Hace varios años me propuse aprender más sobre IA y machine learning (ML) para ver cómo aplicarlo en mis propias empresas, o al menos poder conversar con criterio con nuestros equipos de ciencia de datos e ingeniería.
Tomé cursos en línea, vi videos y aprobé exámenes, pero seguía sin sentir que entendía de verdad cómo aplicar e integrar el machine learning en mi negocio. Me quedaron muchas preguntas sin responder. Si te suena familiar, sigue leyendo.
Demo
Para que te animes a leer este artículo y la parte 2 de la serie, ponte cómodo y mira primero esta demo de un pipeline de machine learning en funcionamiento.
La mayoría describe un ML pipeline como la serie de pasos para organizar y depurar datos, usarlos para entrenar modelos de machine learning y luego servir, o utilizar, esos modelos dentro de alguna aplicación. No te preocupes si todavía no tienen sentido estos términos.
Esta demo crea sus propios datos estructurados a partir de lo que ingresa el usuario, así que simplifica el proceso para que sea más fácil de entender — al menos eso espero. En el próximo artículo voy a compartir el código fuente y el enfoque para diseñarla y construirla.
Demo de cuatro minutos de una app de ML pipeline personalizada hospedada en Google Cloud Platform
Cerrando la brecha de vocabulario en ML
La mayoría de quienes venimos de ingeniería de software o de producto manejamos un lenguaje familiar con términos como clase, método, función, parámetro, input, request, variable, loop, output, return y response.
En el mundo del machine learning hay términos análogos como observation, model, dimension, feature, fit, train, test e inference. Súmale símbolos griegos como theta y la cabeza empieza a darte vueltas. Al principio puede ser abrumador, pero los iremos asimilando sobre la marcha.
En su forma más simple, un modelo de machine learning es una función matemática que, al recibir entradas numéricas, devuelve una salida numérica.
Creo que el problema con la enseñanza actual es que se tarda demasiado en entender cómo usar la tecnología, así que vamos a empezar con estas preguntas:
- ¿Cómo uso esta función en la vida real (lo que se conoce como serving)?
- ¿Cómo creo esta función (lo que se conoce como training)?
- ¿Qué técnicas funcionan mejor para cada tipo de problema?
TL;DR
Vayamos al grano y respondamos estas preguntas en el orden inverso al que se enseña habitualmente.
1. Servir tus modelos (usar tu función dentro de una app)
Los modelos de machine learning, también llamados funciones, se guardan en archivos. Hay librerías de software que pueden abrirlos, ejecutarlos, recibir entradas y devolver resultados.
Imagina estos archivos de modelo como mini "hojas de cálculo". Tienen algunas celdas con fórmulas. Cuando le pasas tu entrada a la "hoja de cálculo", esta coloca tus valores en las celdas (como las celdas amarillas de abajo) y calcula un valor de retorno, que es tu predicción (como la celda verde de abajo).
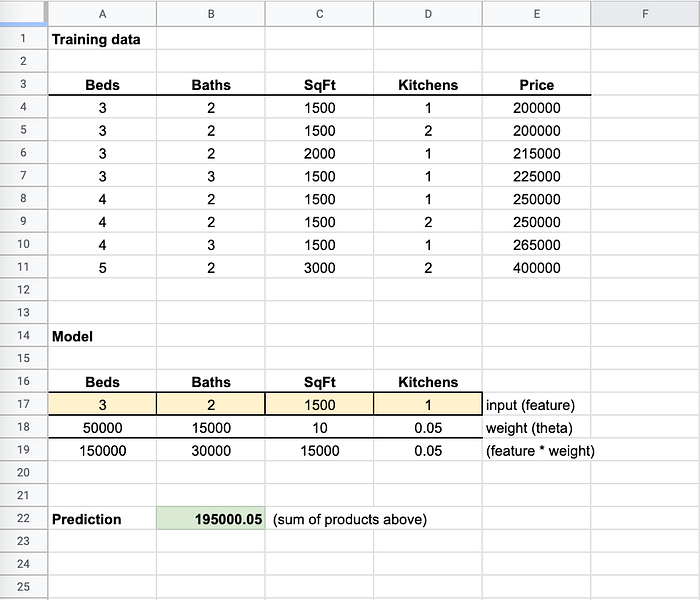
El entrenamiento sigue ajustando los pesos hasta que la predicción se acerca al precio real
Fíjate que en mis datos de entrenamiento (hablaremos más de esto abajo), tener 1 cocina o 2 cocinas no cambiaba el precio. Por eso el peso (multiplicador) es casi 0: no es una feature relevante para determinar el precio.
