Diversi anni fa decisi di approfondire la mia conoscenza dell'AI e del machine learning (ML) per capire come applicarli nelle mie aziende, o quanto meno per riuscire a dialogare in modo competente con i nostri team di data science e di engineering.
Ho seguito corsi online, guardato video e superato esami, ma non avevo davvero la sensazione di aver capito come applicare e integrare il machine learning nel mio business. Troppe domande restavano senza risposta. Se anche a Lei è successo, continui a leggere.
Demo
Per invogliarLa a leggere questo articolo e la seconda parte della serie, La invito a mettersi comodo e guardare prima questa demo di una pipeline di machine learning funzionante.
Una pipeline ML viene di solito descritta come la sequenza di passaggi necessari per organizzare e affinare i dati, utilizzarli per addestrare modelli di machine learning e poi servire, ovvero utilizzare, quei modelli all'interno di un'applicazione. Non si preoccupi se questi termini non Le sono ancora chiari.
Questa demo crea i propri dati strutturati a partire dall'input dell'utente, semplificando il processo per renderne più facile la comprensione, almeno spero. Nel prossimo articolo condividerò il codice sorgente e l'approccio seguito per progettarla e realizzarla.
Demo di quattro minuti di un'app pipeline ML personalizzata ospitata su Google Cloud Platform
Colmare il divario lessicale del ML
Chi, come me, viene dal software engineering o dal mondo prodotto parla un linguaggio familiare fatto di termini come class, method, function, parameter, input, request, variable, loop, output, return e response.
Nel mondo del machine learning ci sono termini analoghi come observation, model, dimension, feature, fit, train, test e inference. Se a questi aggiungiamo simboli matematici greci come theta, la testa inizia a girare. All'inizio può essere disorientante, ma assimileremo questi termini gradualmente, strada facendo.
Nella sua forma più semplice, un modello di machine learning è una function matematica che, dati input numerici, restituisce un output numerico.
Credo che il problema dell'insegnamento attuale sia il troppo tempo che si impiega per capire come usare la tecnologia, quindi partiremo da queste domande:
- Come uso questa funzione nella vita reale (cioè il serving)?
- Come creo questa funzione (cioè il training)?
- Quali tecniche sono migliori per determinati problemi?
TL;DR
Andiamo dritti al punto, scoprendo le risposte nell'ordine inverso rispetto a come vengono solitamente insegnate.
1. Servire i modelli (usare la funzione in un'app)
I modelli di machine learning, ovvero le function, sono memorizzati in file. Le librerie software possono aprirli ed eseguirli, ricevere input e restituire risultati.
Pensi a questi file di modello come a dei mini "fogli di calcolo". Hanno alcune celle con formule. Quando passa il Suo input al "foglio di calcolo", questo inserisce i valori in alcune celle (come quelle gialle qui sotto) e calcola un valore di ritorno, che è la Sua prediction (come la cella verde qui sotto).
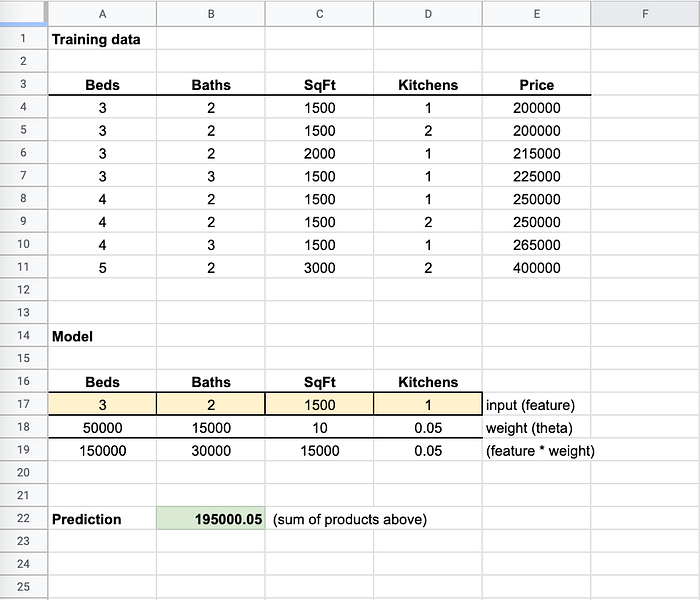
Il training continua a modificare i pesi finché la previsione non si avvicina al prezzo reale
Noti che nei miei dati di training (ne parleremo meglio più avanti) avere 1 o 2 cucine non cambiava il prezzo. Il peso (moltiplicatore) è quindi quasi 0, perché non è una feature rilevante per determinare il prezzo.
