Wer Datenpipelines in der Google Cloud Platform (GCP) betreibt, nutzt vermutlich Dataflow. Dataflow ist ein Runner für Apache-Beam-Workloads. Sobald eine funktionierende Datenpipeline in Produktion geht, lohnt sich der nächste Schritt: sie kosteneffizienter machen. Die optimalen Einstellungen zu finden, ist allerdings knifflig – schlicht, weil es so viele Optionen und Parameter gibt. In diesem Blogpost zeige ich Ihnen, worauf es ankommt.

Streaming Engine nutzen
Eine der einfachsten Maßnahmen zur Kostensenkung ist das Aktivieren der Streaming Engine. Ohne sie zieht der Autoscaler die Persistent Disks als Indikator für die Anzahl der Worker heran. Disks werden niemals aus einem laufenden Job entfernt. Jeder Worker braucht mindestens eine Persistent Disk, und die Anzahl der angehängten Disks muss bei allen Workern identisch sein. Dataflow kann die Worker-Zahl deshalb nur um 50 % reduzieren, um eine gleichmäßige Verteilung der Disks sicherzustellen. Mit aktivierter Streaming Engine wandern viele Aufgaben wie Shuffle- und groupByKey-Schritte an den Streaming-Engine-Service, und das Dataflow-Autoscaling hängt nicht länger an den angehängten Disks. Aus diesem Grund können Sie die Disk-Größe auch auf 30 GB reduzieren.
Die Streaming Engine unterstützt Java- (SDK => 2.11.0) und Python-Pipelines (SDK => 2.21.0).
Java: - enableStreamingEngine
Python: standardmäßig aktiviert.
Go: Noch nicht unterstützt.
Maximale Anzahl an Workern
Das Horizontal Autoscaling – früher schlicht Autoscaling genannt – wählt automatisch die für den Job nötige Worker-Anzahl. Die Standardobergrenze liegt bei 1.000 Workern für Batch-Jobs und 100 für Streaming-Jobs.
Wer die maximale Worker-Anzahl begrenzt, spart Kosten. Verarbeiten Sie jedoch ein großes Datenvolumen mit nur einem einzigen Worker, kann das eine Ewigkeit dauern. Je nach geschäftlichen Anforderungen und Spitzenlast Ihrer Daten lässt sich die richtige Worker-Anzahl bestimmen. Aus meiner Erfahrung empfehle ich, zehn Worker mehr einzuplanen, als der Job in 80 % der Zeit benötigt. So haben Sie einen Puffer, um Spitzen abzufangen. Sind die Spitzen größer und der Backlog in Dataflow baut sich nicht schnell genug ab, müssen Sie weitere Worker bereitstellen.
Wenn Sie die Streaming Engine nicht nutzen, denken Sie daran: Sie stellen einen festen Pool an Persistent Disks in Höhe der maximalen Worker-Anzahl bereit. Die maximale Worker-Anzahl legen Sie über folgende Flags fest:
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
Parallelisierung
Dataflow ist ein von Google entwickelter Managed Service für die verteilte Datenverarbeitung in großem Maßstab. Den größten Kostenblock bei Dataflow bilden die benötigten Compute-Ressourcen – diese gilt es so effizient wie möglich zu nutzen. Mehrere Pipeline-Parameter erlauben es, die Parallelisierung gezielt feinzujustieren. Dataflow ist darauf ausgelegt, riesige Datenmengen zu verarbeiten, wobei vieles parallel läuft. Die Parallelisierung lässt sich auf zwei Arten steigern: durch mehr Worker oder durch mehr Threads pro Worker. In diesem Blogpost meint Parallelisierung die Threads pro Worker.
Parallelisierung innerhalb eines einzelnen Workers senkt die Kosten, weil derselbe Worker mehr Elemente verarbeitet. Schafft ein Worker mehr Elemente, braucht Dataflow insgesamt weniger Worker für Ihren Job.
Maschinentyp und parallele Threads
Der größte Teil der Dataflow-Kosten entfällt auf Compute-Ressourcen. Daher ist die Wahl der passenden Maschinentypen entscheidend. Die Google Cloud Platform bietet eine breite Palette an Maschinentypen.
Für speicherintensive Workloads ist N1 etwas günstiger als die neuere N2-Reihe.
Bei CPU-lastigen Jobs ist hingegen die häufiger genutzte, neuere N2-Serie die bessere Wahl. In der N2-Serie stehen drei Varianten zur Auswahl: N2-standard, N2 high-mem und N2 high-CPU. Der Standard-Maschinentyp bietet 4 GB Arbeitsspeicher pro vCPU. High-mem stellt 8 GB pro vCPU bereit, und nicht zuletzt liefert high-CPU 1 GB pro vCPU. Die Preise finden Sie hier.
