Há alguns anos, resolvi me aprofundar em IA e machine learning (ML) para entender como aplicar isso nas minhas empresas, ou pelo menos conseguir conversar de igual para igual com nossos times de ciência de dados e engenharia.
Fiz cursos online, assisti a vídeos e passei em provas, mas nunca senti que tinha entendido de verdade como aplicar e integrar machine learning ao meu negócio. Muita pergunta ficava no ar. Se você se identifica com isso, continue a leitura.
Demo
Para te dar um gostinho do que vem por aí neste artigo e na parte 2 desta série, fique à vontade e assista primeiro a esta demo de um pipeline de machine learning em funcionamento.
A maioria das pessoas descreve um pipeline de ML como a sequência de etapas para organizar e refinar dados, usá-los para treinar modelos de machine learning e depois servir, ou usar, esses modelos dentro de alguma aplicação. Não se preocupe se esses termos ainda não fizerem sentido.
Esta demo gera os próprios dados estruturados a partir do que o usuário informa, o que simplifica o processo e facilita o entendimento — pelo menos é o que espero. No próximo artigo, vou compartilhar o código-fonte e a abordagem usada para projetar e construir tudo.
Demo de quatro minutos do app de pipeline de ML personalizado hospedado no Google Cloud Platform
Preenchendo a lacuna de vocabulário em ML
Quem tem formação em engenharia de software ou produto, como eu, fala uma linguagem familiar com termos como class, method, function, parameter, input, request, variable, loop, output, return e response.
No mundo do machine learning existem termos análogos como observation, model, dimension, feature, fit, train, test e inference. Some a isso símbolos gregos da matemática, como theta, e a cabeça começa a girar. Pode parecer assustador no começo, mas vamos absorver esses termos aos poucos, conforme avançamos.
Em sua forma mais simples, um modelo de machine learning é uma função matemática que, ao receber entradas numéricas, devolve uma saída numérica.
Acredito que um problema do ensino atual é demorar tempo demais para mostrar como usar a tecnologia, então vamos começar por estas perguntas:
- Como uso essa função na vida real (ou seja, serving)?
- Como crio essa função (ou seja, training)?
- Quais técnicas funcionam melhor para cada tipo de problema?
TL;DR
Vamos direto ao ponto, respondendo a essas perguntas na ordem inversa daquela que a maioria ensina.
1. Servindo seus modelos (usando sua função em um app)
Modelos de machine learning, ou seja, funções, ficam armazenados em arquivos. Bibliotecas de software conseguem abrir e executar esses arquivos, receber entradas e retornar resultados.
Pense nesses arquivos de modelo como mini "planilhas". Elas têm algumas células com fórmulas. Quando você passa sua entrada para a "planilha", ela coloca seus valores em algumas células (como as amarelas abaixo) e calcula um valor de retorno, que é sua previsão (como a célula verde abaixo).
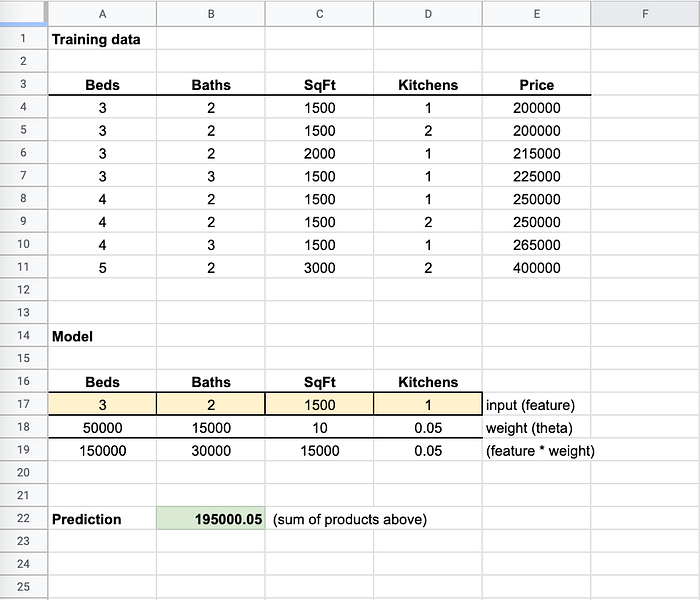
O treinamento vai mudando os pesos até que a previsão fique próxima do preço real
Repare que, nos meus dados de treino (já vamos falar mais sobre isso), ter 1 cozinha ou 2 cozinhas não mudava o preço. Por isso o peso (multiplicador) é praticamente 0: não é uma feature relevante para definir o preço.