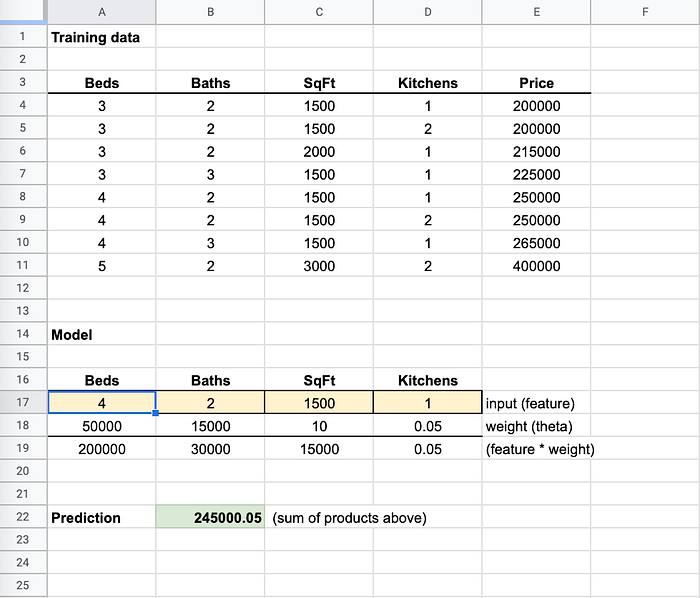
Cambio camas a "4" y el resultado se acerca bastante a los valores de 250000 en los datos de entrenamiento
Cuando cambié las "Camas" a "4", la predicción se acercó al valor de 250.000. Los algoritmos de ML ajustan los pesos en fracciones diminutas para acercarse lo más posible a la precisión en todas las entradas. Por eso es muy raro tener un 100 % de precisión.
Un formato popular de archivo de modelo se llama pickle, y una herramienta para crearlos y ejecutarlos es joblib. Otros frameworks como TensorFlow y PyTorch tienen sus propios formatos, y existen iniciativas para crear formatos universales que hagan los modelos más portables.
Para usar tu modelo en tu aplicación (serving), tal como se ilustra arriba, importas la versión de la librería compatible con la que se creó el archivo, lo cargas con load() y luego invocas predict() como cualquier otra función en tus programas. Más adelante voy a compartir un ejemplo funcional, ¡pero realmente eso es todo!
2. Entrenar tus modelos (construir tu función)
Vamos a entrar en más detalle después, pero supón que quieres ingresar una comida y predecir si a tu hijo le va a gustar; ¡todos sabemos a dónde va esto! ;-)
Tradicionalmente escribirías una función a mano como esta, con reglas conocidas:
Tus entradas (features) podrían ser atributos sobre la comida como tipo, olor, picante, temperatura, contenido de azúcar o color. Tu salida predicha (inference) es "buena" o "mala".
El problema de escribir tu función manualmente es si realmente sabes cuál es la temperatura, dulzura u olor ideal y qué factores pesan más para que un niño decida si algo es "bueno" o "malo". Este enfoque es prueba y error en el mejor de los casos.
Ahora imagina que tus datos son diez mil registros. Tu cerebro no puede recordar ni correlacionar todos esos valores para determinar dónde está el punto de corte para el nivel de picante, la temperatura, el olor y la dulzura. Si usas una computadora y le pasas todos esos datos, los procesa, normalmente en cuestión de segundos, y define una función matemática que va a devolver las predicciones correctas. Eso es lo que el machine learning nos ayuda a hacer.
