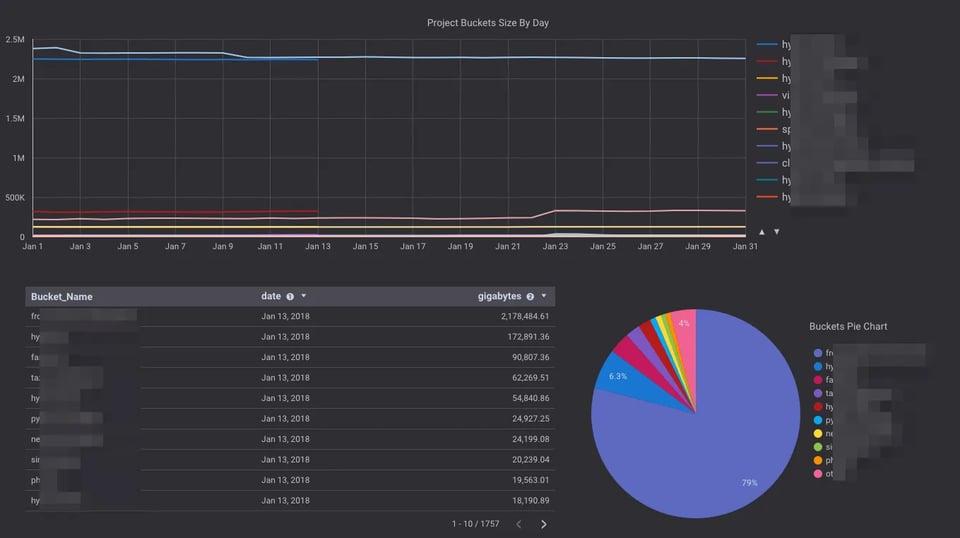
Uma forma econômica de analisar com poucos cliques o tamanho de todos os seus buckets do Google Cloud Storage usando Pub/Sub, Cloud Functions e BigQuery.
Se você tem buckets com um número enorme de objetos e precisa saber o tamanho deles, talvez já tenha notado que o dashboard de Cloud Storage no Stackdriver Monitoring exibe apenas estimativas, sem informar o tamanho exato.
Na prática, essas estimativas às vezes ficam bem distantes do tamanho real dos buckets.
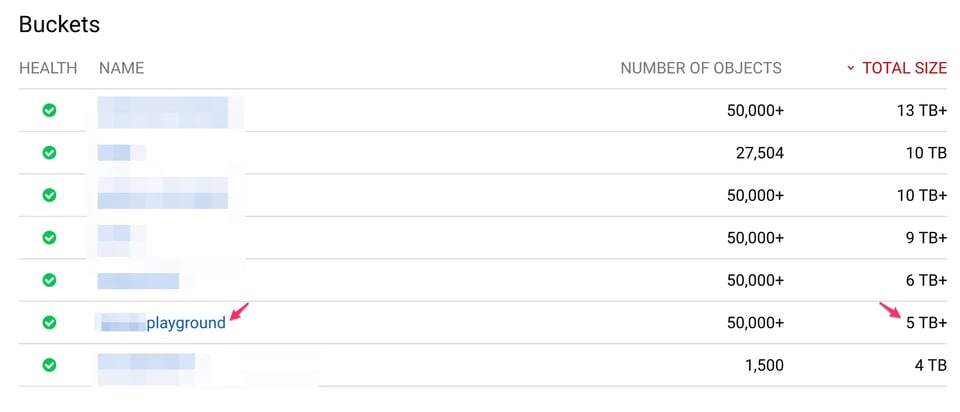
O tamanho do bucket destacado, de acordo com os Access Logs e Storage Logs, é:
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619 bytes (~69 TB)
Quais são as opções para ter um panorama mais preciso do tamanho dos seus buckets?
Você pode usar o comando gsutil du para descobrir o espaço total ocupado por todos os objetos do bucket. Mas, se já rodou gsutil du em um bucket grande, com centenas de milhares ou milhões de objetos, sabe que isso leva muito tempo, porque o comando calcula o uso de espaço fazendo requisições de listagem do bucket — algo demorado e que também pode sair caro. A operação storage.objects.list é uma operação Class A, ou seja, a mais cara que o Cloud Storage oferece.
Outra forma de obter um relatório diário das estatísticas do seu bucket é por meio dos Access Logs e Storage Logs do Cloud Storage. O Cloud Storage disponibiliza logs de acesso e de armazenamento em arquivos CSV que você pode baixar e visualizar. Os logs de acesso trazem informações sobre todas as requisições feitas em um bucket específico e são gerados de hora em hora, enquanto os logs diários de armazenamento mostram o consumo de armazenamento desse bucket no último dia.
No dia a dia, você normalmente vai querer analisar o tamanho diário do armazenamento dos seus buckets. Rodar gsutil du está fora de cogitação e, no momento, o Stackdriver Monitoring pode ser pouco preciso para essa tarefa.