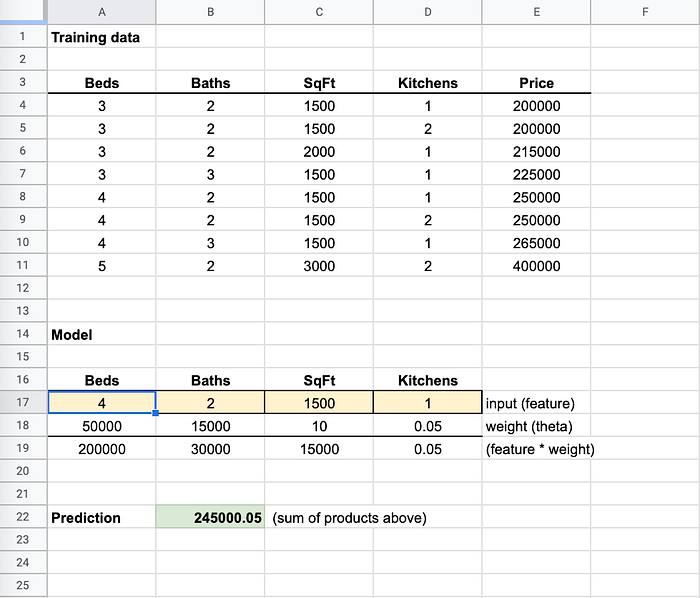
Mudei beds para "4" e o resultado ficou bem perto dos 250000 dos dados de treino
Quando alterei "Beds" para "4", a previsão ficou bem próxima do valor de 250.000. Os algoritmos de ML ajustam os pesos em frações minúsculas para deixá-los o mais precisos possível para todas as entradas. Por isso é raríssimo chegar a 100% de acurácia.
Um formato popular de arquivo de modelo é o pickle, e uma ferramenta para criar e executar esses arquivos é a joblib. Outros frameworks, como TensorFlow e PyTorch, têm formatos próprios, e já existem iniciativas de formatos universais para tornar os modelos mais portáveis.
Para usar seu modelo em uma aplicação (serving) como na ilustração acima, você importa a versão compatível da biblioteca usada para criar o arquivo, faz load() dele e, em seguida, chama predict() como faria com qualquer outra função nos seus programas. Mais adiante eu mostro um exemplo funcional, mas é basicamente isso!
2. Treinando seus modelos (construindo sua função)
Vamos detalhar mais para frente, mas suponha que você queira receber um alimento como entrada e prever se seu filho vai gostar; todo mundo já sabe onde isso vai dar! ;-)
Tradicionalmente, você escreveria uma função na mão, com regras conhecidas, mais ou menos assim:
Suas entradas (features) podem ser atributos do alimento, como tipo, cheiro, tempero, temperatura, teor de açúcar ou cor. Sua saída prevista (inference) é "good" ou "bad".
O problema de escrever essa função manualmente é que nem sempre você sabe qual é a temperatura, doçura ou cheiro ideal nem quais fatores pesam mais para a criança decidir se algo é "good" ou "bad". Essa abordagem é, na melhor das hipóteses, tentativa e erro.
Agora imagine que você tenha dez mil registros. Seu cérebro não vai conseguir guardar e correlacionar todos esses valores para encontrar o ponto de corte de tempero, temperatura, cheiro e doçura. Já um computador, com todos esses dados em mãos, consegue fazer isso normalmente em segundos e definir uma função matemática que devolve as previsões corretas. É justamente nisso que o machine learning ajuda.