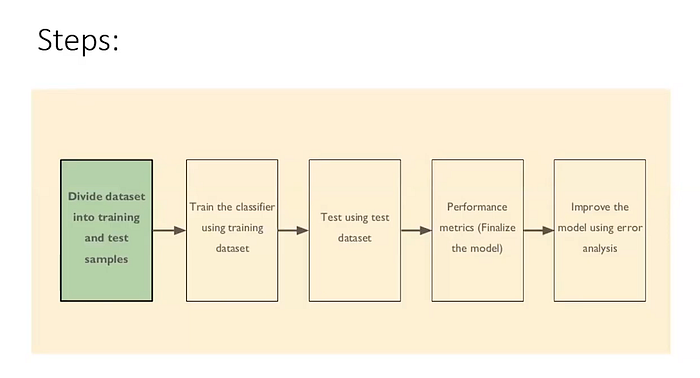
Vista general del entrenamiento de un modelo de ML
Mantengámoslo simple por ahora con el código de abajo:
Este es un ejemplo simplificado para "desmitificar" qué es el machine learning. En lugar de escribir tú mismo la función y las reglas, usas un algoritmo que multiplica iterativamente distintos pesos a cada valor de entrada hasta que devuelve las respuestas correctas la mayor parte del tiempo (recuerda la hoja de cálculo de arriba).
Supón que ingresas 100 registros y aparece un patrón: cada vez que el color de la comida era 4, el resultado era 0 ("mala"). La función empieza a escribirse a sí misma a medida que descubre estas reglas, igual que tu función manual tenía reglas. La respuesta (inference) es mayormente correcta porque creaste la función (entrenaste tu modelo) a partir de datos que ya tenías con las respuestas correctas (labels).
Imagina que un mes después tu hijo dice que le gusta el brócoli. Es verde, así que tienes que averiguar cómo reescribir tu primera función para tomarlo en cuenta. A medida que los datos cambian, esto se vuelve cada vez más complicado. Con machine learning, simplemente alimentas la nueva información y reentrenas tu modelo hasta que las predicciones sean precisas. Ese es el poder que ofrece.
3. ¿Qué técnicas funcionan mejor para cada tipo de problema?
Vamos a saltarnos esto. La mayoría de los cursos de IA empiezan con las categorías de algoritmos de ML y creo que eso complica el aprendizaje. Por ahora, ignóralo. Primero gana comprensión y después amplía tu conocimiento.
Repaso de lo aprendido hasta ahora
Lo que espero que te haya quedado claro es que sí puedes crear manualmente una función como la de arriba y plantear restricciones del tipo "si es vegetal, es mala", y potencialmente obtener resultados precisos.
A medida que el tipo de predicción se vuelve más complejo, la velocidad se vuelve crítica o hay más puntos de datos a considerar, se supera la capacidad de adivinar mentalmente con seguridad, y ahí es donde el machine learning entra en juego.
Terminología
- Model — una función matemática generada por un programa que aplica pesos únicos a valores numéricos de entrada y devuelve un resultado numérico.
- Feature — un valor numérico de entrada o parámetro (también conocido como dimension) que le pasas a tu función para que devuelva una predicción.
- Label — una respuesta conocida para datos pasados (también llamada class). Por ejemplo, en los gustos de comida del niño ya sabíamos que le gustaban la pizza y el pastel y no las espinacas, así que le dimos a la pizza y al pastel un valor de 1 ("buena"), y a las espinacas un valor de 0 ("mala").
- Observation — un conjunto de features recopiladas sobre una entrada en particular, como las features que extrajimos de la pizza.
- Feature engineering — identificar los atributos de una observación dada que probablemente influyen en el resultado y convertirlos a valores numéricos para poder construir una función matemática en lugar de una escrita a mano. Por ejemplo, convertimos colores y tipos de comida en números usando su índice de array en vez del valor de string (también conocido como feature extraction).
