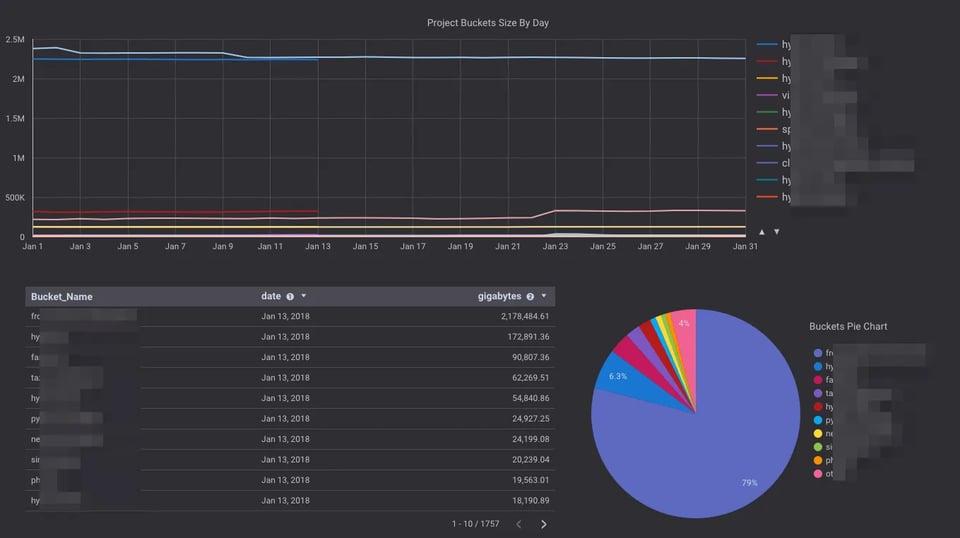
Une méthode économique pour analyser facilement la taille de tous vos buckets Google Cloud Storage en quelques clics, grâce à Pub/Sub, Cloud Functions et BigQuery.
Si vous gérez des buckets contenant un très grand nombre d'objets et que vous cherchez à en connaître la taille, vous avez sans doute remarqué que le dashboard Cloud Storage de Stackdriver Monitoring n'affiche que des estimations et ne fournit pas la taille exacte d'un bucket.
Ces estimations s'écartent d'ailleurs parfois très largement de la taille réelle des buckets.
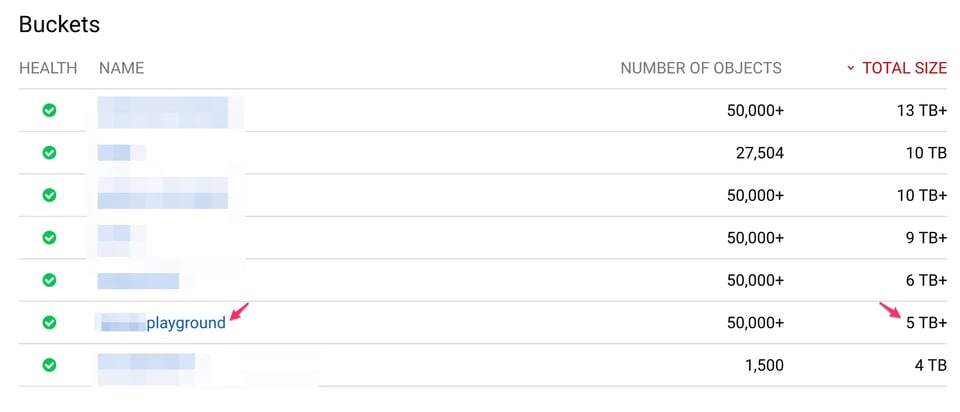
La taille du bucket signalé d'après les Access Logs et Storage Logs est :
"bucket","storage_byte_hours""******playground","1833814969766862"1833814969766862 / 24 = 76408957073619 octets (~69 To)
Quelles solutions s'offrent à vous pour obtenir une vision plus précise de la taille de vos buckets ?