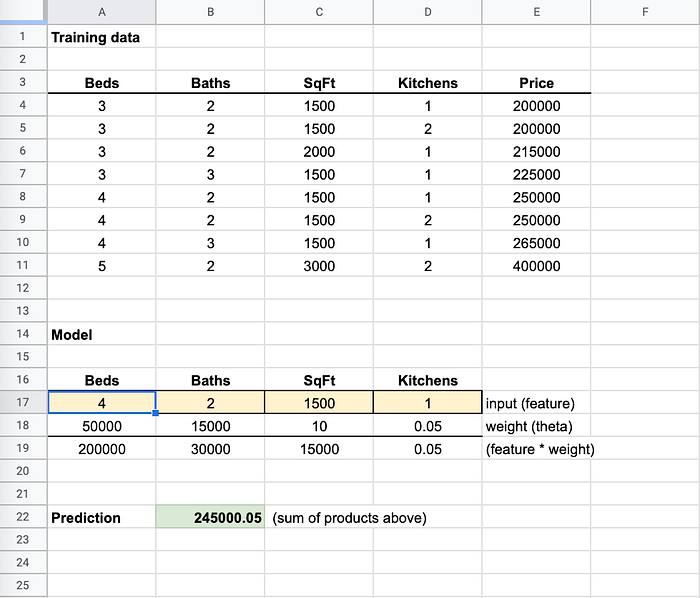
Porto i letti a "4" e il risultato è molto vicino al valore di 250000 nei dati di training
Ora che ho cambiato "Beds" in "4", la previsione si è avvicinata al valore di 250.000. Gli algoritmi di ML aggiustano i pesi a frazioni minime per renderli il più possibile accurati su tutti gli input. Per questo è molto raro raggiungere il 100% di accuratezza.
Un formato di file modello molto diffuso si chiama pickle, e uno strumento per crearli ed eseguirli è joblib. Altri framework come TensorFlow e PyTorch hanno i propri formati, e ci sono diversi tentativi di formati universali per rendere i modelli più portabili.
Per usare il modello nella Sua applicazione (serving) come illustrato sopra, importi la versione della libreria compatibile con quella usata per creare il file, esegua load() e poi predict(), proprio come farebbe con qualsiasi altra function nei Suoi programmi software. Più avanti condividerò un esempio funzionante, ma in pratica è tutto qui.
2. Addestrare i modelli (costruire la function)
Entreremo nei dettagli più avanti, ma immagini di voler dare in input un cibo per prevedere se a Suo figlio piacerà; sappiamo tutti dove andrà a parare il discorso! ;-)
Tradizionalmente scriverebbe a mano una funzione come questa, con regole note:
I Suoi input (features) potrebbero essere attributi del cibo come tipo, odore, piccantezza, temperatura, contenuto di zucchero o colore. L'output previsto (inference) è "good" oppure "bad".
Il problema dello scrivere manualmente la funzione qui sopra è capire davvero quali siano la temperatura, la dolcezza o l'odore ideali e quali fattori siano più importanti per un bambino quando decide se un cibo è "good" o "bad". Questo approccio è, nella migliore delle ipotesi, basato su tentativi ed errori.
