
Streaming Engineを活用する
もっとも手軽なコスト削減策のひとつが、Streaming Engineの有効化です。Streaming Engineを使わない場合、Autoscalerはワーカー数を判断する指標として永続ディスクを参照します。実行中のジョブからディスクが取り外されることはなく、各ワーカーには最低1本の永続ディスクが必要で、しかもワーカー間で接続ディスク数が揃っている必要があります。そのためDataflowは、ディスクを均等に分配する制約上、ワーカー数を最大でも50%までしか縮小できません。一方、Streaming Engineを有効化すると、shuffleやgroupByKeyといった処理の多くがStreaming Engineサービス側にオフロードされ、Dataflowのオートスケーリングが接続ディスクに縛られなくなります。これにより、ディスクサイズを30GBまで小さくすることも可能になります。
Streaming Engineは、Java(SDK => 2.11.0)とPython(SDK => 2.21.0)のパイプラインに対応しています。
Java: - enableStreamingEngine
Python: enabled by default.
Go: Not supported yet.
最大ワーカー数
かつてAutoscalingと呼ばれていたHorizontal Autoscalingは、ジョブに必要なワーカー数を自動で決定します。デフォルトの最大ワーカー数は、バッチジョブで1000、ストリーミングジョブで100です。
最大ワーカー数を絞ればコストを抑えられますが、大量のデータを1ワーカーだけで処理しようとすると、完了までに途方もない時間がかかります。ビジネス要件とデータのスパイク特性をふまえ、適切な数を選びましょう。経験則として、ジョブの80%の時間で必要となるワーカー数に対して、もう10台ほど上乗せした値を推奨します。こうしておけば、スパイク発生時の余力をワーカープールに確保できます。スパイクがさらに大きく、Dataflowのバックログがなかなか減らない場合は、もう少しワーカー数を増やす必要があります。
Streaming Engineを使わない場合は、最大ワーカー数と同じだけの永続ディスクが固定的にデプロイされる点を忘れないでください。最大ワーカー数は次のフラグで設定できます。
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
並列化
DataflowはGoogleが開発したマネージドサービスで、大規模な分散データ処理に利用できます。Dataflowのコストの大半はコンピューティングリソースが占めるため、利用可能なリソースをどれだけ効率よく使えるかが鍵になります。いくつかのパイプラインパラメータを使えば、適切なリソース上で並列度を細かく調整できます。Dataflowは大量データの処理を前提に設計されており、多くの作業が並列実行されます。並列度を高める手段は2つ、ワーカーを増やすか、ワーカーごとのスレッド数を増やすかです。本記事では「ワーカーごとのスレッド数」を並列化と呼ぶことにします。
ワーカー単位の並列化はコスト削減に直結します。同じワーカーで処理できる要素が増えれば、Dataflowが必要とするワーカーの総数を減らせるからです。
マシンタイプと同時実行スレッド
Dataflowのコストの大半はコンピューティングリソースに費やされます。だからこそ、ジョブに合ったマシンタイプを選ぶことが重要です。Google Cloud Platformでは多種多様なマシンタイプが用意されています。
メモリ集約型のワークロードでは、新しいN2より旧来のN1の方がやや安く済みます。
一方、CPU負荷の高いジョブには、より一般的に使われる新しいN2シリーズが向いています。N2シリーズには、N2-standard、N2 high-mem、N2 high-CPUの3タイプがあります。standardはvCPUあたり4GB、high-memはvCPUあたり8GB、high-CPUはvCPUあたり1GBのメモリを提供します。料金はこちらで確認できます。
Dataflowはワークロードを並列実行できます。ストリーミングモードでは、Dataflowはスレッドごとに1つのDoFnを実行します。ここで押さえておきたいのが、Python SDKの並列化はJavaやGo SDKと挙動が異なるという点です。Pythonは1プロセスを起動し、デフォルトでvCPUあたり12スレッドを動かすのに対し、GoとJavaは1プロセスでVMあたり300スレッドを動かします。Python SDKのデフォルトスレッド数は選択したマシンタイプのvCPU数によって決まります。たとえばn2-standard-2なら2 vCPUで(2×12=)24スレッド、n2-standard-8なら8 vCPUで(8×12=)96スレッドがデフォルトです。
Dataflowでは、SDKに応じてvCPUまたはVMあたりのスレッド数を設定できます。これはWorker harness threadsと呼ばれます。
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
ニーズやワークロードに応じて並列度は変えられます。複数のスレッドが同じメモリ空間を共有するため、メモリ集約型のジョブではスレッド数を抑えるのが定石です。逆に負荷が軽いワークロードであれば、スレッド数を増やしてより多くの処理を並列に走らせられます。並列度が高いほど、1ワーカーで扱える要素も増えていきます。ただし、並列化を欲張りすぎるとさまざまなトラブルを招きます。もっとも多いのがOut Of Memoryで、その場合Dataflowは該当作業をリトライします。また、APIなどサードパーティのリソースを呼び出している場合は、相手側がその呼び出し量に耐えられるかにも注意が必要です。
Fusion最適化