Dataflow kann Ihre Workloads parallel ausführen. Im Streaming-Modus führt Dataflow eine DoFn pro Thread aus. Wichtig zu wissen: Die Parallelisierung im Python-SDK funktioniert anders als im Java- und Go-SDK. Python startet einen Prozess mit standardmäßig 12 Threads pro vCPU, während Go und Java einen Prozess mit 300 Threads pro VM ausführen. Die Anzahl der Standard-Threads im Python-SDK hängt von der vCPU-Anzahl des gewählten Maschinentyps ab. Bei einer n2-standard-2 haben Sie also 2 vCPUs und (2x12) 24 Threads. Bei einer n2-standard-8 sind es 8 vCPUs und standardmäßig (8x12) 96 Threads.
Dataflow erlaubt es Ihnen, die Anzahl der Threads pro vCPU oder VM – je nach SDK – zu konfigurieren. Diese werden als Worker-Harness-Threads bezeichnet.
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
Je nach Anforderung und Workload können Sie den Grad der Parallelität anpassen. Da sich mehrere Threads denselben Speicherbereich teilen, sollten Sie die Thread-Zahl bei speicherintensiven Jobs reduzieren. Ist Ihr Workload weniger anspruchsvoll, lässt sich die Thread-Zahl erhöhen, sodass mehr Arbeit parallel läuft. Je höher die Parallelität, desto mehr Elemente kann ein einzelner Worker verarbeiten. Wer zu viel parallel laufen lässt, riskiert Probleme – am häufigsten Out-of-Memory-Fehler, woraufhin Dataflow den Vorgang erneut versucht. Und denken Sie daran: Wenn Sie Drittanbieter-Ressourcen wie APIs aufrufen, müssen diese das Anfragevolumen ebenfalls bewältigen können.
Fusion-Optimierung
Wenn Sie Ihren Code an den Dataflow-Runner übergeben, erstellt Dataflow nach dem Kompilieren als Erstes einen Ausführungsgraphen auf Basis Ihres Codes. Diesen Graphen können Sie in der Google Cloud Console einsehen. Mehr Informationen finden Sie unter diesem Link. Nachdem der Graph erstellt und vom Dataflow-Runner validiert wurde, kann der Dataflow-Service ihn zur Optimierung anpassen. Eine dieser Optimierungen besteht darin, separate Schritte zu größeren Operationen zusammenzufassen (Fusion), sodass die Daten zwischen den einzelnen Schritten nicht materialisiert werden müssen. Das beschleunigt die Verarbeitung, weil Daten mit mehreren Operationen im Speicher verarbeitet werden – erzwingt aber zugleich die Ausführung aller zusammengeführten Schritte auf der Maschine, auf der sie begonnen haben. So sehr Fusion-Optimierung eine zentrale Stärke von Dataflow ist, kann sie auch Engpässe in Ihrer Pipeline erzeugen. Da die Fusion-Optimierung auf dem aus dem Code abgeleiteten Graphen basiert, bevor Daten durch die Pipeline fließen, kann Dataflow die folgenden Fälle, die die Parallelisierung einschränken, nicht erkennen.
Abbildung 1: Optimierter Ausführungsgraph für das Wordcount-Beispiel, dieses Java-WordCount-Beispiel
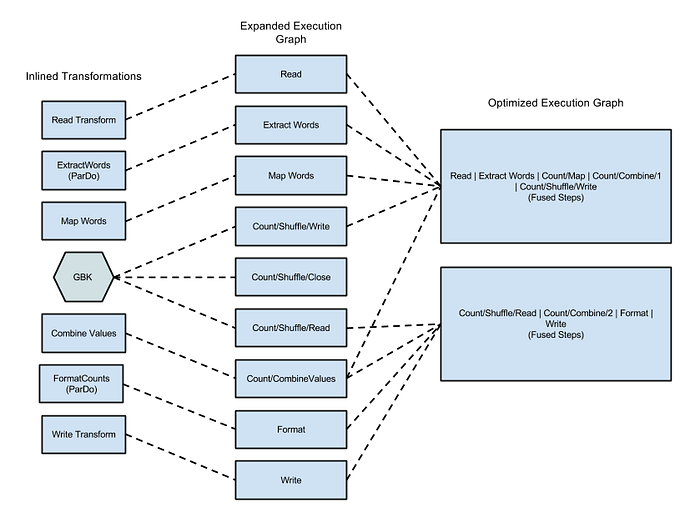
Die Dataflow-Dokumentation zeigt, wie der Graph aussieht, wenn Sie das Beispiel mit dem Dataflow-Runner ausführen.
