le nombre de chambres à 4 et le résultat se rapproche des valeurs à 250 000 dans les données d'entraînement
Maintenant que j'ai changé Beds à 4, la prédiction se rapproche de la valeur de 250 000. Les algorithmes ML ajustent les pondérations à de petites fractions pour les rendre aussi précises que possible quelles que soient les entrées. Atteindre 100 % de précision est donc très rare.
Un format de fichier de modèle répandu s'appelle pickle, et un outil pour les créer et les exécuter s'appelle joblib. D'autres frameworks comme TensorFlow et PyTorch ont leurs propres formats, et des tentatives de formats universels visent à rendre les modèles plus portables.
Pour utiliser votre modèle dans votre application (le serving) comme illustré ci-dessus, vous importez la version compatible de la bibliothèque utilisée pour créer le fichier, vous le load(), puis vous appelez predict() comme avec n'importe quelle autre fonction de vos programmes. J'en partagerai un exemple fonctionnel plus tard, mais c'est aussi simple que ça !
2. Entraîner vos modèles (construire votre fonction)
Nous entrerons dans les détails plus tard, mais imaginons que vous souhaitiez prendre un aliment en entrée et prédire si votre enfant l'aimera ; on devine où cela mène ! ;-)
Traditionnellement, vous écririez une fonction à la main avec des règles connues, comme ceci :
Vos entrées (features) peuvent être des attributs de l'aliment : type, odeur, piquant, température, teneur en sucre ou couleur. Votre sortie prédite (inference) sera soit good, soit bad.
Le souci, quand vous écrivez vous-même cette fonction, c'est de savoir si vous connaissez vraiment la température, la douceur ou l'odeur idéale, et quels facteurs comptent le plus pour qu'un enfant juge un aliment good ou bad. Cette approche relève au mieux du tâtonnement.
Imaginez à présent que vos données comptent dix mille enregistrements. Votre cerveau ne peut pas mémoriser et corréler toutes ces valeurs pour déterminer le seuil de piquant, de température, d'odeur et de douceur. Avec un ordinateur et toutes ces données en entrée, il peut le faire, généralement en quelques secondes, et définir une fonction mathématique qui renverra les bonnes prédictions. C'est précisément là que le machine learning entre en jeu.
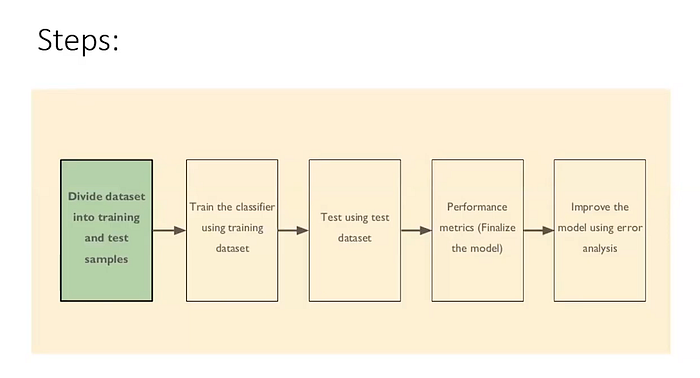
Vue d'ensemble de l'entraînement d'un modèle ML
Restons-en pour l'instant à un cas simple, avec le code ci-dessous :
Voici un exemple volontairement simpliste pour démystifier le machine learning. Au lieu d'écrire vous-même la fonction et les règles, vous utilisez un algorithme qui multiplie itérativement différentes pondérations à chaque valeur d'entrée jusqu'à obtenir les bonnes réponses la plupart du temps (rappelez-vous l'analogie du tableur).
Supposons que vous saisissiez 100 enregistrements et qu'un schéma se dégage : à chaque fois que la couleur de l'aliment était 4, le résultat était 0 (bad). La fonction commence à s'écrire d'elle-même à mesure qu'elle découvre ces règles, exactement comme votre fonction manuelle. La réponse (inference) est globalement correcte parce que vous avez créé la fonction (entraîné votre modèle) à partir de données dont vous connaissiez déjà les bonnes réponses (labels).
Imaginez qu'un mois plus tard, votre enfant vous dise qu'il aime le brocoli. Le brocoli est vert : vous devez donc trouver comment réécrire votre première fonction pour en tenir compte. À mesure que les données évoluent, l'exercice devient de plus en plus compliqué. Avec le machine learning, il vous suffit d'injecter les nouvelles informations et de réentraîner votre modèle jusqu'à obtenir des prédictions précises. Voilà toute sa puissance.
3. Quelles techniques sont les mieux adaptées à tel ou tel problème ?
Nous allons mettre cette question de côté. La plupart des cours d'IA commencent par les catégories d'algorithmes ML, et je trouve que cela complique l'apprentissage. Pour l'instant, laissez ça de côté. Acquérez d'abord une compréhension globale, vous approfondirez ensuite.
Récapitulatif de ce que nous avons vu jusqu'ici
Ce que j'espère vous avoir fait comprendre, c'est que vous pouvez créer manuellement une fonction comme ci-dessus, deviner des contraintes du type " si c'est un légume, c'est mauvais ", et potentiellement obtenir des résultats précis.