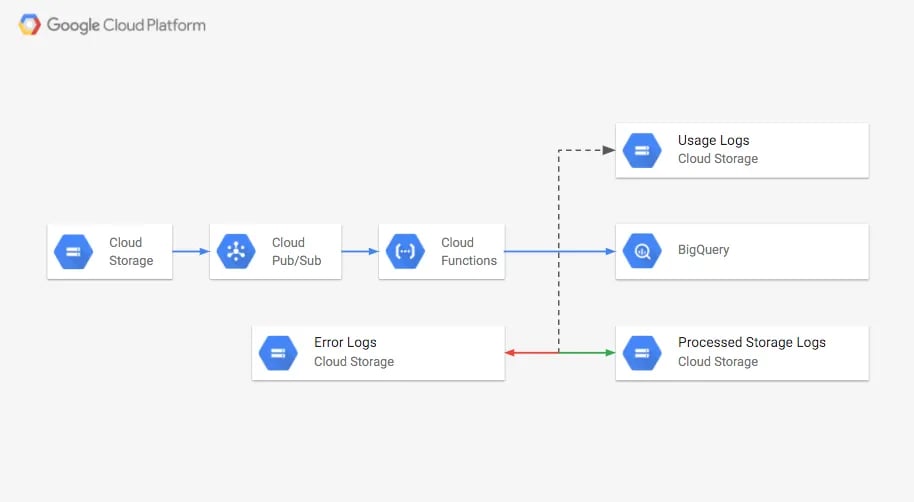
Vamos usar os Storage Logs e uma Cloud Function (CF) acionada por um tópico do Pub/Sub para carregar automaticamente o log de consumo de armazenamento no BigQuery, onde você pode consultar e visualizar o tamanho do bucket. Os logs de armazenamento que forem carregados serão movidos para outro bucket. Logs que não forem carregados com sucesso, ou outros objetos, serão movidos para um bucket de "errors".
- Crie um bucket para armazenar os Storage e Access logs dos demais buckets. Mude para o projeto desejado e crie um novo bucket para guardar os logs.
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- Também queremos separar os storage logs dos usage logs e ter um bucket para guardar os logs que não forem carregados no BigQuery. Os logs serão movidos de gs://LOGS-BUCKET para o bucket apropriado depois de processados pela CF.
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKETObservação: dá para usar pastas diferentes em um único bucket, mas isso exige alguns ajustes no código da CF.
- Permita que a service account do Cloud Storage Analytics do Google possa gravar no nosso novo bucket:
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- Habilite as notificações do bucket para o Pub/Sub. O comando a seguir cria uma configuração de notificação para gs://LOGS-BUCKET, ou seja, sempre que um objeto for criado, alterado, excluído ou arquivado, uma mensagem será enviada para um tópico do Pub/Sub com as informações relevantes. Como só nos interessa o momento em que os objetos são criados (quando os objetos de logs são gerados), vamos monitorar apenas o evento OBJECT_FINALIZE.
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET- A flag -f define as informações de payload da mensagem. As opções disponíveis são 'json' ou 'none'. Como não usamos nenhuma informação de metadados do bucket na nossa CF, escolhemos 'none'.
- Se você acessar a página do Pub/Sub no console do desenvolvedor, vai ver que o comando acima criou um tópico chamado projects/PROJECT-ID/topics/LOGS-BUCKET. As mensagens de novos objetos serão publicadas nesse tópico.
- Crie um novo dataset e uma tabela no BigQuery
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- Crie um bucket de staging para a function que vamos implantar
gsutil mb gs://CF-STAGING-BUCKET- Clone o código da Cloud Function
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-statsImportante: abra o arquivo config.js em um editor de texto e ajuste os valores conforme as etapas anteriores.
- Depois de editar o arquivo de configuração, faça o deploy da function
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- Por fim, podemos habilitar os Access e Storage logs em qualquer bucket que quisermos analisar. O bucket de destino dos logs é, claro, o bucket que criamos no primeiro passo: gs://LOGS-BUCKET.
Queremos ter uma coluna com o ID do projeto de cada bucket. Como os logs não trazem essa informação, vamos usar um prefixo personalizado no nome do arquivo de log. O prefixo escolhido é PROJECT_[ANALYZED-PROJECT-ID]BUCKET[ANALYZED-BUCKET]
Importante: se você já tem o logging habilitado no bucket, executar o comando a seguir vai sobrescrever a configuração de logging atual.
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKETPor exemplo, se você tem um bucket chamado gs://my-enormous-bucket no projeto my-storage-project, o prefixo deve ser PROJECT_my-storage-project_BUCKET_my-enormous-bucket. Se optar por não usar o prefixo personalizado, os objetos de log ficarão com o prefixo padrão e a coluna project_id na tabela do BigQuery vai ficar com valores nulos.
- Habilite os logs para qualquer outro bucket que queira monitorar, seguindo o passo anterior.
Quando os storage logs forem gerados todos os dias, uma mensagem será enviada para o tópico do Pub/Sub. Essas mensagens acionam a Cloud Function. Se o novo objeto for um storage log, ele será lido, inserido na tabela do BigQuery e, em seguida, movido para o bucket gs://PROCCESSED-LOGS-BUCKET. Se for um access log, será movido para gs://USAGE-LOGS-BUCKET. Qualquer outro objeto permanecerá no bucket. Caso ocorra algum erro durante o carregamento do log, ele será movido para gs://ERRORS-LOGS-BUCKET.
Uma boa ideia é conectar a tabela do BigQuery ao Google Data Studio e montar um dashboard para visualizar os dados com facilidade.