High Fanout
Wenn eine Ihrer ParDos deutlich mehr Elemente ausgibt, als sie als Input erhalten hat, sollten Sie ein Reshuffle Ihrer Daten in Betracht ziehen. Ein Beispiel: Sie verarbeiten eine Datei als Input, und der Output sind einzelne Zeilen. Nach dieser ParDo hat Dataflow auf demselben Worker viel mehr zu verarbeitende Elemente als erwartet. Dataflow nutzt nämlich die erwartete Input-Menge, um zu bestimmen, wie viele Instanzen der Fusion-Schritt benötigt. Bricht man die Fusion auf, kann Dataflow die Last neu verteilen und mehr Elemente parallel verarbeiten.
Daten ungleich auf Maschinen verteilt
Wenn Ihr Job Dateien als Input verarbeitet und diese Dateien unterschiedlich groß sind, ist das Datenvolumen in Ihrer Pipeline mit hoher Wahrscheinlichkeit unausgeglichen. Manche Worker haben deutlich mehr zu tun als andere. Ohne Reshuffle der Daten bleiben einige Maschinen untätig, während andere unter Volllast laufen.
So lässt sich [die Fusion aufbrechen](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion) – auf drei Wegen:
- GroupByKey (Dataflow fusioniert Aggregationsschritte grundsätzlich nicht). Aggregationsschritte werden von Dataflow niemals zusammengeführt.
- Fügen Sie Ihre Zwischen-PCollection als Side Input hinzu. Ein Side Input wird ohnehin immer materialisiert – ein Fusionieren dieser Schritte ergibt deshalb keinen Sinn.
- Fügen Sie einen Reshuffle-Schritt ein (Reshuffle wird von Dataflow weiterhin unterstützt, auch wenn es in der Apache-Beam-Dokumentation als deprecated markiert ist). Mit Reshuffle werden die Daten neu auf die verschiedenen Worker verteilt.
Preemptible Worker mit FlexRS
Um Kosten für Batch-Jobs zu senken, können Sie das FlexRS-Feature einsetzen – allerdings nur für nicht zeitkritische Workloads wie tägliche oder monatliche Jobs. FlexRS kombiniert reguläre VM-Instanzen mit Preemptible-VM-Instanzen. Dataflow FlexRS versucht, Prozessverluste zu vermeiden, wenn Preemptible-Maschinen ausfallen. FlexRS lässt sich nur in Verbindung mit dem Dataflow-Shuffle-Service nutzen.
Beim Aktivieren von FlexRS können Sie zwischen Kosten- und Geschwindigkeitsoptimierung wählen.
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
Beachten Sie: Da FlexRS beim Auto-Scaling auf eine Auswahl günstiger Instanzen setzt, lässt sich der Auto-Scaling-Algorithmus bei FlexRS-Nutzung nicht auf NONE setzen.
BigQuery Write Storage API
2021 hat Google eine neue BigQuery-API für Batch- und Streaming-Workloads veröffentlicht. Dieser neue Endpoint stellt sicher, dass die hinzugefügten Daten innerhalb desselben Streams idempotent sind. Die Standard-Durchsatzquote der neuen Write-API liegt dreimal höher als bei der Legacy-API.
Am wichtigsten: Die Kosten der neuen API sind pro GB 50 % niedriger als bei der Legacy-API. Wenn Ihre Pipeline große Datenmengen nach BigQuery streamt, ist das ein enormer Kostenhebel. Genaue Zahlen finden Sie auf der Preisübersicht.
Leider unterstützt zum Zeitpunkt der Veröffentlichung (Januar 2023) nur das Java-SDK die neue Write Storage API.
In Java reicht eine kleine Code-Änderung, um die Storage Write API zu nutzen. Übergeben Sie Method.STORAGE_WRITE_API als Parameter an .withMethod() – wie folgt:
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
Weitere Informationen zur Implementierung finden Sie in der BigQueryIO-Dokumentation.
Die Kostenoptimierung von Dataflow hängt von vielen Faktoren ab. Bei den meisten Empfehlungen gilt es, zwischen Performance/Geschwindigkeit und Kosten abzuwägen.
Auch der Einsatz der neuesten BigQuery-API spart erheblich Kosten. Weitere Optimierungen lassen sich im Code vornehmen, indem Sie die Best Practices von Dataflow/Apache Beam befolgen. Greifen Sie auf gängige Pipeline-Patterns zurück. Mein persönlicher Favorit ist das BigQuery-Dead-Letter-Pattern. Lesenswert ist auch dieser Beitrag, um mehr über die Streaming Engine zu erfahren.