Si vous exécutez des pipelines de données sur Google Cloud Platform (GCP), vous utilisez sans doute Dataflow, le runner des workloads Apache Beam. Une fois votre pipeline passé en production, l'étape suivante consiste à le rendre plus économique. Trouver les bons réglages relève toutefois du casse-tête tant les options et paramètres sont nombreux : cet article est là pour vous y aider.

Tirer parti du Streaming Engine
Activer le Streaming Engine reste l'un des moyens les plus simples de faire baisser la facture. Sans lui, l'Autoscaler s'appuie sur le disque persistant comme indicateur du nombre de workers. Or les disques ne sont jamais retirés d'un job en cours d'exécution. Chaque worker doit disposer d'au moins un disque persistant, et le nombre de disques attachés doit être identique d'un worker à l'autre. Dataflow ne peut donc réduire le nombre de workers que de 50 % afin de garantir une répartition équivalente des disques. Une fois le Streaming Engine activé, une grande partie du travail – notamment les étapes shuffle et groupByKey – est déléguée au service Streaming Engine, et l'autoscaling de Dataflow ne dépend plus des disques attachés. Vous pouvez d'ailleurs ramener la taille des disques à 30 Go.
Le Streaming Engine prend en charge les pipelines Java (SDK => 2.11.0) et Python (SDK => 2.21.0).
Java: - enableStreamingEngine
Python: enabled by default.
Go: Not supported yet.
Le nombre maximal de workers
L'Horizontal Autoscaling, anciennement Autoscaling, sélectionne automatiquement le nombre de workers nécessaires au job. Par défaut, ce maximum est fixé à 1000 pour les jobs batch et à 100 pour les jobs streaming.
Plafonner ce nombre permet de réduire les coûts, mais traiter un volume important de données avec un seul worker peut prendre un temps considérable. À vous de doser le bon nombre de workers en fonction de vos besoins métier et de la variabilité de vos données. D'expérience, je recommande de prévoir dix workers de plus que ce dont votre job a besoin 80 % du temps. Vous gardez ainsi une marge dans votre pool pour absorber les pics. Si ces pics sont plus prononcés et que le backlog Dataflow ne se résorbe pas assez vite, il faudra revoir ce plafond à la hausse.
Si vous n'utilisez pas le Streaming Engine, gardez à l'esprit qu'un pool fixe de disques persistants équivalent au nombre maximal de workers est déployé. Le maximum se définit avec les flags suivants :
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
Parallélisation
Dataflow est un service managé développé par Google pour le traitement distribué de données à grande échelle. L'essentiel du coût provient des ressources de calcul : autant les exploiter le plus efficacement possible. Plusieurs paramètres de pipeline permettent d'affiner la parallélisation sur les bonnes ressources. Conçu pour traiter des volumes massifs, Dataflow effectue une grande partie du travail en parallèle. Vous disposez de deux leviers pour améliorer la parallélisation : ajouter des workers ou définir davantage de threads par worker. Dans cet article, le terme parallélisation désigne les threads par worker.
Paralléliser au sein d'un même worker permet de réduire les coûts, puisque ce worker traite alors plus d'éléments. Et plus chaque worker en traite, moins Dataflow en a besoin pour exécuter votre job.
Type de machine et threads concurrents
L'essentiel du coût Dataflow étant lié aux ressources de calcul, le choix du type de machine est déterminant. Google Cloud Platform en propose une grande variété.
Pour les workloads gourmands en mémoire, le N1 reste légèrement moins cher que le N2, plus récent.
En revanche, dès que vos jobs consomment beaucoup de CPU, la série N2, plus récente et plus répandue, s'impose. Elle se décline en trois variantes : N2-standard, N2 high-mem et N2 high-CPU. Le standard offre 4 Go de mémoire par vCPU, le high-mem 8 Go par vCPU et le high-CPU 1 Go par vCPU. La tarification est disponible ici.
Dataflow peut exécuter votre workload en parallèle. En mode Streaming, il lance un DoFn par thread. Important : la parallélisation diffère selon les SDK. Python lance un processus avec, par défaut, 12 threads par vCPU, tandis que Go et Java lancent un processus avec 300 threads par VM. Le nombre de threads par défaut côté Python dépend du nombre de vCPU du type de machine retenu. Par exemple, une n2-standard-2 vous donne 2 vCPU et (2x12) 24 threads ; une n2-standard-8, 8 vCPU et (8x12) 96 threads par défaut.
Dataflow vous permet de configurer le nombre de threads par vCPU ou par VM selon votre SDK. Ce sont les Worker harness threads.
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
Ajustez le niveau de parallélisme selon vos besoins et votre workload. Comme plusieurs threads partagent le même espace mémoire, mieux vaut en réduire le nombre pour les jobs gourmands en mémoire. À l'inverse, pour un workload moins exigeant, augmentez-le afin de paralléliser davantage. Plus le parallélisme est élevé, plus un même worker peut prendre en charge d'éléments. Mais à trop vouloir paralléliser, on s'expose à divers problèmes – le plus courant étant l'Out Of Memory, auquel cas Dataflow réessaiera le travail. Et si vous appelez des ressources tierces comme des API, vérifiez qu'elles peuvent absorber le volume d'appels.
