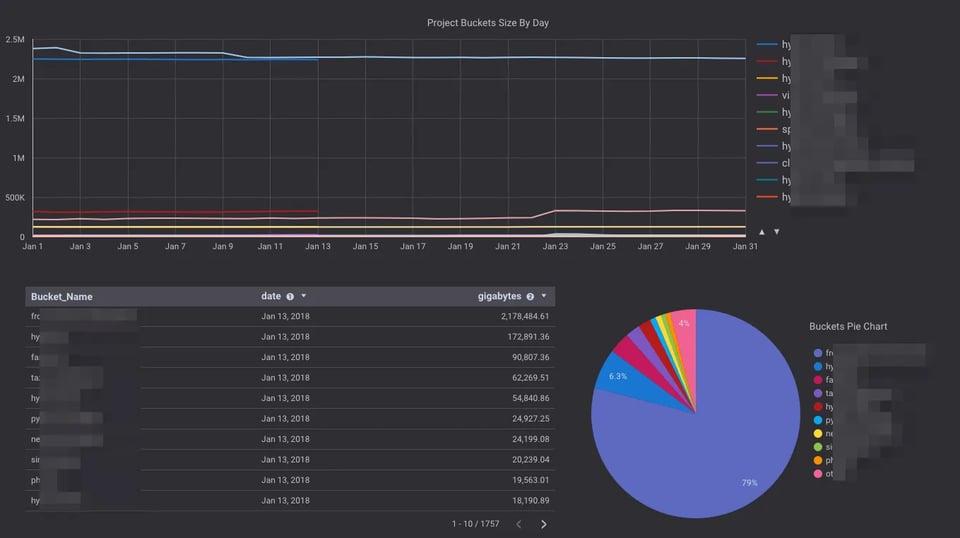
Eine günstige Methode, um die Größe all Ihrer Google Cloud Storage Buckets mit wenigen Klicks zu analysieren – mit Pub/Sub, Cloud Functions und BigQuery.
Wenn Sie Buckets mit enorm vielen Objekten betreiben und deren Größe wissen möchten, ist Ihnen vielleicht aufgefallen: Das Stackdriver Monitoring Cloud Storage Dashboard zeigt nur Schätzwerte an und liefert keine exakte Bucket-Größe.
Diese Schätzungen liegen mitunter sehr weit von den tatsächlichen Bucket-Größen entfernt.
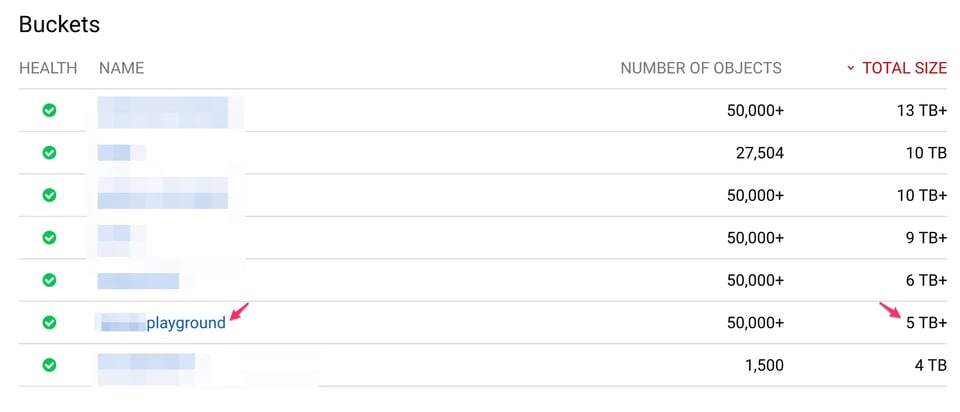
Die Größe des markierten Buckets gemäß Access Logs & Storage Logs beträgt:
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619 Bytes (~69 TB)
Welche Optionen haben Sie, um ein genaueres Bild Ihrer Bucket-Größen zu erhalten?
