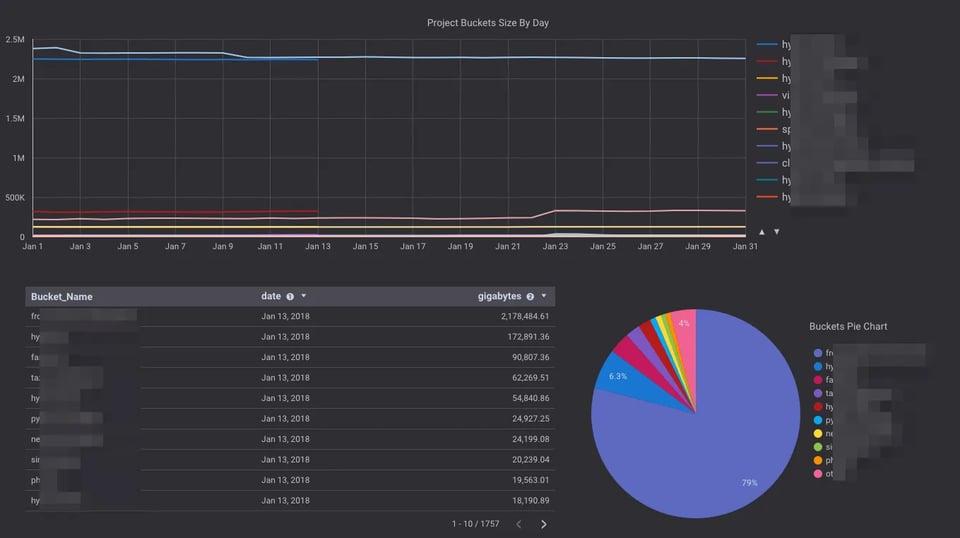
Pub/Sub、Cloud Functions、BigQueryを使い、わずか数クリックでGoogle Cloud Storageバケットのサイズをまとめて低コストに分析する方法をご紹介します。
オブジェクト数が膨大なバケットのサイズを把握しようとして、Stackdriver MonitoringのCloud Storageダッシュボードでは推定値しか表示されず、正確なサイズがわからないと感じたことはないでしょうか。
実際、この推定値は実サイズと大きくかけ離れていることがあります。
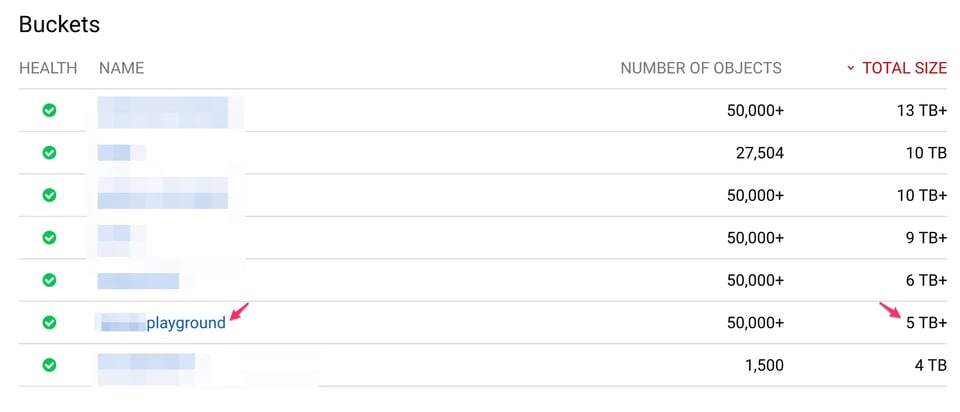
Access LogsとStorage Logsで確認した、図中のバケットのサイズは次のとおりです。
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619バイト(約69TB)
では、より正確なサイズを把握するにはどうすればよいのでしょうか。
選択肢の一つは、gsutil duコマンドでバケット内の全オブジェクトの使用容量を取得する方法です。しかし、数十万から数百万のオブジェクトを抱える大規模バケットでgsutil duを実行すればわかるとおり、処理にはかなりの時間がかかります。gsutil duはバケットのリスト取得リクエストを発行して使用量を集計する仕組みのため、時間もコストも大きく膨らみます。storage.objects.listはClass Aオペレーション、つまりCloud Storageの中でも最もコストの高いオペレーションに分類されます。
もう一つの方法は、Cloud StorageのAccess LogsとStorage Logsを使って、バケット統計の日次レポートを取得することです。Cloud StorageはアクセスログとストレージログをCSVファイルとして提供しており、ダウンロードして閲覧できます。アクセスログは指定バケットへの全リクエストの情報を1時間ごとに、ストレージログは前日のバケットのストレージ消費量を1日単位で記録します。
通常知りたいのは、バケットの日次ストレージサイズです。gsutil duは現実的でなく、Stackdriver Monitoringもこの用途では精度に欠けます。
そこで本記事では、Storage LogsとPub/Subトピックでトリガーされる Cloud Function(CF)を使って、ストレージ消費ログを自動でBigQueryに読み込み、バケットサイズをクエリ・可視化する仕組みを構築します。読み込みが完了したストレージログは別のバケットに移動し、読み込みに失敗したログやその他のオブジェクトは「errors」バケットに振り分けます。
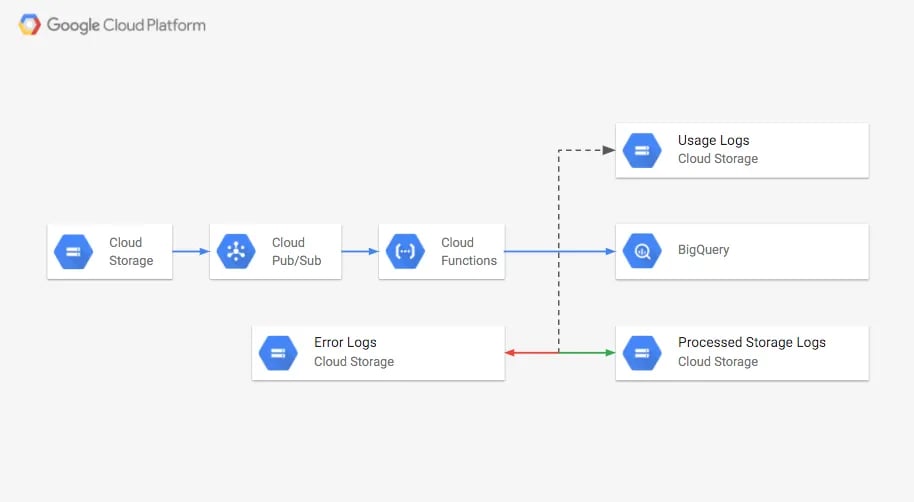
- 他のバケットのStorage LogsとAccess Logsを格納するためのバケットを作成します。対象プロジェクトに切り替え、ログ保存用の新しいバケットを作成してください。
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- ストレージログとアクセスログを分けて保存し、さらにBigQueryへの読み込みに失敗したログ用のバケットも別途用意します。CFによる処理後、ログは
gs://LOGS-BUCKETから各バケットへ移動されます。
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKET注:1つのバケット内でフォルダを分ける構成も可能ですが、その場合はCFのコードを少し書き換える必要があります。
- GoogleのCloud Storage Analyticsサービスアカウントに、新しいバケットへの書き込み権限を付与します。
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- バケットからPub/Subへの通知を有効化します。次のコマンドは