Ora immagini di avere a disposizione diecimila record. Il Suo cervello non potrà mai memorizzare e correlare tutti quei valori per stabilire dove si trovi il punto di soglia per piccantezza, temperatura, odore e dolcezza. Se affida tutti questi dati a un computer, riuscirà a capirlo, di solito in pochi secondi, e a definire una funzione matematica in grado di restituire le previsioni corrette. È in questo che ci aiuta il machine learning.
Panoramica del training di un modello ML
Per ora restiamo sul semplice con il codice qui sotto:
Questo è un esempio semplificato per "demistificare" cos'è il machine learning. Invece di scrivere da soli la funzione e le sue regole, si usa un algoritmo che moltiplica iterativamente pesi diversi su ciascun valore di input finché non restituisce le risposte corrette nella maggior parte dei casi (ricordi il foglio di calcolo qui sopra).
Supponga di inserire 100 record e che emerga un pattern: ogni volta che il colore del cibo era 4, il risultato era 0 ("bad"). La funzione inizia a scriversi da sola man mano che scopre queste regole, proprio come la Sua funzione manuale aveva regole al suo interno. La risposta (inference) è prevalentemente corretta perché ha creato la funzione (addestrato il modello) basandosi su dati di cui già conosceva le risposte corrette (labels).
Immagini che un mese dopo Suo figlio Le dica che gli piacciono i broccoli. Sono verdi, quindi deve capire come riscrivere la prima funzione per tenerne conto. Quando i dati cambiano, l'operazione diventa sempre più complessa. Con il machine learning basta dare in pasto le nuove informazioni e fare il retrain del modello finché le previsioni non tornano accurate. È questa la forza che offre.
3. Quali tecniche sono migliori per determinati problemi?
Salteremo questa parte. La maggior parte dei corsi di AI inizia dalle categorie di algoritmi ML e credo che questo complichi il processo di apprendimento. Per ora la ignori. Prima si costruisca una comprensione di base, poi approfondirà le Sue conoscenze.
Riepilogo di ciò che abbiamo imparato finora
Quello che spero abbia capito è che può creare manualmente una funzione come quella sopra, e tirare a indovinare vincoli del tipo "se è una verdura allora è cattivo", ottenendo potenzialmente risultati accurati.
Quando però il tipo di previsione si fa più complicato, quando la velocità è critica o quando i punti dato da considerare sono numerosi, si supera la capacità di indovinare a mente in modo affidabile, ed è qui che il machine learning può dare una mano.
Terminologia
- Model — una funzione matematica generata da un programma che applica pesi specifici ai valori di input numerici e restituisce un risultato numerico.
- Feature — un valore o parametro di input numerico (detto anche dimension) che si passa alla funzione affinché restituisca una previsione.
- Label — una risposta nota relativa a dati passati (detta anche class): nell'esempio dei gusti alimentari di nostro figlio sapevamo già che gli piacevano pizza e torta ma non gli spinaci, quindi abbiamo assegnato a pizza e torta il valore 1 per "buono" e agli spinaci il valore 0 per "cattivo".
- Observation — un insieme di feature raccolte su un determinato input, come le feature che abbiamo estratto dalla pizza.
- Feature engineering — l'identificazione degli attributi di una determinata observation che probabilmente influenzano il risultato e la loro conversione in valori numerici, in modo da poter costruire una funzione matematica al posto di una scritta a mano: come quando abbiamo convertito colori e tipi di cibo in numeri usando l'indice dell'array invece del valore stringa (è il cosiddetto feature extraction).
- Training — iterare ripetutamente su un dataset, provando pesi diversi (theta) su ciascuna feature finché la maggior parte dei risultati non è corretta.
- Fit — dietro le quinte il Suo algoritmo ML cerca di individuare le coordinate di una linea capace di separare i record "good" da quelli "bad", in modo che i record futuri che cadono da un lato della linea siano "good" e quelli dall'altro lato siano "bad". È in pratica ciò che fa il training, ma per ora non se ne preoccupi.
