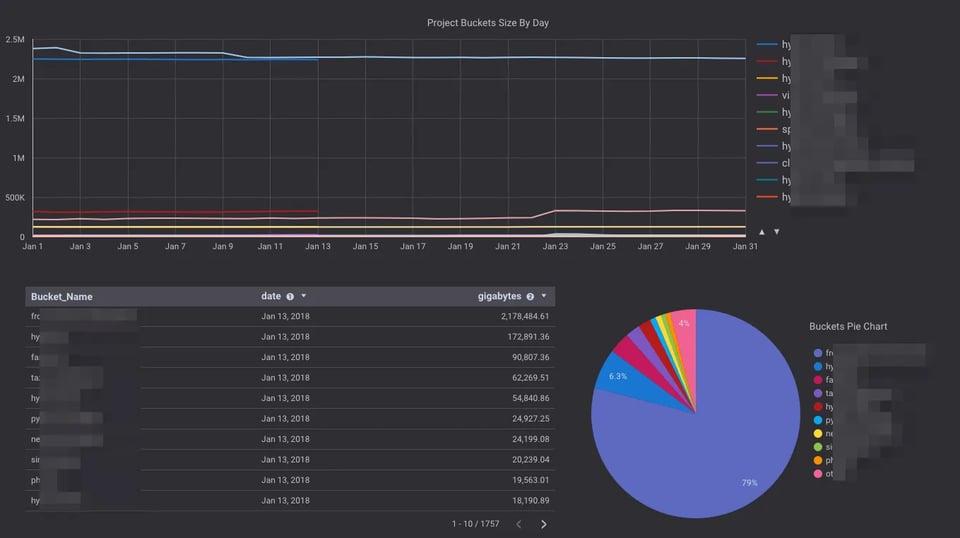
Una forma económica y sencilla de analizar el tamaño de todos tus buckets de Google Cloud Storage con unos pocos clics, usando Pub/Sub, Cloud Functions y BigQuery.
Si tienes buckets con una cantidad enorme de objetos y quieres conocer su tamaño, quizá ya notaste que el dashboard de Stackdriver Monitoring para Cloud Storage solo muestra estimaciones y no entrega el tamaño real del bucket.
De hecho, esas estimaciones a veces se alejan bastante del tamaño real.
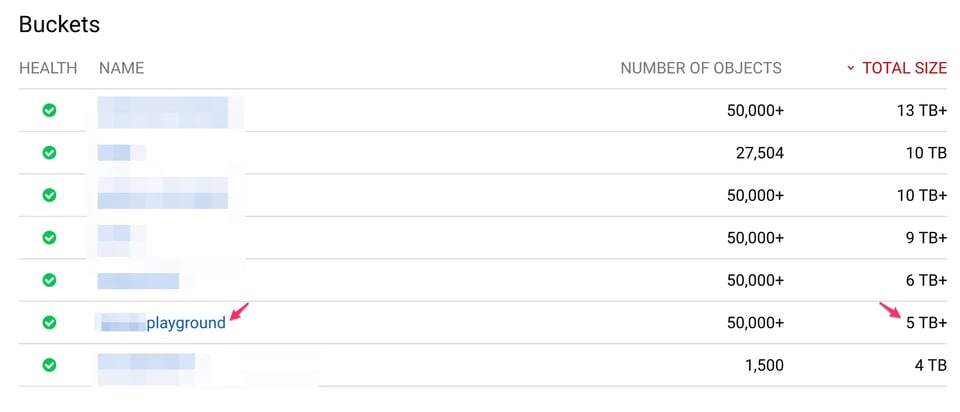
El tamaño del bucket marcado, según los Access Logs y Storage Logs, es:
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619 bytes (~69 TB)
¿Qué opciones tienes para conocer con mayor exactitud el tamaño de tus buckets?
Podrías usar el comando gsutil du para obtener el espacio total que ocupan todos los objetos del bucket. Sin embargo, si has intentado ejecutar gsutil du en un bucket grande con cientos de miles o millones de objetos, te habrás dado cuenta de que demora muchísimo, ya que gsutil du calcula el uso de espacio mediante solicitudes de listado del bucket, lo que toma bastante tiempo y resulta costoso. La operación storage.objects.list es una operación de Clase A, es decir, la más cara que ofrece Cloud Storage.
Otra forma de obtener un reporte diario de las estadísticas de tu bucket son los Access Logs y Storage Logs de Cloud Storage. Cloud Storage los entrega en formato CSV para que los descargues y revises. Los Access Logs incluyen información sobre todas las solicitudes hechas a un bucket determinado y se generan cada hora, mientras que los Storage Logs diarios entregan información sobre el consumo de almacenamiento del bucket durante el día anterior.
Lo habitual es querer analizar el tamaño diario de almacenamiento de tus buckets. Ejecutar gsutil du queda descartado y, por ahora, Stackdriver Monitoring puede resultar algo impreciso para esta tarea.
