Si ejecutas data pipelines en Google Cloud Platform (GCP), lo más probable es que uses Dataflow. Dataflow es un runner para workloads de Apache Beam. Cuando llevas un data pipeline funcional a producción, llega el momento de hacerlo más eficiente en costos. Dar con la configuración óptima para tus pipelines no es sencillo, ya que hay muchísimas opciones y parámetros en juego. En este blog post te ayudaré a lograrlo.

Aprovecha el Streaming Engine
Una de las formas más simples de reducir costos es habilitar el Streaming Engine. Si no lo usas, el Autoscaler toma el persistence disk como referencia para definir la cantidad de workers. Los discos nunca se eliminan de un job en ejecución. Cada worker debe tener al menos un persistent disk, y la cantidad de discos asociados debe ser la misma entre los distintos workers. Por eso, Dataflow solo puede reducir el número de workers en un 50% para mantener una distribución pareja de los discos. Cuando el Streaming Engine está habilitado, gran parte del trabajo (como los pasos de shuffle y groupByKey) se delega al servicio del Streaming Engine, y el autoescalado de Dataflow ya no depende de los discos asociados. Por eso, también puedes reducir el tamaño del disco a 30GB.
El Streaming Engine soporta pipelines en Java (SDK => 2.11.0) y Python (SDK => 2.21.0).
Java: - enableStreamingEngine
Python: habilitado por defecto.
Go: aún no soportado.
La cantidad máxima de workers
El Horizontal Autoscaling (antes llamado Autoscaling) selecciona automáticamente la cantidad de workers que necesita el job. Por defecto, el máximo es de 1000 workers para batch jobs y 100 para streaming jobs.
Limitar la cantidad máxima de workers permite reducir costos. Pero si procesas un volumen grande de datos con un solo worker, puede tardar muchísimo en completarse. Según tus requerimientos de negocio y los picos en tus datos, puedes elegir la cantidad adecuada de workers. Por mi experiencia, recomiendo seleccionar diez workers más de los que tu job necesita el 80% del tiempo. Así tendrás un buffer en tu pool de workers para absorber los picos. Si los picos son más grandes y el backlog en Dataflow no se reduce con la rapidez suficiente, tendrás que sumar más workers.
Si no usas el Streaming Engine, ten en cuenta que se despliega un pool fijo de persistent disks igual al número máximo de workers. Puedes definir la cantidad máxima de workers con los siguientes flags:
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
Paralelización
Dataflow es un servicio gestionado desarrollado por Google que se utiliza para el procesamiento distribuido de datos a gran escala. El costo principal de Dataflow son los recursos de cómputo, así que conviene aprovecharlos al máximo. Hay varios parámetros del pipeline que permiten ajustar la paralelización sobre los recursos correctos. Dataflow está diseñado para procesar volúmenes enormes de datos, y gran parte del trabajo se ejecuta en paralelo. Con Dataflow puedes mejorar la paralelización de 2 maneras: agregando más workers o definiendo más threads por worker. En este blog post nos referiremos a la paralelización como threads por worker.
La paralelización dentro de un mismo worker te ayuda a reducir costos porque ese worker puede procesar más elementos. Y cuando un solo worker procesa más elementos, Dataflow necesita menos workers para tu job.
Tipo de máquina y threads concurrentes
La mayor parte del costo de Dataflow se va en recursos de cómputo. Por eso es clave seleccionar tipos de máquina adecuados para el job. Google Cloud Platform ofrece una amplia variedad de tipos de máquina.
Para workloads intensivos en memoria, elegir N1 sale un poco más barato que la más nueva N2.
Pero cuando tus jobs consumen mucha CPU, la serie N2 (más reciente y más usada) es la mejor opción. Dentro de la serie N2 hay tres tipos disponibles: N2-standard, N2 high-mem y N2 high-CPU. El tipo standard te da 4GB de memoria por vCPU. La high-mem te ofrece 8GB de memoria por vCPU y, por último, la high-CPU te entrega 1GB de memoria por vCPU. Los precios pueden consultarse aquí.
