Quem roda pipelines de dados no Google Cloud Platform (GCP) provavelmente usa o Dataflow. O Dataflow é um runner para workloads do Apache Beam. Depois que você coloca um pipeline em produção, é hora de torná-lo mais eficiente em custo. Encontrar a configuração ideal para seus pipelines não é simples, já que existem inúmeras opções e parâmetros — e neste post eu vou te ajudar nessa missão.

Use o Streaming Engine
Uma das formas mais simples de reduzir custos é habilitar o Streaming Engine. Sem ele, o Autoscaler usa o disco persistente como referência para definir o número de workers. Discos nunca são removidos de um job em execução. Cada worker precisa ter pelo menos um disco persistente, e a quantidade de discos anexados precisa ser igual entre os workers. Por isso, o Dataflow só consegue reduzir o número de workers em até 50%, para garantir uma distribuição uniforme dos discos. Quando o Streaming Engine está ativo, boa parte do trabalho — como as etapas de shuffle e groupByKey — é delegada ao serviço do Streaming Engine, e o autoscaling do Dataflow deixa de depender dos discos anexados. Por isso, dá até para reduzir o tamanho do disco para 30 GB.
O Streaming Engine suporta pipelines em Java (SDK => 2.11.0) e Python (SDK => 2.21.0).
Java: - enableStreamingEngine
Python: habilitado por padrão.
Go: ainda não suportado.
O número máximo de workers
O Horizontal Autoscaling, antes chamado apenas de Autoscaling, escolhe automaticamente quantos workers o job precisa. O padrão é de no máximo 1.000 workers para jobs em batch e 100 para jobs de streaming.
Limitar esse máximo ajuda a reduzir custos. Mas, se você processa um grande volume de dados com apenas um worker, pode levar uma eternidade até concluir. Com base nos requisitos do negócio e na variabilidade dos seus dados, dá para escolher a quantidade certa de workers. Pela minha experiência, sugiro definir dez workers a mais do que o job precisa em 80% do tempo. Assim, você tem uma folga no pool para absorver os picos. Quando os picos forem maiores e o backlog do Dataflow não diminuir rápido o suficiente, é hora de aumentar o número de workers.
Se você não usa o Streaming Engine, lembre-se de que será provisionado um pool fixo de discos persistentes equivalente ao número máximo de workers. Defina esse limite com as seguintes flags:
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
Paralelização
O Dataflow é um serviço gerenciado do Google voltado para o processamento distribuído de dados em larga escala. O principal custo do Dataflow são os recursos de computação — então precisamos usá-los da forma mais eficiente possível. Vários parâmetros do pipeline permitem afinar a paralelização nos recursos certos. O Dataflow é projetado para processar volumes enormes de dados, e muito disso acontece em paralelo. Com ele, você pode melhorar a paralelização de duas formas: adicionando mais workers ou definindo mais threads por worker. Neste post, vou tratar paralelização como threads por worker.
Paralelizar dentro de um único worker ajuda a reduzir custos, porque o mesmo worker passa a processar mais elementos. E, quando cada worker processa mais elementos, o Dataflow precisa de menos workers no total para o job.
Tipo de máquina e threads concorrentes
A maior parte do custo do Dataflow vai para recursos de computação. Por isso, escolher os tipos de máquina certos para o job faz toda a diferença. O Google Cloud Platform oferece uma grande variedade de tipos de máquina.
Para workloads que exigem muita memória, escolher a N1 sai um pouco mais barato do que a N2, mais nova.
Já quando os jobs usam muita CPU, a série N2, mais nova e mais usada, é a melhor escolha. Na série N2 há três opções: N2-standard, N2 high-mem e N2 high-CPU. A standard oferece 4 GB de memória por vCPU. A high-mem oferece 8 GB por vCPU e, por fim, a high-CPU oferece 1 GB por vCPU. Os preços estão aqui.
O Dataflow consegue executar seus workloads em paralelo. No modo Streaming, ele executa um DoFn por thread. Vale destacar que a paralelização no SDK de Python funciona de forma diferente da dos SDKs de Java e Go. O Python roda um processo e, por padrão, 12 threads por vCPU; já Go e Java rodam um processo e 300 threads por VM. O número padrão de threads no SDK de Python depende da quantidade de vCPUs do tipo de máquina escolhido. Por exemplo: ao escolher a n2-standard-2, você tem 2 vCPUs e (2x12) 24 threads. Já com a n2-standard-8, são 8 vCPUs e (8x12) 96 threads por padrão.
O Dataflow permite configurar o número de threads por vCPU ou VM, dependendo do SDK. Elas se chamam Worker harness threads.
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
Conforme a sua necessidade e o workload, você pode ajustar o nível de paralelismo. Como várias threads compartilham o mesmo espaço de memória, reduza o número de threads para jobs que consomem muita memória. Quando o workload não é tão pesado, dá para aumentar as threads e fazer mais coisas em paralelo. Quanto maior o paralelismo, mais elementos um único worker consegue processar. Mas, se você tentar paralelizar demais, podem aparecer diversos problemas — o mais comum é Out Of Memory, e o Dataflow vai tentar reprocessar esse trabalho. E lembre-se: se o pipeline chamar recursos de terceiros, como APIs, garanta que eles aguentem o volume de chamadas.