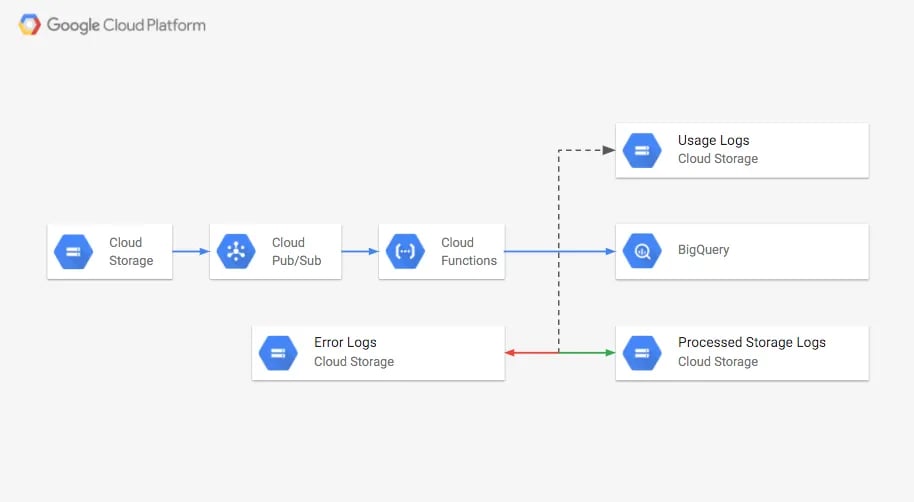
Vamos a usar los Storage Logs y una Cloud Function (CF) activada por un tópico de Pub/Sub para cargar automáticamente el log de consumo de almacenamiento en BigQuery, donde podrás consultar y visualizar el tamaño del bucket. Los Storage Logs ya cargados se moverán a otro bucket. Los logs que no se cargaron correctamente, u otros objetos, se moverán a un bucket de "errores".
- Crea un bucket donde vas a almacenar los Storage y Access Logs de los demás buckets. Cambia al proyecto que vas a usar y crea un nuevo bucket para guardar los logs.
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- También conviene separar los Storage Logs de los Usage Logs y tener un bucket aparte para los logs que fallaron al cargarse en BigQuery. Después de que la CF los procese, los logs se moverán desde gs://LOGS-BUCKET al bucket que corresponda.
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKETNota: También puedes usar distintas carpetas dentro de un solo bucket, pero eso requerirá modificar un poco el código de la CF.
- Permite que la cuenta de servicio de Cloud Storage Analytics de Google escriba en nuestro nuevo bucket:
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- Habilita las notificaciones del bucket hacia Pub/Sub. El siguiente comando crea una configuración de notificaciones para gs://LOGS-BUCKET, de modo que cada vez que se cree, modifique, elimine o archive un objeto, se enviará un mensaje a un tópico de Pub/Sub con la información correspondiente. Como solo nos interesa cuándo se crean los objetos (es decir, cuando se generan los logs), vamos a observar únicamente el evento OBJECT_FINALIZE.
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET- La opción -f especifica la información del payload del mensaje. Las opciones disponibles son 'json' o 'none'. Como en nuestra CF no usamos ningún metadato del bucket, elegimos 'none'.
- Si revisas la página de Pub/Sub en la consola de desarrolladores, verás que el comando anterior creó un tópico llamado projects/PROJECT-ID/topics/LOGS-BUCKET. Los mensajes de objetos nuevos se publicarán en ese tópico.
- Crea un nuevo dataset y tabla en BigQuery
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- Crea un bucket de staging para la función que vamos a desplegar
gsutil mb gs://CF-STAGING-BUCKET- Clona el código de la Cloud Function
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-statsImportante: Abre config.js con cualquier editor de texto y ajusta los valores según los pasos anteriores.
- Después de editar el archivo de configuración, despliega la función
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- Por último, podemos habilitar los Access y Storage Logs en cualquier bucket que queramos analizar. El bucket de destino para los logs es, por supuesto, el que creamos en el primer paso: gs://LOGS-BUCKET.
Queremos contar con una columna con el ID de proyecto de cada bucket. Como los logs no incluyen esa información, vamos a usar un prefijo personalizado en el nombre del archivo de log. El prefijo elegido es PROJECT_[ANALYZED-PROJECT-ID]BUCKET[ANALYZED-BUCKET]
Importante: si ya tienes el logging habilitado en el bucket, ejecutar el siguiente comando detendrá la configuración de logging existente.
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKETPor ejemplo, si tienes un bucket llamado gs://my-enormous-bucket alojado en el proyecto my-storage-project, el prefijo debería ser PROJECT_my-storage-project_BUCKET_my-enormous-bucket. Si decides no usar el prefijo personalizado, los objetos de log tendrán el prefijo predeterminado y la columna project_id de la tabla de BigQuery quedará con valores null.
- Habilita los logs en cualquier otro bucket que quieras monitorear, tal como se explicó en el paso anterior.
Cuando los Storage Logs se escriban cada día, se enviará un mensaje al tópico de Pub/Sub. Esos mensajes activarán la Cloud Function. Si el nuevo objeto es un Storage Log, se leerá e insertará en la tabla de BigQuery y luego se moverá al bucket gs://PROCCESSED-LOGS-BUCKET. Si es un Access Log, se moverá a gs://USAGE-LOGS-BUCKET. Cualquier otro objeto permanecerá en el bucket. Si ocurre un error al cargar el log, este se moverá a gs://ERRORS-LOGS-BUCKET.
Quizá te interese conectar la tabla de BigQuery con Google Data Studio y armar un dashboard para visualizar los datos con facilidad.