Sie könnten den Befehl gsutil du nutzen, um den Gesamtspeicher aller Objekte im Bucket zu ermitteln. Wer gsutil du jedoch schon einmal auf einem großen Bucket mit Hunderttausenden oder Millionen Objekten ausgeführt hat, weiß: Das dauert lange. Der Grund: gsutil du berechnet die Speichernutzung über Bucket-Listing-Anfragen – die sind zeitaufwendig und können richtig teuer werden. Die Operation storage.objects.list ist eine Class A Operation, also die teuerste Operation, die Cloud Storage zu bieten hat.
Eine weitere Möglichkeit für einen täglichen Bericht über die Bucket-Statistiken sind die Access Logs & Storage Logs für Cloud Storage. Cloud Storage stellt Access Logs und Storage Logs als CSV-Dateien zum Download bereit. Access Logs liefern Informationen zu allen Anfragen an einen bestimmten Bucket und werden stündlich erstellt; die täglichen Storage Logs geben Auskunft über den Speicherverbrauch dieses Buckets am Vortag.
In der Regel möchten Sie die tägliche Speichergröße Ihrer Buckets analysieren. gsutil du scheidet dafür aus, und Stackdriver Monitoring ist für diese Aufgabe derzeit zu ungenau.
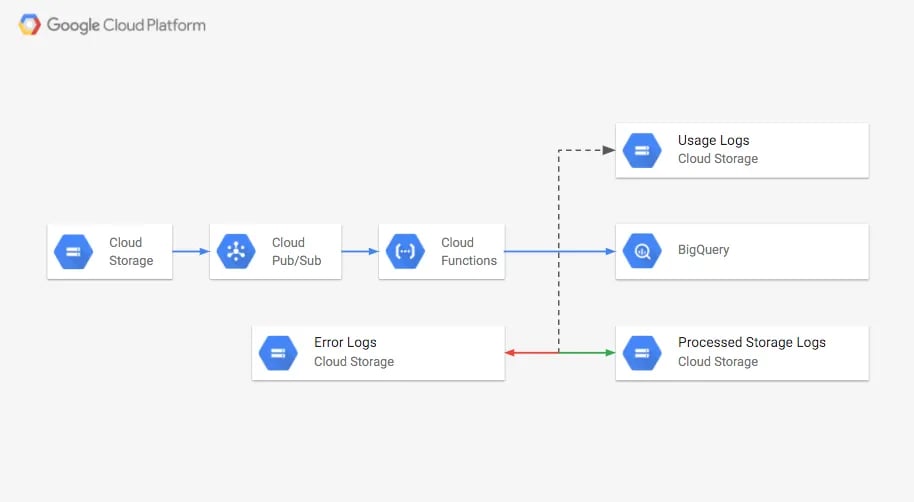
Wir nutzen daher die Storage Logs und eine Cloud Function (CF), die per Pub/Sub-Topic ausgelöst wird, um den Speicherverbrauch automatisch in BigQuery zu laden. Dort lässt sich die Bucket-Größe abfragen und visualisieren. Geladene Storage Logs werden anschließend in einen anderen Bucket verschoben. Logs, die nicht erfolgreich geladen werden konnten, sowie sonstige Objekte landen in einem "errors"-Bucket.
- Legen Sie einen Bucket an, in dem Sie die Storage- und Access-Logs für andere Buckets speichern. Wechseln Sie in Ihr Zielprojekt und erstellen Sie einen neuen Bucket für die Logs:
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- Außerdem möchten wir Storage Logs von Usage Logs trennen und einen separaten Bucket für Logs vorhalten, deren Laden in BigQuery fehlgeschlagen ist. Die Logs werden nach Verarbeitung durch die CF von gs://LOGS-BUCKET in den jeweils passenden Bucket verschoben.
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKETHinweis: Sie können stattdessen auch verschiedene Ordner in nur einem Bucket verwenden – das erfordert dann allerdings kleinere Anpassungen am CF-Code.