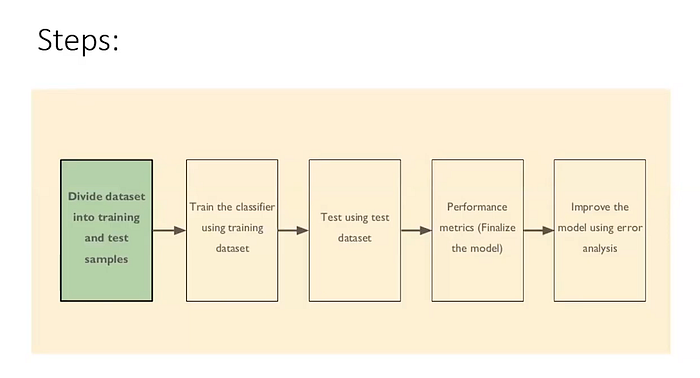
Visão geral do treinamento de um modelo de ML
Vamos manter as coisas simples por enquanto, com o código abaixo:
Esse é um exemplo simplificado para "desmistificar" o que é machine learning. Em vez de escrever a função e as regras manualmente, você usa um algoritmo que, de forma iterativa, multiplica diferentes pesos por cada valor de entrada até que ele passe a retornar as respostas certas na maior parte das vezes (lembre-se da planilha acima).
Suponha que você passe 100 registros e surja um padrão: toda vez que a cor do alimento era 4, o resultado era 0 ("bad"). A função começa a se escrever sozinha conforme descobre essas regras, exatamente como sua função manual tinha regras. A resposta (inference) costuma ser correta porque você criou a função (treinou seu modelo) com base em dados que já tinha com as respostas certas (labels).
Agora imagine que, um mês depois, seu filho diga que gosta de brócolis. Brócolis é verde, então você precisa descobrir como reescrever sua primeira função para dar conta disso. À medida que os dados mudam, isso fica cada vez mais difícil. Com machine learning, basta alimentar a nova informação e retreinar o modelo até que as previsões fiquem precisas. É esse o poder que ele oferece.
3. Quais técnicas funcionam melhor para cada tipo de problema?
Vamos pular essa parte. A maioria dos cursos de IA começa pelas categorias de algoritmos de ML, e acho que isso só complica o aprendizado. Por enquanto, deixe de lado. Primeiro construa o entendimento; depois aprofunde o conhecimento.
Recapitulando o que aprendemos até aqui
Espero que tenha ficado claro que dá sim para criar manualmente uma função como a de cima, chutar restrições do tipo "se for vegetal, é ruim" e até obter resultados razoavelmente precisos.
À medida que o tipo de previsão fica mais complexo, que a velocidade vira algo crítico ou que aparecem mais pontos de dados para considerar, a coisa ultrapassa nossa capacidade de adivinhar de cabeça com segurança — e é aí que entra o machine learning.
Terminologia
- Model — função matemática gerada por um programa de computador que aplica pesos específicos a valores numéricos de entrada e retorna um resultado numérico.
- Feature — valor numérico de entrada ou parâmetro (também chamado de dimension) que você passa para sua função para que ela retorne uma previsão.
- Label — resposta conhecida para dados passados (também chamada de class). No caso dos gostos do nosso filho, já sabíamos que ele gostava de pizza e bolo e não gostava de espinafre, então atribuímos o valor 1 ("good") para pizza e bolo e o valor 0 ("bad") para espinafre.
- Observation — conjunto de features coletadas sobre uma entrada específica, como as features que extraímos da pizza.
- Feature engineering — identificar os atributos de uma observação que provavelmente influenciam o resultado e convertê-los em valores numéricos para construir uma função matemática em vez de uma escrita à mão. Foi o que fizemos ao converter cores e tipos de alimento em números, usando o índice no array em vez do valor em string (também chamado de feature extraction).