Dataflow puede ejecutar tu workload en paralelo. Cuando corre en modo Streaming, ejecuta una DoFn por thread. Es importante saber que la paralelización en el SDK de Python funciona distinto a la de Java y Go. Python ejecuta un proceso y, por defecto, 12 threads por vCPU, mientras que Go y Java ejecutan un proceso y 300 threads por VM. La cantidad de threads por defecto en el SDK de Python depende de la cantidad de vCPUs del tipo de máquina elegido. Por ejemplo, al elegir n2-standard-2 tienes 2 vCPUs y (2x12) 24 threads. Al seleccionar n2-standard-8 tienes 8 vCPUs y (8x12) 96 threads por defecto.
Dataflow te permite configurar la cantidad de threads por vCPU o VM según el SDK. Estos se llaman Worker harness threads.
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
Según tus necesidades y tu workload, puedes ajustar el nivel de paralelismo. Como múltiples threads se ejecutan en el mismo espacio de memoria, conviene bajar la cantidad de threads para jobs intensivos en memoria. Cuando tu workload no es tan exigente, puedes subir la cantidad de threads para procesar más trabajo en paralelo. A mayor paralelismo, más elementos puede manejar un solo worker. Si intentas hacer demasiado en paralelo, pueden aparecer varios problemas; el más común es Out Of Memory, y Dataflow reintentará ese trabajo. Y ten presente que si llamas a recursos de terceros como APIs, deben poder soportar el volumen de llamadas.
Optimización por fusión
Cuando envías tu código al runner de Dataflow, lo primero que hace después de compilarlo es crear un grafo de ejecución basado en tu código. Puedes ver ese grafo en la Google Cloud Console. Para más información, sigue este enlace. Una vez que el runner de Dataflow crea y valida el grafo, el servicio puede modificarlo para aplicar optimizaciones. Una de ellas consiste en combinar (fusionar) pasos separados en operaciones más grandes para que el servicio no tenga que materializar los datos entre cada paso. Esto agiliza el procesamiento, ya que los datos se procesan con varias operaciones en memoria, pero también obliga a ejecutar todos los pasos combinados en la máquina donde inició el proceso. Si bien la optimización por fusión es una pieza clave del poder de Dataflow, también puede generar cuellos de botella en tu pipeline. Como esta optimización se basa en el grafo creado a partir del código antes de que los datos fluyan por el pipeline, Dataflow no logra detectar los siguientes casos de uso que limitan la paralelización.
Figura 1: Grafo de ejecución optimizado para el ejemplo Wordcount, este ejemplo de Java WordCount
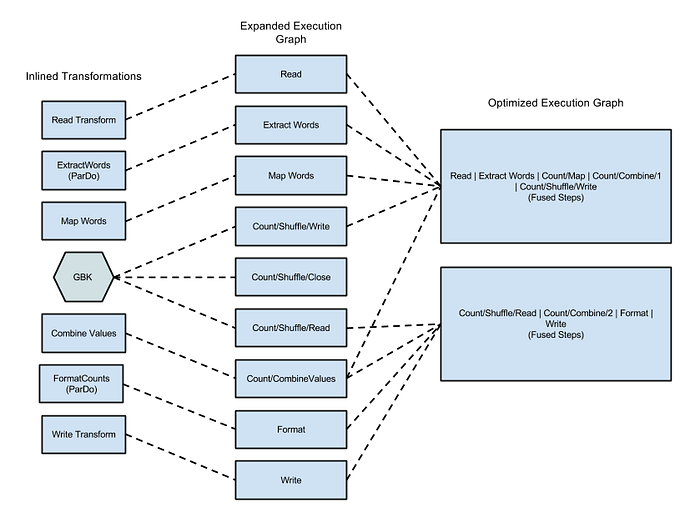
la documentación de Dataflow muestra cómo queda el grafo cuando ejecutas el ejemplo con el runner de Dataflow.