- Erlauben Sie dem Cloud Storage Analytics-Dienstkonto von Google, in unseren neuen Bucket zu schreiben:
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- Aktivieren Sie Bucket-Benachrichtigungen an Pub/Sub. Der folgende Befehl erstellt eine Benachrichtigungskonfiguration für gs://LOGS-BUCKET. Damit wird jedes Mal, wenn ein Objekt erstellt, geändert, gelöscht oder archiviert wird, eine Nachricht mit den relevanten Informationen an ein Pub/Sub-Topic gesendet. Da uns nur das Erstellen von Objekten interessiert (also wenn Log-Objekte angelegt werden), beobachten wir ausschließlich das Event OBJECT_FINALIZE.
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET- Das Flag -f legt die Payload-Informationen für die Nachricht fest. Verfügbar sind "json" oder "none". Da wir in unserer CF keine Bucket-Metadaten nutzen, wählen wir "none".
- Wenn Sie die Pub/Sub-Seite in der Developer Console öffnen, sehen Sie, dass der obige Befehl ein Topic mit dem Namen projects/PROJECT-ID/topics/LOGS-BUCKET erstellt hat. Nachrichten zu neuen Objekten werden in diesem Topic veröffentlicht.
- Erstellen Sie ein neues BigQuery-Dataset samt Tabelle:
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- Erstellen Sie einen Staging-Bucket für die Function, die wir gleich deployen:
gsutil mb gs://CF-STAGING-BUCKET- Klonen Sie den Code der Cloud Function:
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-statsWichtig: Öffnen Sie config.js in einem Texteditor Ihrer Wahl und passen Sie die Werte gemäß den vorherigen Schritten an.
- Nach dem Bearbeiten der Konfigurationsdatei deployen Sie die Function:
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- Zum Schluss aktivieren wir Access- und Storage-Logs für jeden Bucket, den wir analysieren möchten. Ziel-Bucket für die Logs ist natürlich der im ersten Schritt erstellte Bucket: gs://LOGS-BUCKET.
Wir möchten zu jedem Bucket eine Spalte mit der Projekt-ID haben. Da die Logs diese Information nicht enthalten, verwenden wir ein eigenes Präfix für den Log-Dateinamen. Unser gewähltes Präfix lautet PROJECT_[ANALYZED-PROJECT-ID]BUCKET[ANALYZED-BUCKET].
Wichtig: Falls für den Bucket bereits Logging aktiviert ist, beendet der folgende Befehl die bestehende Logging-Konfiguration.
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKETBeispiel: Heißt Ihr Bucket gs://my-enormous-bucket und liegt im Projekt my-storage-project, sollte das Präfix PROJECT_my-storage-project_BUCKET_my-enormous-bucket lauten. Verzichten Sie auf das eigene Präfix, erhalten die Log-Objekte den Standard-Präfix, und die Spalte project_id in der BigQuery-Tabelle enthält null-Werte.
- Aktivieren Sie wie im vorigen Schritt beschrieben das Logging für alle weiteren Buckets, die Sie überwachen möchten.
Sobald die Storage Logs täglich geschrieben werden, geht jeweils eine Nachricht an das Pub/Sub-Topic. Diese Nachrichten lösen die Cloud Function aus. Handelt es sich beim neuen Objekt um ein Storage Log, wird es eingelesen, in die BigQuery-Tabelle geschrieben und anschließend in den Bucket gs://PROCCESSED-LOGS-BUCKET verschoben. Bei einem Access Log erfolgt die Verschiebung nach gs://USAGE-LOGS-BUCKET. Alle übrigen Objekte verbleiben im Bucket. Tritt beim Laden eines Logs ein Fehler auf, wird es nach gs://ERRORS-LOGS-BUCKET verschoben.
Für eine einfache Visualisierung können Sie die BigQuery-Tabelle an Google Data Studio anbinden und sich ein eigenes Dashboard bauen.