コードをDataflowランナーに送信すると、Dataflowはまずコンパイルを行い、コードをもとに実行グラフを生成します。このグラフはGoogle Cloud Consoleで確認可能です。詳細はこちらのリンクをご覧ください。グラフが生成・検証された後、Dataflowサービスは最適化のためにグラフを書き換えることがあります。代表的な最適化のひとつが、複数のステップを大きな処理にまとめる(fuseする)ことで、ステップ間でデータをマテリアライズする手間を省くというものです。これにより、複数の処理をメモリ上で続けて実行できるため処理は速くなりますが、結合されたステップ群はすべて同じマシン上での実行を強いられます。Fusion最適化はDataflowの強みの根幹を成す一方で、パイプラインのボトルネックを生むこともあります。Fusion最適化はデータが流れる前のコードベースのグラフに基づくため、Dataflowは並列化を阻害する次のようなケースを検知できません。
図1: Wordcountサンプルの最適化された実行グラフ。Java WordCountのサンプル
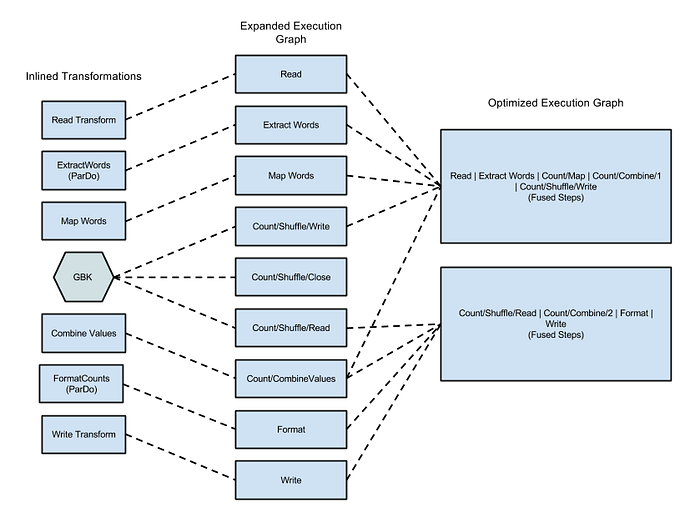
このサンプルをDataflowランナーで実行した際のグラフが、Dataflowのドキュメントに掲載されています。
High Fanout
あるParDoが入力よりはるかに多くの要素を出力する場合は、データのreshuffleを検討しましょう。たとえばファイルを入力として処理し、各行を個別の要素として出力するケースです。このParDoのあと、Dataflowは想定よりもはるかに多くのアイテムを同じワーカー上で処理することになります。Dataflowはfusionステップに必要なインスタンス数を、入力アイテム数の見込みから決めるためです。fusionを断ち切ると、Dataflowはワークロードを再分配し、より多くのアイテムを並列に処理できるようになります。
マシン間でデータが偏っている
サイズの異なるファイルを入力として扱うジョブでは、パイプラインを流れるデータ量が偏りがちです。一部のワーカーが他より圧倒的に多くを処理することになり、reshuffleを行わないと、あるマシンはアイドル状態のまま、別のマシンはフル稼働、といった事態が起こります。
[fusionを解除する](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion)方法は3つあります:
- GroupByKey(Dataflowは集約ステップを決してfuseしません)。Dataflowは集約ステップを決してfuseしません。
- 中間PCollectionをside inputとして渡す。side inputは常にマテリアライズされるため、これらのステップをfuseする意味がありません。
- Reshuffleステップを追加する(Apache Beamのドキュメントでは非推奨扱いですが、Dataflowでは引き続きサポートされています)。Reshuffleにより、データはワーカー間で再分配されます。
FlexRSによるプリエンプティブワーカー
バッチジョブのコストを下げたい場合は、FlexRS機能の利用が選択肢になります。ただし、日次・月次バッチのように時間制約のゆるいワークロード向けです。FlexRSは通常のVMインスタンスとプリエンプティブVMインスタンスを組み合わせて稼働し、プリエンプティブマシンが停止した際の処理ロスを最小化します。FlexRSが使えるのはDataflow Shuffleサービス利用時に限られます。
FlexRSを有効化する際は、コスト最適化と速度最適化のいずれかを選べます。
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
FlexRSはオートスケーリング時に安価なインスタンスを選ぶ仕組みを前提としているため、利用中はオートスケーリングアルゴリズムをNONEに設定できない点に注意してください。
BigQuery Write Storage API
2021年、Googleはバッチおよびストリーミングワークロード向けに新しいBigQuery APIを公開しました。この新しいエンドポイントは、同一ストリーム内で追加されるデータの冪等性を保証します。さらに、デフォルトのスループットクォータはレガシーAPIの3倍に拡張されています。
もっとも見逃せないのは、新APIのコストがGBあたりレガシーAPI比で50%安いという点です。BigQueryへ大量データをストリーミングするパイプラインなら、コスト削減効果は絶大です。具体的な金額は料金ページをご確認ください。
残念ながら、執筆時点(2023年1月)では、新しいWrite Storage APIに対応しているのはJava SDKのみです。
JavaでStorage Write APIを使うのに必要な変更はわずかです。次のように、.withMethod()のパラメータとしてMethod.STORAGE_WRITE_APIを渡すだけです。
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
実装の詳細はBigQueryIOのドキュメントを参照してください。
Dataflowのコスト最適化は実にさまざまな要素が絡みます。本記事で挙げた打ち手の多くは、パフォーマンスや処理速度とコストとのトレードオフを天秤にかける判断が必要になります。
最新のBigQuery APIの活用も、大きなコスト削減につながります。コードレベルの最適化は、DataflowやApache Beamのベストプラクティスに沿って進めましょう。代表的なパイプラインパターンもぜひ参考にしてください。私のお気に入りはBigQuery dead-letterパターンです。Streaming Engineをより深く知りたい方には、こちらの記事がおすすめです。