Se gestisce data pipeline su Google Cloud Platform (GCP), probabilmente usa Dataflow, il runner per i workloads Apache Beam. Quando una pipeline arriva in produzione e funziona, è il momento di renderla più efficiente sul fronte dei costi. Trovare le impostazioni ottimali non è semplice, vista la quantità di opzioni e parametri disponibili: in questo articolo la guido passo per passo.

Sfruttare lo Streaming Engine
Uno dei modi più semplici per ridurre i costi è abilitare lo Streaming Engine. Senza Streaming Engine, l'Autoscaler usa il disco persistente come indicatore per il numero di worker. I dischi non vengono mai rimossi da un job in esecuzione: ogni worker deve avere almeno un disco persistente e il numero di dischi collegati deve essere uguale tra tutti i worker. Per garantire una distribuzione uniforme dei dischi, Dataflow può quindi ridurre il numero di worker al massimo del 50%. Quando lo Streaming Engine è attivo, gran parte del lavoro — come gli step di shuffle e groupByKey — viene delegata al servizio Streaming Engine e l'autoscaling di Dataflow non dipende più dai dischi collegati. Per lo stesso motivo può anche ridurre la dimensione del disco a 30 GB.
Lo Streaming Engine supporta pipeline Java (SDK => 2.11.0) e Python (SDK => 2.21.0).
Java: - enableStreamingEngine
Python: abilitato di default.
Go: non ancora supportato.
Il numero massimo di worker
L'Horizontal Autoscaling, in passato chiamato semplicemente Autoscaling, sceglie automaticamente il numero di worker necessari al job. Il valore massimo predefinito è 1000 worker per i job batch e 100 per i job di streaming.
Limitando il numero massimo di worker si abbattono i costi. Tuttavia, elaborare grandi volumi di dati con un solo worker può richiedere un'eternità. In base ai requisiti di business e alla variabilità dei dati può individuare il numero giusto di worker. La mia esperienza suggerisce di prevederne dieci in più rispetto a quanti ne servono al job nell'80% dei casi: in questo modo dispone di un buffer nel pool per assorbire i picchi. Quando i picchi sono più consistenti e il backlog di Dataflow non si riduce abbastanza in fretta, dovrà alzare ulteriormente il tetto.
Se non usa lo Streaming Engine, tenga presente che verrà allocato un pool fisso di dischi persistenti pari al numero massimo di worker. Può impostare il numero massimo di worker con i seguenti flag:
Java: - maxNumWorkers
Python: - max_num_workers
Go: - max_num_workers
Parallelizzazione
Dataflow è un servizio gestito sviluppato da Google per l'elaborazione distribuita dei dati su larga scala. La voce di costo principale sono le risorse di calcolo, che vanno quindi sfruttate nel modo più efficiente possibile. Diversi parametri della pipeline permettono di regolare con precisione la parallelizzazione sulle risorse giuste. Dataflow è progettato per processare enormi quantità di dati e gran parte del lavoro avviene in parallelo. Con Dataflow può aumentare la parallelizzazione in 2 modi: aggiungendo worker oppure definendo più thread per worker. In questo articolo, per parallelizzazione intenderemo i thread per worker.
La parallelizzazione su un singolo worker aiuta a contenere i costi perché lo stesso worker elabora più elementi. E quando un singolo worker ne elabora di più, a Dataflow ne servono meno per portare a termine il job.
Tipo di macchina e thread concorrenti
La maggior parte del costo di Dataflow è destinata alle risorse di calcolo. Per questo è essenziale scegliere il tipo di macchina più adatto al job. Google Cloud Platform offre un'ampia gamma di tipologie.
Per workloads memory-intensive, la N1 è leggermente più economica della più recente N2.
Quando invece i job fanno largo uso di CPU, la più diffusa serie N2 è la scelta migliore. La serie N2 propone tre varianti: N2-standard, N2 high-mem e N2 high-CPU. Il tipo standard offre 4 GB di memoria per vCPU; la high-mem ne offre 8 GB per vCPU; la high-CPU, infine, 1 GB per vCPU. I prezzi sono disponibili qui.
