Un metodo economico per analizzare in pochi clic la dimensione di tutti i suoi bucket Google Cloud Storage, sfruttando Pub/Sub, Cloud Functions e BigQuery.
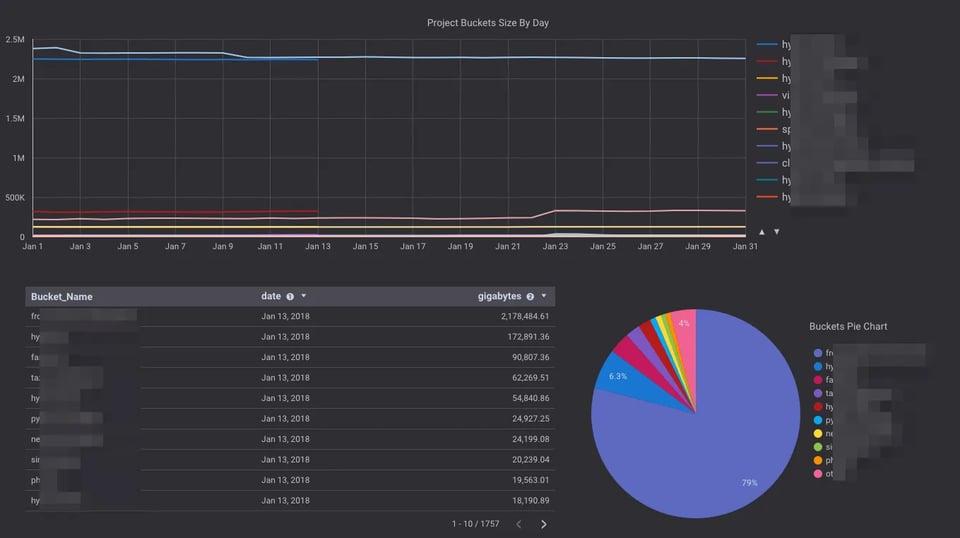
Se gestisce bucket con un numero enorme di oggetti e desidera conoscerne la dimensione, avrà notato che il dashboard di Stackdriver Monitoring per Cloud Storage mostra solo delle stime e non fornisce un valore preciso.
In effetti, queste stime a volte si discostano in modo sensibile dalle dimensioni reali dei bucket.
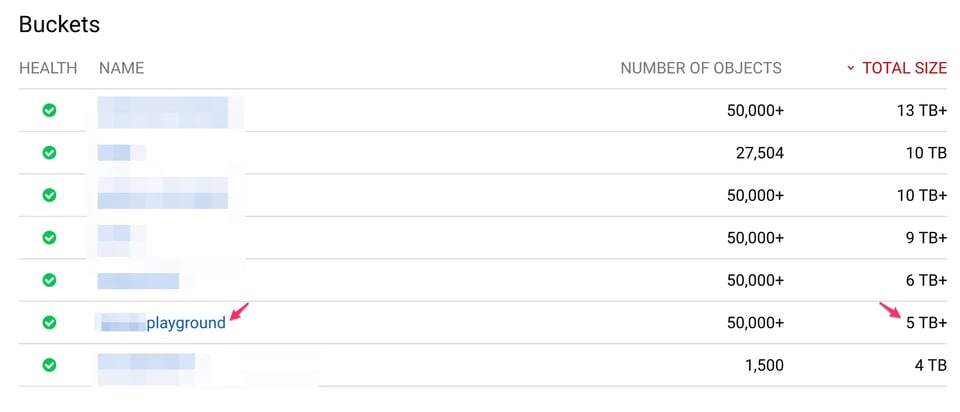
La dimensione del bucket evidenziato secondo gli Access Logs e gli Storage Logs è:
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619 byte (~69 TB)
Quali alternative ha a disposizione per ottenere un quadro più accurato della dimensione dei suoi bucket?
Una possibilità è il comando gsutil du, che restituisce lo spazio totale occupato da tutti gli oggetti del bucket. Tuttavia, eseguendo gsutil du su un bucket di grandi dimensioni con centinaia di migliaia o milioni di oggetti, si accorgerà che i tempi sono molto lunghi: il comando calcola l'utilizzo dello spazio tramite richieste di listing del bucket, operazione che può risultare lenta e piuttosto costosa. L'operazione storage.objects.list è infatti una Class A Operation, ovvero la più costosa tra quelle offerte da Cloud Storage.
Un'altra strada per ottenere un report giornaliero delle statistiche del bucket sono gli Access Logs e gli Storage Logs di Cloud Storage. Cloud Storage mette a disposizione access log e storage log sotto forma di file CSV scaricabili e consultabili. Gli access log riportano informazioni su tutte le richieste effettuate su un bucket specifico e vengono generati ogni ora, mentre gli storage log giornalieri descrivono il consumo di storage del bucket nel giorno precedente.
Di solito ciò che interessa è analizzare la dimensione giornaliera dello storage dei propri bucket. Eseguire gsutil du non è praticabile e attualmente Stackdriver Monitoring può risultare poco accurato per questo scopo.