- Inference — tecnicamente è l'"atto di prevedere", ma per chiarezza la consideri semplicemente come il risultato, ovvero la previsione restituita dalla funzione del modello (cioè: dati questi parametri, deduco questa risposta).
- Serving — usare la funzione in un programma caricando il file del modello e passandogli i parametri perché restituisca delle previsioni.
- Testing — passare al modello feature di test per ottenere previsioni e poi confrontare i risultati con i valori noti (label) di un gruppo di record.
- Accuracy — la percentuale di previsioni che corrispondono al risultato atteso sul totale dei record di test. Termini da approfondire più avanti: precision e recall.
Termini meno importanti ora, ma che torneranno utili in futuro:
- Theta — il peso moltiplicato per ciascuna feature al fine di restituire una previsione in base alla sua influenza percepita sul risultato. Un buon esempio è la previsione del valore delle case. Mettiamo che la vendita di una casa con 3 camere e 2 cucine sia di 200K $. Un'altra vendita di una casa con 3 camere e 1 cucina è sempre di 200K $. Una vendita di una casa con 4 camere è di 250K $. Il modello potrebbe assegnare un theta più alto (detto anche peso o importanza) alla feature "numero di letti" perché influenza il prezzo, e un theta più basso al numero di cucine perché ha avuto poco impatto.
- Hyperparameter tuning — se sa che certe feature sono più o meno importanti nel determinare il risultato, può applicare i Suoi pesi durante le fasi di pre-processing o di feature engineering per migliorare ulteriormente l'accuratezza delle previsioni. L'obiettivo è minimizzare la loss (detta anche penalty) per le previsioni sbagliate, in modo che le previsioni siano meno sensibili alle variazioni dell'input. È roba da nerd, lo so, quindi per ora la ignori.
Processo
Abbiamo imparato che il serving consiste nell'utilizzare una libreria software in grado di leggere ed eseguire il file del modello salvato (ad esempio joblib). Se avesse una API web che accetta parametri come tipo di cibo, piccantezza, dolcezza ecc., potrebbe fare load() del modello, passargli questi parametri e ottenere come predict() un 1 oppure uno 0. La Sua API interpreterà 1 = "good" e 0 = "bad" nella risposta agli utenti.
Abbiamo anche imparato che, per addestrare il modello, potrebbe essere necessario fare feature engineering. È il momento in cui identifica i valori relativi a quel cibo (observation) che possono influenzare l'esito e ne converte alcuni in numeri, in modo che possano essere dati in pasto a una funzione matematica. Mette poi da parte alcuni record noti (labeled) per testare l'accuratezza e addestra (fit) il modello finché l'accuratezza non migliora.
Ora vediamo un'applicazione pratica, prima di passare alla nostra implementazione vera e propria.
Applicare il machine learning a un problema di business
Trovo che spiegare le cose con esempi vicini al quotidiano aiuti molto. Immagini di avere un sito web e di volere più subscriber (per iscriversi a qualcosa). In passato ha investito cifre uguali su Google, Facebook, televisione, radio e stampa. Ha lo stesso budget pubblicitario per il prossimo anno e deve capire come spendere meglio i Suoi soldi per aumentare i nuovi subscriber netti del venti percento.
Deve capire quale percentuale del Suo budget pubblicitario allocare a ciascun fornitore per ottenere il maggior numero di nuovi subscriber.
Ha analizzato i nuovi subscriber mese per mese dell'anno scorso, insieme alla sorgente con relativi costi e numero di iscrizioni. Ha scoperto che la maggior parte è arrivata da Google, poi da Facebook, poi dalla televisione, e qualcuno da radio e stampa, ma le quantità variano a seconda della stagione, o addirittura del mese.
Se avessi speso importi diversi rispetto all'anno scorso con questi stessi fornitori, avrei potuto ottenere più iscrizioni?