Optimisation par fusion
Lorsque vous soumettez votre code au runner Dataflow, sa première action après compilation est de construire un graphe d'exécution. Vous pouvez le visualiser dans la Google Cloud Console ; pour en savoir plus, suivez ce lien. Une fois le graphe créé et validé par le runner, le service Dataflow peut le modifier pour y appliquer des optimisations. L'une d'elles consiste à combiner (fusionner) plusieurs étapes en opérations plus larges, afin que le service n'ait pas à matérialiser les données entre chaque étape. Le traitement gagne en rapidité puisque les opérations se chaînent en mémoire ; en contrepartie, l'ensemble des étapes fusionnées s'exécute obligatoirement sur la machine de départ. Si la fusion contribue largement à la puissance de Dataflow, elle peut aussi générer des goulots d'étranglement. Comme elle s'appuie sur le graphe construit avant que les données ne traversent le pipeline, Dataflow ne détecte pas les cas suivants, qui limitent la parallélisation.
Figure 1 : graphe d'exécution optimisé pour l'exemple Wordcount, cet exemple WordCount en Java
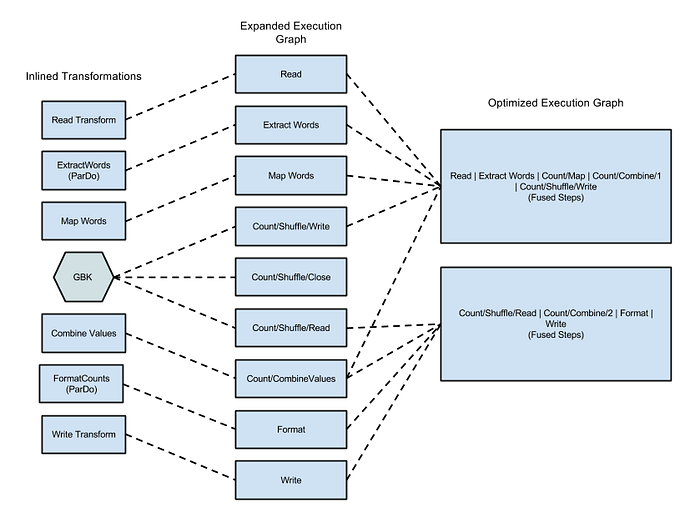
la documentation Dataflow montre l'allure du graphe lorsque l'exemple est exécuté avec le runner Dataflow.
High Fanout
Lorsqu'un de vos ParDos produit en sortie bien plus d'éléments qu'il n'en a reçus en entrée, mieux vaut envisager un reshuffle. Imaginons que vous traitiez un fichier en entrée et que la sortie corresponde à des lignes individuelles : après ce ParDo, Dataflow se retrouve avec bien plus d'éléments que prévu sur le même worker. Dataflow se base alors sur le nombre attendu d'éléments en entrée pour déterminer combien d'instances allouer à l'étape fusionnée. En cassant la fusion, il peut rééquilibrer la charge et traiter davantage d'éléments en parallèle.
Données mal réparties entre les machines
Si votre job consomme des fichiers de tailles variables en entrée, le volume de données circulant dans le pipeline est très probablement déséquilibré. Certains workers auront alors bien plus à traiter que d'autres. Sans reshuffle, certaines machines resteront inactives pendant que d'autres tourneront à plein régime.
Vous pouvez [casser la fusion](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion) de trois façons :
- GroupByKey (Dataflow ne fusionne jamais les étapes d'agrégation). Dataflow ne fusionne jamais les étapes d'agrégation.
- Ajouter votre PCollection intermédiaire en tant que side input. Une side input étant toujours matérialisée, fusionner ces étapes n'a pas de sens.
- Ajouter une étape de reshuffle (Reshuffle reste pris en charge par Dataflow, même s'il est marqué comme deprecated dans la documentation Apache Beam). Avec Reshuffle, les données sont redistribuées entre les workers.
Workers préemptifs avec FlexRS
Pour réduire le coût des jobs batch, vous pouvez vous tourner vers la fonctionnalité FlexRS, réservée aux workloads non critiques en termes de délai (tâches quotidiennes ou mensuelles, par exemple). FlexRS combine instances VM classiques et instances VM préemptives, et s'efforce d'éviter la perte de traitement lorsque ces dernières s'arrêtent. FlexRS n'est utilisable qu'avec le service Dataflow Shuffle.
Au moment de l'activer, vous pouvez choisir entre l'optimisation des coûts ou de la vitesse.
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
FlexRS reposant sur le choix d'instances peu coûteuses lors de l'auto-scaling, vous ne pouvez pas régler l'algorithme d'auto-scaling sur NONE.
L'API d'écriture du stockage BigQuery
En 2021, Google a lancé une nouvelle API BigQuery pour les workloads batch et streaming. Ce nouvel endpoint garantit l'idempotence des données ajoutées au sein d'un même flux, et son quota de débit par défaut est trois fois supérieur à celui de l'API historique.
Surtout, son coût est inférieur de 50 % par Go par rapport à l'ancienne. Si votre pipeline streame de gros volumes vers BigQuery, l'économie peut être considérable. Pour les chiffres précis, consultez la page de tarification.
Malheureusement, à l'heure où ces lignes sont écrites (janvier 2023), seul le SDK Java prend en charge la nouvelle API d'écriture du stockage.
Côté Java, une légère modification suffit pour utiliser la Storage Write API. Ajoutez Method.STORAGE_WRITE_API en paramètre de .withMethod(), comme ceci :
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
Vous trouverez plus de détails sur la mise en œuvre dans la documentation BigQueryIO.
L'optimisation des coûts Dataflow dépend de nombreux facteurs. Pour la plupart des recommandations, il faut arbitrer entre performance/vélocité et coût.
Adopter la dernière API BigQuery permet aussi de réaliser d'importantes économies. D'autres optimisations relèvent du code et passent par les bonnes pratiques Dataflow / Apache Beam. Vous pouvez vous appuyer sur les patterns de pipeline courants. Mon préféré reste le pattern dead-letter BigQuery. Et pour approfondir le sujet, voici un excellent article sur le Streaming engine.