- Training — iterar repetidamente sobre un conjunto de datos, probando distintos pesos (theta) en cada feature hasta que la mayoría de los resultados sean correctos.
- Fit — detrás de escena, tu algoritmo de ML intenta encontrar las coordenadas de una línea que pueda separar los registros "buenos" de los "malos", de modo que los registros futuros que caigan a un lado de la línea sean "buenos" y los que caigan al otro sean "malos". Eso es básicamente lo que hace el entrenamiento, pero no te preocupes por ello ahora mismo.
- Inference — técnicamente es el "acto de predecir", pero por claridad considéralo simplemente el resultado, o predicción, que devuelve la función de tu modelo (es decir: dados estos parámetros, infiero esta respuesta).
- Serving — usar tu función dentro de un programa cargando el archivo del modelo y pasándole parámetros para que devuelva predicciones.
- Testing — pasarle features de prueba al modelo para obtener predicciones y luego comparar el resultado con los valores conocidos (labels) en un grupo de registros.
- Accuracy — el porcentaje de predicciones que coincidieron con el resultado esperado sobre el total de registros de prueba. Términos para investigar más adelante: precision y recall.
Términos menos importantes ahora, pero que aparecerán más adelante:
- Theta — el peso por el que se multiplica cada feature para devolver una predicción según su influencia percibida en el resultado. Un buen ejemplo es predecir el valor de viviendas. Quizás una venta de una casa de 3 dormitorios con 2 cocinas es de $200K. Otra venta de una casa de 3 dormitorios con 1 cocina es también de $200K. Y una venta de una casa de 4 dormitorios es de $250K. El modelo puede asignar un theta más alto (también llamado peso o importancia) a la feature "número de camas" porque influye en el precio, y un theta más bajo al número de cocinas porque casi no impacta.
- Hyperparameter tuning — si sabes que ciertas features son más o menos importantes para el resultado, puedes aplicar tus propios pesos durante los pasos de pre-procesamiento o feature engineering para mejorar aún más la precisión de tus predicciones. El objetivo es minimizar la pérdida (también conocida como penalty) en las malas predicciones, de modo que sean menos sensibles a las variaciones de entrada. Es geek, lo sé, así que ignóralo por ahora.
Proceso
Aprendimos que servir consiste en usar una librería de software que pueda leer y ejecutar tu archivo de modelo guardado (por ejemplo, joblib). Si tuvieras una API web que aceptara parámetros como tipo de comida, picante, dulzura, etc., podrías hacer load() de tu modelo, pasarle estos parámetros y obtener un predict() con un 1 o un 0. Tu API interpreta 1 = "buena" y 0 = "mala" en la respuesta a los usuarios.
También aprendimos que para entrenar tu modelo puede que tengas que hacer feature engineering. Ahí es donde identificas los valores relacionados con esa comida (observation) que pueden influir en el resultado y conviertes algunos a números para poder alimentar una función matemática. Después apartas algunos registros conocidos (labeled) para probar tu precisión y entrenas (fit) tu modelo hasta que la precisión mejore.
Ahora veamos una aplicación práctica antes de meternos en la implementación real.
Aplicar machine learning a un problema de negocio
Creo que ayuda explicar las cosas con ejemplos cercanos. Imagina que tienes un sitio web y quieres más suscriptores (que se registren para algo). En el pasado, gastaste cantidades iguales en Google, Facebook, televisión, radio y prensa. Tienes el mismo presupuesto de publicidad para el próximo año y necesitas saber dónde gastar mejor tu dinero para aumentar los nuevos suscriptores netos en un veinte por ciento.
Necesitas averiguar qué porcentaje de tu gasto en publicidad asignar a cada proveedor para conseguir la mayor cantidad posible de nuevos suscriptores.
Analizaste mes a mes los nuevos suscriptores del año pasado, junto con la fuente, su costo respectivo y la cantidad de registros. Descubriste que la mayoría de los suscriptores vinieron de Google, después de Facebook, luego de televisión, y unos pocos de radio y prensa, pero las cantidades varían según la temporada, e incluso por mes.