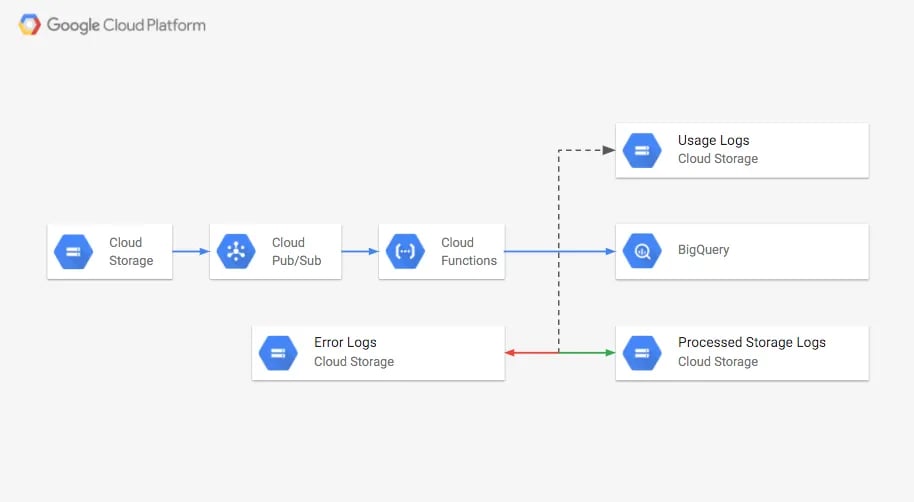
Utilizzeremo gli Storage Logs e una Cloud Function (CF) attivata da un topic Pub/Sub per caricare in automatico il log del consumo di storage in BigQuery, dove sarà possibile interrogare e visualizzare la dimensione del bucket. Gli storage log caricati verranno poi spostati in un altro bucket; quelli non caricati correttamente, così come gli altri oggetti, verranno invece spostati in un bucket di "errori".
- Crei un bucket in cui archiviare gli Storage e Access logs degli altri bucket. Selezioni il progetto designato e crei un nuovo bucket per i log
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- Conviene inoltre separare gli storage log dagli usage log e prevedere un bucket dedicato ai log che non sono stati caricati correttamente in BigQuery. I log verranno spostati da gs://LOGS-BUCKET al bucket appropriato dopo essere stati elaborati dalla CF.
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKETNota: in alternativa può usare cartelle differenti all'interno di un unico bucket, ma in questo caso dovrà modificare leggermente il codice della CF.
- Conceda al service account di Google Cloud Storage Analytics i permessi di scrittura sul nuovo bucket:
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- Abiliti le notifiche del bucket verso Pub/Sub. Il comando seguente crea una configurazione di notifica per gs://LOGS-BUCKET: ogni volta che un oggetto viene creato, modificato, eliminato o archiviato, verrà inviato un messaggio a un topic Pub/Sub con le informazioni pertinenti. Poiché ci interessa solo la creazione di nuovi oggetti (ovvero la generazione dei log), monitoreremo unicamente l'evento OBJECT_FINALIZE.
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET- Il flag -f specifica le informazioni di payload del messaggio. Le opzioni disponibili sono 'json' o 'none'. Nella nostra CF non utilizziamo alcun metadato del bucket, quindi abbiamo optato per 'none'.
- Aprendo la pagina Pub/Sub nella console per sviluppatori, noterà che il comando precedente ha creato un topic denominato projects/PROJECT-ID/topics/LOGS-BUCKET. I messaggi relativi ai nuovi oggetti verranno pubblicati su questo topic.
- Crei un nuovo dataset e una nuova tabella BigQuery
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- Crei uno staging bucket per la function che stiamo per distribuire
gsutil mb gs://CF-STAGING-BUCKET- Cloni il codice della Cloud Function
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-statsImportante: apra config.js con un editor di testo a sua scelta e modifichi i valori in base ai passaggi precedenti.
- Dopo aver modificato il file di configurazione, distribuisca la function
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- Infine, possiamo abilitare gli Access e Storage log su tutti i bucket che vogliamo analizzare. Il bucket di destinazione per i log è ovviamente quello creato al primo passaggio: gs://LOGS-BUCKET.
Vogliamo avere una colonna con il project ID di ciascun bucket. Poiché i log non includono questa informazione, useremo un prefisso personalizzato per il nome del file di log. Il prefisso scelto è PROJECT_[ANALYZED-PROJECT-ID]BUCKET[ANALYZED-BUCKET]
Importante: se ha già abilitato il logging sul bucket, eseguire il comando seguente interromperà la configurazione di logging esistente.
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKETAd esempio, se ha un bucket chiamato gs://my-enormous-bucket nel progetto my-storage-project, il prefisso dovrà essere PROJECT_my-storage-project_BUCKET_my-enormous-bucket. Se sceglie di non utilizzare il prefisso personalizzato, gli oggetti di log avranno il prefisso predefinito e la colonna project_id nella tabella BigQuery conterrà valori null.
- Abiliti i log per qualsiasi altro bucket che desideri monitorare, seguendo lo stesso procedimento del passaggio precedente.
Ogni giorno, alla scrittura degli storage log, un messaggio viene pubblicato sul topic Pub/Sub. Questi messaggi attivano la Cloud Function. Se il nuovo oggetto è uno storage log, viene letto e inserito nella tabella BigQuery, per poi essere spostato nel bucket gs://PROCCESSED-LOGS-BUCKET. Se si tratta di un access log, viene spostato in gs://USAGE-LOGS-BUCKET. Qualsiasi altro oggetto resta nel bucket di origine. Se durante il caricamento del log si verifica un errore, l'oggetto viene spostato in gs://ERRORS-LOGS-BUCKET.
Può anche collegare la tabella BigQuery a Google Data Studio e costruire un dashboard per visualizzare i dati con facilità.