gs://LOGS-BUCKETに対する通知設定を作成し、オブジェクトが作成・変更・削除・アーカイブされるたびに、関連情報を含むメッセージをPub/Subトピックに送信します。今回はオブジェクトが作成されたタイミング(=ログオブジェクトが生成されたタイミング)だけを対象にしたいので、OBJECT_FINALIZEイベントのみを監視します。
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET-fフラグはメッセージのペイロード情報を指定します。指定可能な値はjsonまたはnoneです。今回はCF内でバケットのメタデータ情報を使わないため、noneを選択しました。- 開発者コンソールのPub/Subページを確認すると、上記コマンドにより
projects/PROJECT-ID/topics/LOGS-BUCKETという名前のトピックが作成されていることがわかります。新規オブジェクトに関するメッセージは、このトピックにパブリッシュされます。
- 新しいBigQueryのデータセットとテーブルを作成します。
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- これからデプロイする関数のステージング用バケットを作成します。
gsutil mb gs://CF-STAGING-BUCKET- Cloud Functionのコードをクローンします。
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-stats重要:任意のテキストエディタでconfig.jsを開き、これまでの手順に合わせて値を編集してください。
- 設定ファイルを編集したら、関数をデプロイします。
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- 最後に、分析対象としたいバケットでAccess LogsとStorage Logsを有効化します。ログの出力先は、最初の手順で作成した
gs://LOGS-BUCKETです。
各バケットのプロジェクトIDを列として保持したいところですが、ログ自体にはこの情報が含まれていないため、ログファイル名にカスタムプレフィックスを付与します。今回採用するプレフィックスはPROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET]です。
重要:すでに対象バケットでロギングが有効になっている場合、次のコマンドを実行すると既存のロギング設定は停止されます。
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKET例えば、my-storage-projectプロジェクトにgs://my-enormous-bucketというバケットがある場合、プレフィックスはPROJECT_my-storage-project_BUCKET_my-enormous-bucketとなります。カスタムプレフィックスを使わない場合、ログオブジェクトの名前はデフォルトのプレフィックスとなり、BigQueryテーブルのproject_id列はnullになります。
- 監視したい他のバケットについても、前の手順と同様にログを有効化します。
ストレージログが日次で書き込まれるたびに、Pub/Subトピックへメッセージが送信され、Cloud Functionがトリガーされます。新しいオブジェクトがストレージログであれば、内容が読み取られてBigQueryテーブルに挿入され、その後gs://PROCCESSED-LOGS-BUCKETへ移動されます。アクセスログであればgs://USAGE-LOGS-BUCKETへ移動されます。それ以外のオブジェクトはバケット内にそのまま残ります。ログの読み込み中にエラーが発生した場合は、gs://ERRORS-LOGS-BUCKETへ移動されます。
BigQueryテーブルをGoogle Data Studioに接続し、データを手軽に可視化できるダッシュボードを作成するのもおすすめです。