Si hubiera gastado cantidades distintas a las del año pasado con estos mismos proveedores, ¿podría haber sumado más suscriptores?
¿Alguna vez has usado ‘Goal Seek’ en Excel?
Tradicionalmente, tu intento de optimizar la asignación del presupuesto pudo haber empezado con una corazonada o una teoría, y después tal vez algunas simulaciones en una hoja de cálculo. Pegas los resultados del año pasado y cada fila incluye lo que gastaste en cada proveedor, cuántos nuevos suscriptores aportó cada uno y a qué costo, y posiblemente otros datos que crees relevantes. Cambias estos valores una y otra vez para ver si obtienes un mayor número de suscriptores.
Eso es justamente lo que hace de forma automática la función ‘Goal Seek’ integrada en Excel, aunque pocos la usan o siquiera la conocen. Estableces una meta, como en el ejemplo de abajo, y la herramienta va cambiando iterativamente las cantidades en otras celdas hasta alcanzar el valor deseado en la celda de salida.
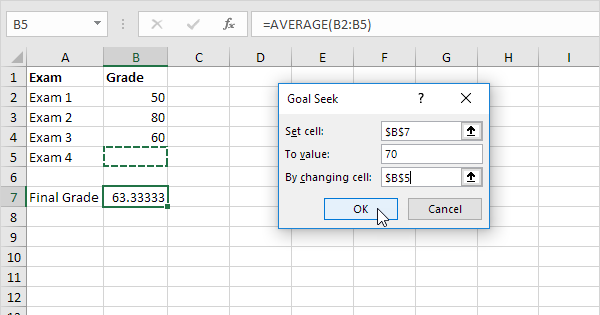
Usando Goal Seek para encontrar los valores óptimos
Si piensas en el ejemplo de la publicidad, lo que estás tratando de encontrar es la importancia relativa de cada tipo de publicidad y asignar un porcentaje (o peso) de tu presupuesto total. Sabes cuántos suscriptores tuviste el año pasado y quieres un 20 % más con el mismo presupuesto.
Defines eso como tu valor objetivo y luego vas cambiando el % gastado en cada proveedor hasta lograr la meta. Así es como se entrenan los modelos de machine learning: iterando sobre los datos y modificando valores (pesos multiplicados por los parámetros de entrada) hasta acercarse a las respuestas conocidas (labels).
No te preocupes si todavía no termina de cuadrarte. A medida que explores la aplicación y veas más en la parte 2, y luego vuelvas a esta parte, las cosas van a empezar a "encajar" (eso espero).
El machine learning lleva ‘Goal Seek’ al siguiente nivel
Después de mucha prueba y error, encuentras la mezcla correcta (peso o porcentaje para cada tipo de publicidad) para alcanzar tu meta. Pero supón que tus datos incluyen 100 registros por día durante los 365 días del año, y que distintos días generaron más registros con un proveedor que con otro. Sería demasiado difícil identificar las diferencias en 36.500 filas de datos con el proveedor, día de la semana, día del año, vistas, clics, conversiones, registros, costo por clic o por impresión, etc.
Espero que quede claro que algunos problemas simplemente no son aptos para que los resuelvan los humanos, y esta es una de esas funciones que, a diferencia de los gustos de comida de tu hijo, conviene automatizar. Los algoritmos de machine learning se parecen mucho a ‘Goal Seek’, pero pueden cambiar iterativamente los valores en muchas celdas a la vez y probar cada cambio hasta que el valor de salida se acerque al valor conocido (label o class) para cualquier entrada dada.
Continúa con la parte 2 para ver cómo se creó la demo de arriba y los enlaces al código fuente.
¡Ya sabes qué hacer!
- Comparte esto con cualquier persona que creas que pueda interesarle. ¡Le puede servir, y a mí me ayuda muchísimo!
- ¡Dame 50 aplausos! (Solo mantén presionado el botón de aplauso.)
- Y no dudes en dejar un comentario 💬.