Vous pourriez utiliser la commande gsutil du pour connaître l'espace total occupé par l'ensemble des objets d'un bucket. Toutefois, si vous avez déjà essayé de l'exécuter sur un bucket volumineux contenant des centaines de milliers, voire des millions d'objets, vous savez que l'opération est extrêmement longue. La commande gsutil du calcule l'utilisation de l'espace via des requêtes de listing du bucket, ce qui peut s'avérer à la fois lent et coûteux. L'opération storage.objects.list est une opération de classe A, autrement dit l'opération la plus chère proposée par Cloud Storage.
Une autre méthode pour obtenir un rapport quotidien sur les statistiques de votre bucket consiste à exploiter les Access Logs et Storage Logs de Cloud Storage. Cloud Storage propose ces logs sous forme de fichiers CSV téléchargeables et consultables. Les access logs détaillent toutes les requêtes effectuées sur un bucket donné et sont générés toutes les heures, tandis que les storage logs quotidiens renseignent sur la consommation de stockage du bucket pour la veille.
En règle générale, vous souhaiterez analyser la taille de stockage de vos buckets au quotidien. Exécuter gsutil du n'est pas envisageable, et Stackdriver Monitoring peut s'avérer relativement imprécis pour cette tâche.
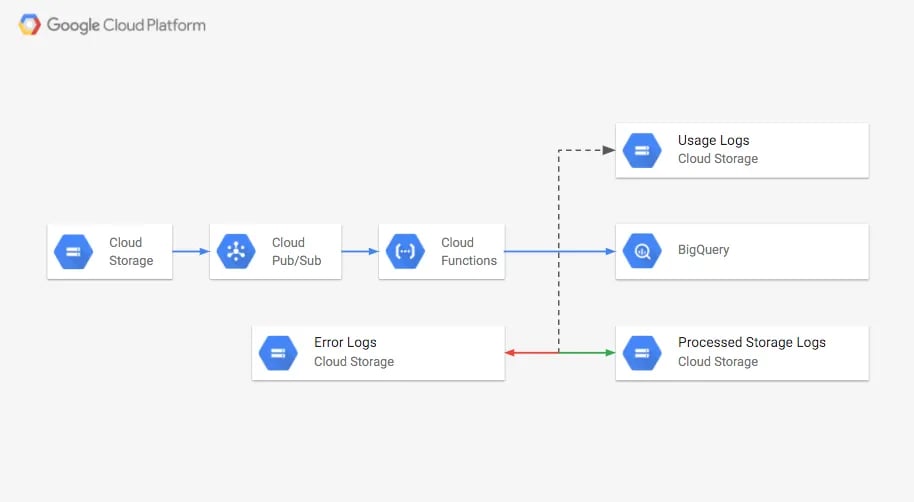
Nous allons donc utiliser les Storage Logs et une Cloud Function (CF) déclenchée par un topic Pub/Sub afin de charger automatiquement le log de consommation de stockage dans BigQuery, où vous pourrez interroger et visualiser la taille du bucket. Les storage logs ainsi chargés seront ensuite déplacés vers un autre bucket. Les logs n'ayant pas été chargés correctement, ainsi que les autres objets, seront déplacés vers un bucket errors.
- Créez un bucket destiné à recevoir les Storage Logs et Access Logs des autres buckets. Positionnez-vous sur le projet souhaité et créez un nouveau bucket pour stocker les logs.
gcloud config set project PROJECT-IDgsutil mb gs://LOGS-BUCKET- Nous souhaitons également séparer les storage logs des usage logs, et disposer d'un bucket pour les logs n'ayant pas pu être chargés dans BigQuery. Les logs seront déplacés depuis gs://LOGS-BUCKET vers le bucket approprié après leur traitement par la CF.
gsutil mb gs://PROCCESSED-LOGS-BUCKETgsutil mb gs://ERRORS-LOGS-BUCKETgsutil mb gs://USAGE-LOGS-BUCKETRemarque : vous pouvez aussi utiliser plusieurs dossiers au sein d'un seul bucket, mais cela demandera quelques ajustements dans le code de la CF.