Dataflow esegue i workloads in parallelo. In modalità Streaming, esegue una DoFn per thread. È importante sapere che la parallelizzazione nell'SDK Python funziona in modo diverso rispetto agli SDK Java e Go: Python esegue un processo e, di default, 12 thread per vCPU, mentre Go e Java eseguono un processo e 300 thread per VM. Il numero di thread predefiniti nell'SDK Python dipende dalle vCPU del tipo di macchina scelto. Ad esempio, con la n2-standard-2 ha 2 vCPU e (2x12) 24 thread; con la n2-standard-8 ha 8 vCPU e (8x12) 96 thread di default.
Dataflow le permette di configurare il numero di thread per vCPU o per VM, a seconda dell'SDK. Sono i cosiddetti Worker harness threads.
Java: - numberOfWorkerHarnessThreads
Python: - number_of_worker_harness_threads
Il livello di parallelismo va calibrato in base alle esigenze e ai workloads. Poiché più thread condividono lo stesso spazio di memoria, conviene abbassarne il numero per i job memory-intensive. Quando il workload è meno gravoso può invece alzarlo, in modo da eseguire più operazioni in parallelo. Più alto è il parallelismo, più elementi un singolo worker riesce a gestire. Spingendo troppo sul parallelismo possono però emergere diversi problemi: il più comune è l'Out Of Memory, dopo il quale Dataflow ritenta l'esecuzione. E se la pipeline chiama risorse di terze parti come API, si assicuri che siano in grado di reggere il volume di chiamate.
Fusion optimization
Quando invia il codice al runner Dataflow, la prima cosa che Dataflow fa dopo la compilazione è creare un grafo di esecuzione basato sul codice. Può visualizzarlo nella Google Cloud Console; per maggiori informazioni segua questo link. Una volta creato e validato dal runner, il servizio Dataflow può intervenire sul grafo per applicare ottimizzazioni. Una di queste consiste nel combinare (fondere) step separati in operazioni più ampie, così che il servizio non debba materializzare i dati tra uno step e l'altro. L'elaborazione diventa così più veloce, perché i dati vengono processati in memoria con più operazioni, ma di contro tutti gli step combinati restano vincolati alla macchina di partenza. La Fusion optimization è uno dei punti di forza di Dataflow, ma può anche generare colli di bottiglia. Poiché si basa sul grafo costruito dal codice prima che i dati inizino a scorrere nella pipeline, Dataflow non riesce a rilevare i seguenti casi che limitano la parallelizzazione.
Figura 1: grafo di esecuzione ottimizzato per l'esempio Wordcount, l'esempio Java WordCount
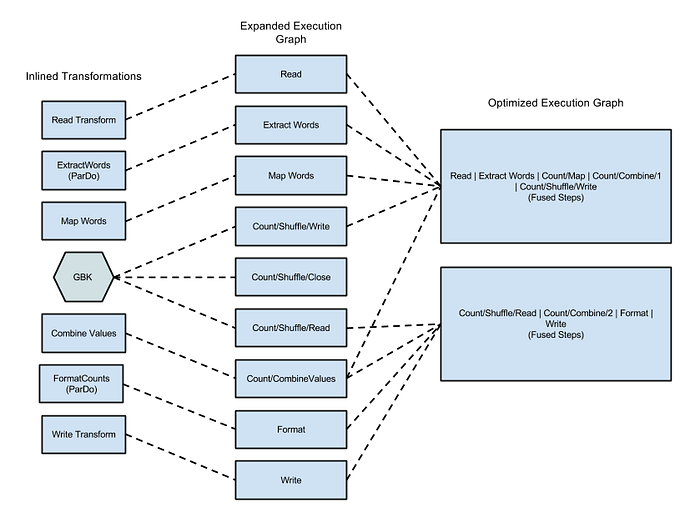
la documentazione di Dataflow mostra come si presenta il grafo eseguendo l'esempio con il runner Dataflow.