Otimização por fusão (Fusion optimization)
Quando você submete o código ao runner do Dataflow, o primeiro passo após a compilação é criar um grafo de execução com base nesse código. Dá para visualizar esse grafo no Google Cloud Console. Para mais informações, veja este link. Depois que o grafo é criado e validado pelo runner, o serviço pode modificá-lo para aplicar otimizações. Uma delas é combinar (fundir) etapas separadas em operações maiores, para que o serviço não precise materializar os dados entre cada passo. Isso deixa o processamento mais rápido, já que os dados são tratados por várias operações em memória — mas também força a execução de todas as etapas combinadas na mesma máquina onde começaram. Embora a Fusion optimization seja uma parte importante do poder do Dataflow, ela também pode criar gargalos no pipeline. Como ela se baseia no grafo gerado pelo código antes que os dados comecem a fluir, o Dataflow não consegue detectar os casos a seguir, que limitam a paralelização.
Figura 1: grafo de execução otimizado para o exemplo Wordcount, este exemplo de WordCount em Java example
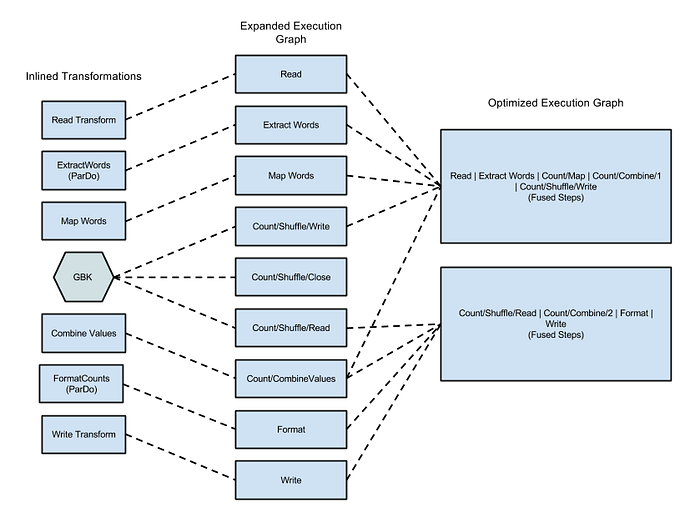
a documentação do Dataflow mostra como fica o grafo ao executar o exemplo com o runner do Dataflow.
High Fanout
Quando um dos seus ParDos gera muito mais elementos na saída do que recebeu na entrada, vale considerar um reshuffle dos dados. Um exemplo é processar um arquivo na entrada e ter linhas individuais na saída. Depois desse ParDo, o Dataflow tem muito mais itens para processar no mesmo worker do que o esperado. Isso porque o Dataflow usa a quantidade prevista de itens de entrada para definir quantas instâncias a etapa fundida precisa. Ao quebrar a fusão, o Dataflow consegue rebalancear o workload e processar mais itens em paralelo.
Dados mal distribuídos entre as máquinas
Se o seu job consome arquivos como entrada e esses arquivos têm tamanhos variados, é bem provável que o volume de dados que passa pelo pipeline esteja desbalanceado. Alguns workers vão ter muito mais a processar do que outros. Sem um reshuffle, algumas máquinas ficam ociosas enquanto outras rodam a todo vapor.
Você pode [quebrar a fusão](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion) de três formas:
- GroupByKey (o Dataflow nunca funde etapas de agregação). O Dataflow nunca funde etapas de agregação.
- Adicionar a PCollection intermediária como side input. Um side input é sempre materializado, então não faz sentido fundir essas etapas.
- Adicionar uma etapa de reshuffle (o Reshuffle é suportado pelo Dataflow, mesmo estando marcado como deprecated na documentação do Apache Beam). Com o Reshuffle, os dados são redistribuídos entre os workers.
Workers preemptíveis com FlexRS
Para reduzir custos em jobs em batch, você pode começar a usar o recurso FlexRS — embora ele só seja indicado para workloads sem urgência de tempo, como tarefas diárias ou mensais. O FlexRS combina instâncias de VM regulares com instâncias preemptíveis. O Dataflow FlexRS tenta evitar perda de processamento quando as máquinas preemptíveis param de funcionar. Você só pode usar o FlexRS junto do serviço Dataflow Shuffle.
Ao habilitar o FlexRS, dá para escolher entre otimizar por custo ou por velocidade.
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
Vale lembrar: como o FlexRS depende de uma seleção de instâncias mais baratas durante o autoscaling, você não pode definir o algoritmo de autoscaling como NONE quando estiver usando o recurso.
BigQuery write storage API
Em 2021, o Google lançou uma nova BigQuery API para workloads em batch e streaming. Esse novo endpoint garante que os dados adicionados sejam idempotentes dentro do mesmo stream. A cota padrão de throughput da nova write API é três vezes maior que a da API legada.
Mais importante: o custo da nova API é 50% menor por GB em comparação com a legada. Se o seu pipeline transmite muitos dados para o BigQuery, isso pode representar uma economia enorme. Para os números exatos, consulte a página de preços.
Infelizmente, no momento em que escrevo (janeiro de 2023), apenas o SDK de Java suporta a nova write storage API.
Em Java, basta uma pequena alteração no código para usar a Storage Write API. Adicione o método . STORAGE_WRITE_API como parâmetro de .withMethod(), conforme abaixo.
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
Mais informações sobre a implementação estão na documentação do BigQueryIO.
A otimização de custos no Dataflow depende de vários fatores. Na maior parte das recomendações, é preciso equilibrar performance/velocidade e custo.
Aproveitar a nova BigQuery API também gera uma economia considerável. Outras otimizações podem ser feitas direto no código, seguindo as boas práticas do Dataflow/Apache Beam. Você também pode aproveitar os padrões comuns de pipeline. Meu favorito é o padrão dead-letter para BigQuery. E este é um ótimo post para se aprofundar no Streaming engine.