Mais à mesure que les prédictions se complexifient, que la rapidité devient critique ou que les points de données se multiplient, l'exercice dépasse ce qu'on peut deviner sereinement de tête. C'est là que le machine learning prend le relais.
Terminologie
- Model — une fonction mathématique générée par un programme informatique qui applique des pondérations uniques à des valeurs d'entrée numériques et renvoie un résultat numérique.
- Feature — une valeur d'entrée numérique ou un paramètre (autrement dit une dimension) que vous transmettez à votre fonction pour qu'elle renvoie une prédiction.
- Label — une réponse connue pour des données passées (autrement dit une class) ; dans notre exemple des goûts alimentaires de l'enfant, nous savions déjà qu'il aimait la pizza et le gâteau et pas les épinards : nous avons donc attribué la valeur 1 (good) à la pizza et au gâteau, et 0 (bad) aux épinards.
- Observation — un ensemble de features collectées sur une entrée particulière, comme les features que nous avons extraites de la pizza.
- Feature engineering — identifier les attributs d'une observation susceptibles d'influencer le résultat et les convertir en valeurs numériques afin de pouvoir construire une fonction mathématique plutôt qu'une fonction écrite à la main, comme lorsque nous avons converti les couleurs et les types d'aliments en nombres en utilisant leur index dans un tableau plutôt que leur valeur sous forme de chaîne (autrement dit, feature extraction).
- Training — itérer à plusieurs reprises sur un jeu de données, en testant différentes pondérations (theta) sur chaque feature jusqu'à ce que la plupart des résultats soient corrects.
- Fit — en coulisses, votre algorithme ML cherche les coordonnées d'une ligne capable de séparer les enregistrements good des bad, de sorte que les futurs enregistrements situés d'un côté soient good et ceux de l'autre côté bad. C'est en substance ce que fait l'entraînement, mais ne vous en souciez pas pour l'instant.
- Inference — techniquement, c'est l'acte de prédire, mais pour plus de clarté, considérez simplement qu'il s'agit du résultat, ou de la prédiction, renvoyé par la fonction de votre modèle (autrement dit, étant donné ces paramètres, j'infère cette réponse).
- Serving — utiliser votre fonction dans un programme en chargeant le fichier de modèle et en lui transmettant des paramètres pour qu'il renvoie des prédictions.
- Testing — transmettre des features de test au modèle pour obtenir des prédictions, puis comparer le résultat aux valeurs connues (labels) sur un groupe d'enregistrements.
- Accuracy — le pourcentage de prédictions qui correspondent au résultat attendu sur l'ensemble des enregistrements de test. Termes à approfondir plus tard : precision et recall.
Termes moins importants pour l'instant, mais qui reviendront par la suite :
- Theta — la pondération multipliée à chaque feature pour renvoyer une prédiction en fonction de son influence perçue sur le résultat. Bon exemple : la prédiction des prix immobiliers. Imaginons qu'une maison de 3 chambres avec 2 cuisines se soit vendue 200 000 $. Une autre maison de 3 chambres avec 1 cuisine s'est aussi vendue 200 000 $. Une maison de 4 chambres s'est vendue 250 000 $. Le modèle peut attribuer un theta plus élevé (autrement dit, une pondération ou une importance) au nombre de chambres parce qu'il influence le prix, et un theta plus faible au nombre de cuisines parce que son impact est minime.
- Hyperparameter tuning — si vous savez que certaines features pèsent plus ou moins dans le résultat, vous pouvez appliquer vos propres pondérations lors des étapes de pré-traitement ou de feature engineering pour améliorer encore la précision de vos prédictions. L'objectif est de minimiser la perte (autrement dit, la pénalité) sur les mauvaises prédictions, afin que celles-ci soient moins sensibles aux variations d'entrée. C'est très technique, je sais, alors laissez ça de côté pour l'instant.
Processus
Nous avons vu que le serving consiste à utiliser une bibliothèque logicielle capable de lire et d'exécuter votre fichier de modèle sauvegardé (par exemple, joblib). Si vous disposiez d'une API web acceptant des paramètres comme le type d'aliment, le piquant, la douceur, etc., vous pourriez faire un load() de votre modèle, lui transmettre ces paramètres, et il renverrait via predict() un 1 ou un 0. Votre API interprète 1 = good et 0 = bad dans la réponse aux utilisateurs.
Nous avons aussi vu que pour entraîner votre modèle, vous devrez sans doute faire du feature engineering. C'est l'étape où vous identifiez les valeurs liées à cet aliment (observation) susceptibles d'influencer le résultat, et où vous en convertissez certaines en nombres pour pouvoir les injecter dans une fonction mathématique. Vous mettez ensuite de côté quelques enregistrements connus (labeled) pour mesurer votre précision, et vous entraînez (fit) votre modèle jusqu'à ce que la précision s'améliore.
Examinons à présent une application pratique avant de plonger dans la véritable implémentation.