High Fanout
Quando uno dei suoi ParDo produce in output molti più elementi di quanti ne abbia ricevuti in input, conviene valutare un reshuffle dei dati. Pensi al caso in cui prende un file in input e restituisce le singole righe: dopo quel ParDo, Dataflow si ritrova sullo stesso worker molti più elementi del previsto. Dataflow infatti usa il numero atteso di elementi in input per stabilire quante istanze servono allo step di fusione. Spezzando la fusione, può ribilanciare il workload ed elaborare più elementi in parallelo.
Dati distribuiti in modo non uniforme tra le macchine
Se ha un job che consuma file in input di dimensioni molto diverse tra loro, è molto probabile che il volume di dati che attraversa la pipeline risulti sbilanciato. Alcuni worker avranno molto più lavoro di altri. Senza un reshuffle dei dati, alcune macchine resteranno inattive mentre altre lavoreranno a pieno regime.
Può [interrompere la fusione](https://cloud.google.com/dataflow/docs/pipeline-lifecycle\#preventing_fusion) in tre modi:
- GroupByKey (Dataflow non fonde mai gli step di aggregazione). Dataflow non fonde mai gli step di aggregazione.
- Aggiungere la PCollection intermedia come side input. Un side input viene sempre materializzato, quindi fondere quegli step non avrebbe senso.
- Aggiungere uno step di reshuffle (Reshuffle è supportato da Dataflow anche se nella documentazione di Apache Beam è contrassegnato come deprecato). Con Reshuffle i dati vengono ridistribuiti tra i diversi worker.
Worker preemptible con FlexRS
Per ridurre il costo dei job batch può iniziare a usare la funzionalità FlexRS, adatta però solo a workloads non time-critical, come task giornalieri o mensili. FlexRS combina istanze VM regolari e istanze VM preemptible. Dataflow FlexRS cerca di evitare la perdita dei processi quando le macchine preemptible vengono interrotte. Può usare FlexRS solo in combinazione con il servizio Dataflow Shuffle.
Per abilitare FlexRS può scegliere tra ottimizzazione del costo e ottimizzazione della velocità.
Java: - flexRSGoal=COST_OPTIMIZED
Python: - flexrs_goal=COST_OPTIMIZED
Go: - flexrs_goal=COST_OPTIMIZED
Tenga presente che, dato che FlexRS si basa sulla scelta di istanze economiche durante l'autoscaling, non può impostare l'algoritmo di autoscaling su NONE quando usa FlexRS.
BigQuery write storage API
Nel 2021 Google ha lanciato una nuova BigQuery API per workloads batch e streaming. Questo nuovo endpoint garantisce che i dati aggiunti siano idempotenti all'interno dello stesso stream. La quota di throughput predefinita della nuova write API è tre volte superiore a quella della legacy API.
Soprattutto, il costo della nuova API è inferiore del 50% per GB rispetto alla legacy API. Se la sua pipeline invia in streaming grandi volumi di dati a BigQuery, il risparmio può essere notevole. Per i valori esatti consulti la pagina dei prezzi.
Purtroppo, al momento della stesura di questo articolo (gennaio 2023), solo l'SDK Java supporta la nuova write storage API.
In Java basta una piccola modifica al codice per usare la Storage Write API: aggiunga Method . STORAGE_WRITE_API come parametro a .withMethod(), come segue.
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
Maggiori dettagli sull'implementazione sono disponibili nella documentazione BigQueryIO.
L'ottimizzazione dei costi di Dataflow dipende da molti fattori. Per la maggior parte di questi accorgimenti dovrà trovare un compromesso tra performance/velocità e costo.
Anche l'adozione della nuova BigQuery API consente risparmi significativi. Ulteriori ottimizzazioni si possono ottenere a livello di codice seguendo le best practice di Dataflow/Apache Beam e ricorrendo ai common pipeline pattern. Il mio preferito è il BigQuery dead-letter pattern. Per approfondire lo Streaming engine le consiglio questo ottimo articolo.