- Training — iterar repetidamente sobre um conjunto de dados, testando diferentes pesos (theta) em cada feature até que a maior parte dos resultados esteja correta.
- Fit — nos bastidores, seu algoritmo de ML está tentando descobrir as coordenadas de uma linha que separe registros "good" de "bad", de modo que registros futuros plotados de um lado da linha sejam "good" e os do outro sejam "bad". É basicamente isso que o treinamento faz, mas não se preocupe com isso agora.
- Inference — tecnicamente é o "ato de prever", mas, para simplificar, pense nisso como o resultado, ou previsão, retornado pela função do seu modelo (ou seja, dados estes parâmetros, eu infiro esta resposta).
- Serving — usar sua função em um programa, carregando o arquivo do modelo e passando parâmetros para que ele retorne previsões.
- Testing — passar features de teste para o modelo a fim de obter previsões e, depois, comparar o resultado com os valores conhecidos (labels) de um grupo de registros.
- Accuracy — percentual de previsões que coincidiram com o resultado esperado, dentre todos os registros de teste. Termos para pesquisar mais para frente: precision e recall.
Termos menos importantes agora, mas que vão aparecer mais para frente:
- Theta — peso multiplicado por cada feature para gerar uma previsão com base na influência percebida sobre o resultado. Um bom exemplo é prever valores de imóveis. Imagine que a venda de uma casa de 3 quartos com 2 cozinhas saia por US$ 200 mil. Outra venda, de uma casa de 3 quartos com 1 cozinha, também saia por US$ 200 mil. Já a venda de uma casa de 4 quartos sai por US$ 250 mil. O modelo pode atribuir um theta maior (também chamado de peso ou importância) à feature "número de quartos", porque ela influencia o preço, e um theta menor ao número de cozinhas, que teve pouco impacto.
- Hyperparameter tuning — se você sabe que certas features são mais ou menos importantes para o resultado, pode aplicar seus próprios pesos durante o pré-processamento ou nas etapas de feature engineering para melhorar ainda mais a acurácia das previsões. O objetivo é minimizar a perda (também chamada de penalty) por previsões ruins, deixando-as menos sensíveis a variações nas entradas. É bem técnico, eu sei, então deixe para depois.
Processo
Aprendemos que serving é usar uma biblioteca de software capaz de ler e executar o arquivo do seu modelo salvo (a joblib, por exemplo). Se você tivesse uma API web que aceitasse parâmetros como tipo de alimento, tempero, doçura etc., poderia chamar load() no seu modelo, passar esses parâmetros e fazê-lo retornar predict() com 1 ou 0. Sua API interpreta 1 = "good" e 0 = "bad" na resposta para os usuários.
Também aprendemos que, para treinar seu modelo, talvez seja necessário fazer feature engineering. É aqui que você identifica valores relacionados àquele alimento (observation) que possam influenciar o resultado e converte alguns deles em números para que possam alimentar uma função matemática. Em seguida, você separa alguns registros conhecidos (labeled) para testar a acurácia e treina (fit) o modelo até que a acurácia melhore.
Agora vamos olhar para uma aplicação prática antes de mergulhar na nossa implementação de fato.
Aplicando machine learning a um problema de negócio
Acho que ajuda explicar as coisas com exemplos do dia a dia. Imagine que você tem um site e quer mais assinantes (que se inscrevam em algo). No passado, você gastava valores iguais em Google, Facebook, televisão, rádio e mídia impressa. Você tem o mesmo orçamento de publicidade para o próximo ano e precisa saber onde investir melhor para aumentar em 20% o número líquido de novos assinantes.
Você precisa descobrir qual percentual do investimento em publicidade alocar a cada veículo para conquistar o maior número possível de novos assinantes.