- Autorisez le compte de service Cloud Storage Analytics de Google à écrire dans notre nouveau bucket :
gsutil acl ch -g [email protected]:W gs://LOGS-BUCKET- Activez les notifications du bucket vers Pub/Sub. La commande suivante crée une configuration de notification pour gs://LOGS-BUCKET : à chaque création, modification, suppression ou archivage d'un objet, un message sera publié dans un topic Pub/Sub avec les informations correspondantes. Comme seule la création d'objets nous intéresse (autrement dit la création des objets de logs), nous surveillerons uniquement l'événement OBJECT_FINALIZE.
gsutil notification create -e OBJECT_FINALIZE -f none gs://LOGS-BUCKET- L'option -f précise les informations de payload du message. Les valeurs disponibles sont json ou none. Notre CF n'utilisant aucune métadonnée du bucket, nous avons retenu none.
- Si vous consultez la page Pub/Sub dans la console développeur, vous constaterez que la commande ci-dessus a créé un topic nommé projects/PROJECT-ID/topics/LOGS-BUCKET. Les messages relatifs aux nouveaux objets seront publiés sur ce topic.
- Créez un nouveau dataset et une nouvelle table BigQuery
bq mk MY_DATASETbq mk —-schema project_id:string,bucket:string,storage_byte_hours:integer,bytes:integer,date:date,update_time:timestamp,filename:string -t MY_DATASET.MY_TABLE- Créez un staging bucket pour la fonction que nous allons déployer
gsutil mb gs://CF-STAGING-BUCKET- Clonez le code de la Cloud Function
git clone https://github.com/doitintl/gcs-stats.gitcd gcs-statsImportant : ouvrez config.js avec un éditeur de texte et adaptez les valeurs en fonction des étapes précédentes.
- Une fois le fichier de configuration modifié, déployez la fonction
gcloud beta functions deploy gcs-stats \ — project PROJECT-ID \ — entry-point gcsStatsHandler \ — stage-bucket gs://CF-STAGING-BUCKET \ — source . \ — trigger-topic LOGS-BUCKET \ — memory 128 \ — timeout 10s- Enfin, nous pouvons activer les Access Logs et Storage Logs sur tout bucket à analyser. Le bucket cible pour les logs est bien entendu celui créé à la première étape : gs://LOGS-BUCKET.
Nous souhaitons disposer d'une colonne contenant l'ID de projet de chaque bucket. Comme les logs ne véhiculent pas cette information, nous utiliserons un préfixe personnalisé pour le nom des fichiers de log. Le préfixe retenu est PROJECT_[ANALYZED-PROJECT-ID]BUCKET[ANALYZED-BUCKET].
Important : si la journalisation est déjà activée sur le bucket, l'exécution de la commande suivante interrompra la configuration de logging existante.
gsutil logging set on -b gs://LOGS-BUCKET -o PROJECT_[ANALYZED-PROJECT-ID]_BUCKET_[ANALYZED-BUCKET] gs://ANALYZED-BUCKETPar exemple, pour un bucket nommé gs://my-enormous-bucket appartenant au projet my-storage-project, le préfixe doit être PROJECT_my-storage-project_BUCKET_my-enormous-bucket. Sans préfixe personnalisé, les objets de log porteront le préfixe par défaut et la colonne project_id de la table BigQuery contiendra des valeurs nulles.
- Activez les logs pour tout autre bucket à surveiller, en reprenant l'étape précédente.
À chaque écriture quotidienne des storage logs, un message est publié dans le topic Pub/Sub. Ces messages déclenchent la Cloud Function. Si le nouvel objet est un storage log, il est lu, inséré dans la table BigQuery, puis déplacé vers le bucket gs://PROCCESSED-LOGS-BUCKET. S'il s'agit d'un access log, il est déplacé vers gs://USAGE-LOGS-BUCKET. Tout autre objet reste dans le bucket. En cas d'erreur lors du chargement du log, celui-ci est déplacé vers gs://ERRORS-LOGS-BUCKET.
Vous pouvez également connecter la table BigQuery à Google Data Studio pour vous bâtir un dashboard et visualiser facilement les données.