High Fanout
Cuando una de tus ParDos genera muchos más elementos en la salida que los que recibió en la entrada, conviene considerar un reshuffle de los datos. Un ejemplo: cuando procesas un archivo como entrada y la salida son líneas individuales. Después de esa ParDo, Dataflow tiene muchos más elementos para procesar en el mismo worker de los que esperaba. Dataflow usa el número esperado de elementos de entrada para determinar cuántas instancias necesita el paso de fusión. Al romper la fusión, Dataflow puede rebalancear el workload y procesar más elementos en paralelo.
Datos mal balanceados entre máquinas
Si tienes un job que consume archivos como entrada y esos archivos varían en tamaño, es muy probable que el volumen de datos que pasa por tu pipeline esté desbalanceado. Algunos workers tendrán mucho más para procesar que otros. Si no haces reshuffle de tus datos, algunas máquinas estarán inactivas mientras otras corren a plena capacidad.
Puedes [romper la fusión](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion) de tres maneras:
- GroupByKey (Dataflow nunca fusiona pasos de agregación). Dataflow nunca fusiona pasos de agregación.
- Agregar tu PCollection intermedia como side input. Un side input siempre se materializa, por eso no tiene sentido fusionar esos pasos.
- Agregar un paso de reshuffle (Dataflow soporta Reshuffle aunque esté marcado como deprecated en la documentación de Apache Beam). Con Reshuffle los datos se redistribuyen entre los distintos workers.
Workers preemptibles con FlexRS
Para reducir costos en batch jobs, puedes empezar a usar la funcionalidad FlexRS, aunque solo conviene para workloads que no son críticos en tiempo, como tareas diarias o mensuales. FlexRS combina instancias de VM regulares con instancias de VM preemptibles. Dataflow FlexRS busca evitar la pérdida del proceso cuando las máquinas preemptibles dejan de funcionar. Solo puedes usar FlexRS junto con el servicio Dataflow Shuffle.
Cuando quieras habilitar FlexRS, puedes elegir entre optimización por costo o por velocidad.
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
Ten en cuenta que como FlexRS se basa en la elección de instancias económicas al hacer autoescalado, no puedes establecer el algoritmo de autoescalado en NONE cuando uses FlexRS.
BigQuery write storage API
En 2021, Google lanzó una nueva BigQuery API para workloads de batch y streaming. Este nuevo endpoint garantiza que los datos agregados sean idempotentes en el mismo stream. La cuota de throughput por defecto de la nueva write API es tres veces más alta que la API legacy.
Lo más importante es que el costo de la nueva API es 50% menor por GB en comparación con la API legacy. Si tu pipeline transmite mucha información a BigQuery, esto puede representar un ahorro enorme. Para los números exactos, consulta la página de precios.
Lamentablemente, al momento de escribir esto (enero de 2023), solo el SDK de Java soporta la nueva write storage API.
Solo necesitas un pequeño cambio en el código Java para usar la Storage Write API. Agrega Method . STORAGE_WRITE_API como parámetro a .withMethod() de la siguiente forma.
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
Encontrarás más información sobre la implementación en la documentación de BigQueryIO.
La optimización de costos en Dataflow depende de muchos factores. En la mayoría de las recomendaciones tendrás que encontrar un equilibrio entre rendimiento/velocidad y costo.
Aprovechar la nueva BigQuery API también te permite ahorrar bastante. Otras optimizaciones se pueden aplicar en el código siguiendo las mejores prácticas de Dataflow/ Apache Beam. Puedes apoyarte en patrones comunes de pipeline. Mi favorito es el patrón dead-letter de BigQuery. Y este es un excelente artículo para conocer más sobre el Streaming engine.