Você analisou os novos assinantes de cada mês do ano passado, junto com a origem, o custo correspondente e o número de inscrições. Descobriu que a maioria dos assinantes veio do Google, depois do Facebook, depois da televisão, e poucos do rádio e da mídia impressa, mas os números variam de acordo com a temporada, ou até de mês para mês.
Se eu tivesse gastado valores diferentes do ano passado com esses mesmos veículos, será que teria conseguido mais inscrições?
Você já usou o ‘Goal Seek’ no Excel?
Tradicionalmente, sua tentativa de otimizar a alocação do orçamento começaria com um palpite ou uma teoria e, talvez, algumas simulações em uma planilha. Você cola os resultados do ano passado, e cada linha mostra quanto você gastou com cada veículo, quantos novos assinantes cada um trouxe e a que custo, além de outros pontos de dados que você considere relevantes. Aí muda esses valores várias vezes para ver se chega a um número maior de assinantes.
É exatamente isso que o recurso ‘Goal Seek’, embutido no Excel, faz automaticamente — só que pouca gente usa ou conhece. Você define uma meta, como no exemplo abaixo, e ele altera iterativamente os valores em outras células até chegar ao valor desejado na célula de saída.
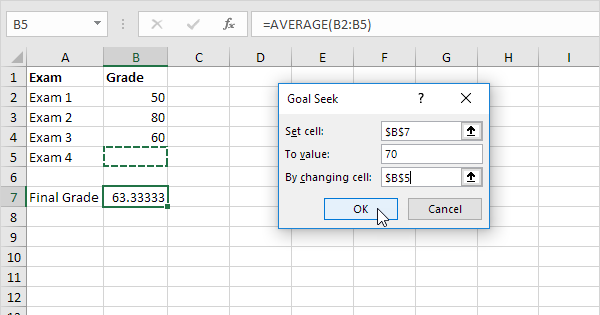
Usando o Goal Seek para encontrar valores ótimos
Voltando ao exemplo da publicidade, você está tentando descobrir a importância relativa de cada tipo de anúncio e alocar um percentual (ou peso) do seu orçamento total. Você sabe quantos assinantes teve no ano passado e quer 20% a mais com o mesmo orçamento.
Você define isso como o seu valor-alvo e, então, altera o % gasto em cada veículo até bater a meta. É assim que modelos de machine learning são treinados: iterando pelos dados e mudando valores (pesos multiplicados pelos parâmetros de entrada) até chegar mais perto das respostas conhecidas (labels).
Não se preocupe se ainda não fizer todo sentido. Conforme você explorar a aplicação e mais detalhes na parte 2 e depois revisitar esta parte, as coisas vão começar a "se encaixar" (espero).
Machine learning leva o ‘Goal Seek’ a outro nível
Depois de muita tentativa e erro, você encontra a combinação certa (peso ou percentual para cada tipo de publicidade) para alcançar sua meta. Mas, digamos que seus dados incluam 100 inscrições por dia ao longo dos 365 dias do ano e que dias diferentes resultaram em mais inscrições com um veículo do que com outro. Seria difícil demais identificar as diferenças em 36.500 linhas de dados, considerando veículo, dia da semana, dia do ano, visualizações, cliques, conversões, inscrições, custo por clique ou por impressão etc.
Espero que esteja claro que alguns problemas simplesmente não são adequados para um humano resolver, e este é uma dessas funções que, ao contrário dos gostos alimentares do seu filho, é melhor automatizar. Algoritmos de machine learning se parecem muito com o ‘Goal Seek’, só que conseguem alterar iterativamente os valores em várias células ao mesmo tempo e testar cada mudança até a saída ficar mais próxima do valor conhecido (label ou class) para qualquer entrada.
Continue na parte 2 para ver como a demo acima foi criada e os links para o código-fonte.
Você já sabe o que fazer!
- Compartilhe com qualquer pessoa que possa se interessar. Pode ser útil para ela — e ajuda muito a mim também!
- Por favor, me dê 50 palmas! (Basta segurar o botão de palmas.)
- Fique à vontade para deixar um comentário 💬.