Ha mai usato la "Ricerca obiettivo" in Excel?
Tradizionalmente, il tentativo di ottimizzare l'allocazione del budget partiva da un'ipotesi o una teoria, magari da qualche simulazione in un foglio di calcolo. Incolla i risultati dell'anno scorso e ogni riga riporta l'importo speso per ciascun fornitore, quanti nuovi subscriber ha portato, a quale costo e magari altri dati che ritiene rilevanti. Cambia questi valori più e più volte per vedere se ottiene un numero maggiore di subscriber.
È esattamente ciò che fa in automatico la funzionalità "Ricerca obiettivo" integrata in Excel, ma in pochi la usano o ne conoscono l'esistenza. Imposta un obiettivo come nell'esempio qui sotto ed Excel modifica iterativamente gli importi nelle altre celle finché non raggiunge il valore desiderato nella cella di output.
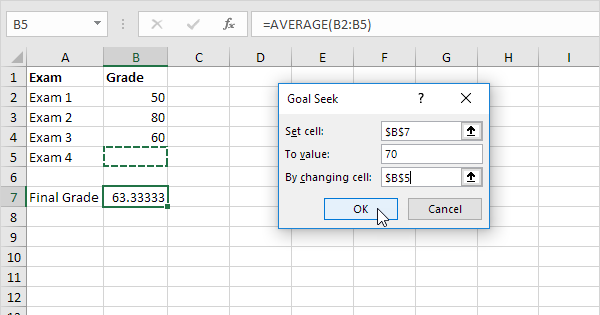
Usare la Ricerca obiettivo per trovare i valori ottimali
Tornando all'esempio della pubblicità, sta cercando di scoprire l'importanza relativa di ciascun tipo di pubblicità e di assegnare una percentuale (o un peso) del Suo budget totale. Sa quanti subscriber ha avuto l'anno scorso e ne vuole il 20% in più con lo stesso budget.
Imposta questo come valore obiettivo, poi modifica la % spesa per ciascun fornitore finché non raggiunge il Suo obiettivo. È così che vengono addestrati i modelli di machine learning: iterando sui dati e modificando i valori (i pesi moltiplicati per i parametri di input) finché non si avvicinano alle risposte note (labels).
Non si preoccupi se non tutto è ancora chiaro. Man mano che esplora l'applicazione e prosegue con la parte 2, e poi rileggerà questa, le cose inizieranno a quadrare (almeno spero).
Il machine learning porta la "Ricerca obiettivo" a un livello superiore
Dopo molti tentativi ed errori, trova il mix corretto (peso o percentuale per ciascun tipo di pubblicità) per raggiungere il Suo obiettivo. Supponga però che i Suoi dati comprendano 100 iscrizioni al giorno per 365 giorni l'anno e che giorni diversi abbiano portato più iscrizioni con un fornitore rispetto a un altro. Sarebbe troppo difficile cogliere le differenze in 36.500 righe di dati con fornitore, giorno della settimana, giorno dell'anno, visualizzazioni, click, conversioni, iscrizioni, costo per click o per impression e così via.
Spero sia chiaro che alcuni problemi non sono adatti a essere risolti dagli esseri umani, e questa è una di quelle funzioni che, a differenza dei gusti alimentari di Suo figlio, è probabilmente meglio automatizzare. Gli algoritmi di machine learning sono molto simili alla "Ricerca obiettivo", ma possono modificare iterativamente i valori in molte celle contemporaneamente e testare ogni cambiamento finché il valore di output non si avvicina al valore noto (label o class) per un dato input.
Prosegua con la parte 2 per vedere come è stata creata la demo qui sopra e per i link al codice sorgente.
Sa cosa fare!
- Condivida questo articolo con chiunque pensi possa essere interessato. Potrebbe essergli utile e aiuta moltissimo anche me!
- Mi regali 50 claps! (Basta tenere premuto il pulsante delle clap.)
- Si senta libero di lasciare un commento 💬.