Appliquer le machine learning à un problème métier
Je trouve qu'il est plus parlant d'expliquer les choses avec des exemples concrets. Imaginez que vous ayez un site web et que vous souhaitiez plus d'abonnés (à un service ou autre). Jusqu'ici, vous avez réparti vos dépenses à parts égales entre Google, Facebook, la télévision, la radio et la presse écrite. Vous disposez du même budget publicitaire pour l'année à venir et vous devez savoir où dépenser au mieux votre argent pour augmenter de vingt pour cent les nouveaux abonnés nets.
Vous devez déterminer quel pourcentage de votre budget publicitaire allouer à chaque fournisseur pour maximiser le nombre de nouveaux abonnés.
Vous avez analysé vos nouveaux abonnés mois par mois sur l'année écoulée, ainsi que la source, son coût et le nombre d'inscriptions associées. Vous avez constaté que la majorité des abonnés venaient de Google, puis de Facebook, puis de la télévision, et quelques-uns de la radio et de la presse écrite, mais que les volumes varient selon la saison, voire selon le mois.
Si j'avais réparti mes dépenses différemment l'année dernière entre ces mêmes fournisseurs, aurais-je obtenu plus d'abonnés ?
Avez-vous déjà utilisé la " Valeur cible " dans Excel ?
Traditionnellement, votre tentative d'optimisation du budget aurait commencé par une intuition ou une hypothèse, puis quelques simulations dans un tableur. Vous y collez les résultats de l'année passée, chaque ligne contenant le montant dépensé chez chaque fournisseur, le nombre de nouveaux abonnés générés, le coût associé, et éventuellement d'autres points de données qui vous semblent pertinents. Vous modifiez ces valeurs, encore et encore, pour voir si vous obtenez davantage d'abonnés.
C'est précisément ce que fait automatiquement la fonction " Valeur cible " intégrée à Excel, mais peu de gens l'utilisent ou en connaissent l'existence. Vous fixez un objectif comme dans l'exemple ci-dessous, et la fonction modifie itérativement les montants dans d'autres cellules jusqu'à atteindre la valeur souhaitée dans la cellule de sortie.
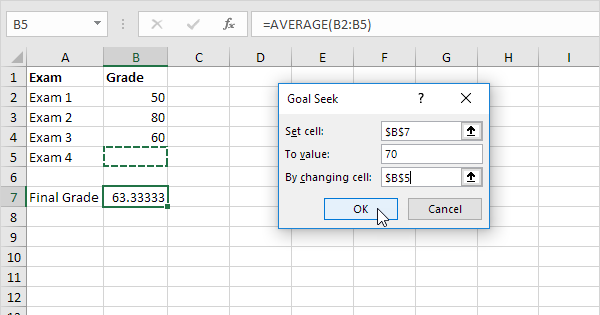
Utilisation de Valeur cible pour trouver les valeurs optimales
Dans l'exemple publicitaire, vous cherchez à déterminer l'importance relative de chaque type de publicité et à allouer un pourcentage (ou une pondération) de votre budget total. Vous savez combien d'abonnés vous avez eus l'année dernière et vous en visez 20 % de plus pour le même budget.
Vous fixez cela comme valeur cible, puis vous ajustez le % alloué à chaque fournisseur jusqu'à atteindre votre objectif. C'est exactement ainsi que s'entraîne un modèle de machine learning : en itérant sur les données et en modifiant les valeurs (pondérations multipliées aux paramètres d'entrée) jusqu'à se rapprocher des réponses connues (labels).
Pas d'inquiétude si tout cela n'est pas encore limpide. Au fil de votre exploration de l'application et de la suite dans la partie 2, puis en revenant à cette première partie, le déclic devrait se faire (du moins je l'espère).
Le machine learning fait passer la " Valeur cible " au niveau supérieur
Après pas mal de tâtonnements, vous trouvez le bon dosage (pondération ou pourcentage par type de publicité) pour atteindre votre objectif. Mais imaginons que vos données comportent 100 inscriptions par jour sur 365 jours, et que selon les jours, certains fournisseurs convertissent mieux que d'autres. Il serait bien trop difficile d'identifier les variations sur 36 500 lignes de données croisant fournisseur, jour de la semaine, jour de l'année, vues, clics, conversions, inscriptions, coût par clic ou par impression, etc.
On voit bien que certains problèmes ne se prêtent pas à une résolution humaine, et que cette fonction-là, contrairement aux goûts alimentaires de votre enfant, gagne à être automatisée. Les algorithmes de machine learning ressemblent beaucoup à la " Valeur cible ", à ceci près qu'ils peuvent modifier itérativement les valeurs de nombreuses cellules à la fois et tester chaque changement jusqu'à ce que la valeur de sortie se rapproche de la valeur connue (label ou class) pour une entrée donnée.
Passez à la partie 2 pour découvrir comment la démo ci-dessus a été créée et accéder aux liens vers le code source.
Vous savez ce qu'il vous reste à faire !
- Partagez cet article avec toute personne susceptible d'être intéressée. Cela peut l'aider, et cela m'aide énormément !
- Donnez-moi 50 claps ! (Maintenez simplement le bouton clap enfoncé.)
- N'hésitez pas à laisser un commentaire 💬.
