BigQueryのコストとパフォーマンスを最適化するための入門ガイド
前回からの続き
本シリーズの第1回では、クエリを実行して最適化を進めるために押さえておきたい前提知識と、運用面の準備事項を整理しました。
第2回となる今回は、お客様のコスト増やパフォーマンス低下を招きがちな、最も典型的なクエリの誤りを取り上げます。後の回で発見した問題を修正する際の参照ガイドとしてご活用ください。

とにかく手を動かして最適化を試したい方は、第3回まで読み飛ばしてください。具体的なクエリと、その活用方法を紹介しています。
コスト増加と複雑化を招く、よくあるクエリの誤り
実データを取得するクエリの解説に入る前に、BigQueryのクエリを書く際に頻繁に見かける誤りをいくつか紹介します。いずれも処理時間を必要以上に伸ばし、ほぼ確実にコスト増にもつながるものです。
これらは公式ドキュメント等にも記載されていますが、ここではDoiT Internationalで日々数百社のお客様を支援する中で特によく目にするパターンを取り上げます。
SELECT \*
これは金額面でも、実際にやってしまっているお客様の数の面でも、おそらく最大のコスト増加要因です。
テーブルやビューの全列を取得しなければならない場面もありますが、ほとんどの場合は不要で、余分なデータをスキャンしているにすぎません。全列が妥当となるのは、ビューですでにスコープを絞り込んでいる場合や、共通テーブル式(CTE)で必要なデータに限定している場合、あるいはファクトテーブルのように小規模で全データが必要なテーブルなど、ごく限られたケースに過ぎません。
こうした例外を除き、データに対してSELECT *を実行すべきではありません。BigQueryはクエリでスキャンしたデータ量に基づいて課金されるため、コストを抑えるには必要な列だけを選択するのが鉄則です。
例えば、5列・5TBのテーブル(各列のデータ量が均等で1列1TBと仮定)を全件スキャンする必要があるとします。このテーブルにSELECT *を実行するとそれだけで25ドルかかりますが、必要な2列だけをSELECTすれば10ドルで済みます。一見わずかな差に思えても、1日100回実行すれば積み重なって大きな差になります。
以下はSELECT *でやってはいけない例(1.6TBのテーブル)です。
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
不要なJOIN・大規模なJOIN
BigQueryをはじめOLAP志向のデータウェアハウスでは、スキーマを非正規化(denormalize)するのがベストプラクティスです。これによりデータ構造が「フラット化」され、従来のリレーショナルデータベースに比べてJOIN操作を減らせます。
BigQueryではデータの保存方式の都合上、JOIN操作が従来型データベースよりも大幅に遅くなります。イメージとしては、同じテーブル内の次の列を読み込む方が、別テーブルをディスクから参照してフィルタし、一致するデータを取り出して結合結果を返すよりはるかに高速です。同じテーブル(またはその複製)にデータが揃っている場合に比べ、読み取りと処理の量が桁違いに増えるからです。
言うまでもなく、大きなテーブル同士のJOINは時間もスキャン量も増えます。必要な列を同じテーブルに持たせておくだけで、処理時間とスキャンコストを大幅に削減できます。
不要なJOINに関連してもう1つ触れておきたいのが「セルフJOIN」です。これはテーブルのデータを時間枠ごとに分割したり、重複行に内部的な順序付け(多くのDBMSでいうランキング)を行ったりする際に使われます。非常に重い処理なので、セルフJOINは避け、BigQueryが提供するウィンドウ関数・分析関数を使うのが基本です。
この機能を使ったことがないお客様も多いので例を示します。以下はINFORMATION_SCHEMAビューで重複するjob IDをランク付けする例です。
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
クロスJOIN
RDBMS出身でソフトウェアエンジニアリングのバックグラウンドを持つ方なら、この見出しを見て「クロスJOINなんて実際に使う人いるの?」と眉をひそめるかもしれません。
意外に思われるかもしれませんが、用途はあります(主に純粋に集合演算的なシナリオです)。さらにBigQueryでは、どうしてもクロスJOINを使わざるを得ない場面もあります。代表例は配列を行に展開するUNNESTで、分析データを扱う上では非常に一般的な操作です。
以下は本シリーズの後半で使うクエリから抜粋した、CROSS JOINでRECORD型の列をUNNESTする例です。
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
問題は、クロスJOINをクエリの最も内側で実行してしまい、最終出力に渡されるよりはるかに大量のデータを取り込んでしまうケースが多いことです。後続フェーズで捨てられるデータを読み込むためにコストを払っていることになります。あとで破棄されるとしても、BigQueryはスキャンして読み込んだ分の料金を請求します。
とはいえ、BigQueryのクエリアナライザーはこうしたケースを検出し、実行プランを組み替えて影響を抑える能力が向上しています。本記事の執筆やお客様へのデモを進める中でも、2022年を通じて改善が進み、一部のケースでは検出と並べ替えが行われるのを確認しました。ただし、悪いクエリを常に補正してくれると過信するのは禁物です。
原則として、クロスJOINはクエリ内でできる限り外側で行うようにしてください。そうすることでクロスJOIN前に読み込むデータ量を減らし、スロット消費とBigQueryの課金対象データ量の両方を抑えられます。
共通テーブル式(CTE)
共通テーブル式、略してCTEは、SQLコードを劇的に整理してくれる優れた仕組みです。
馴染みのない方のために説明すると、CTEは現在のジョブ中だけ存在するインメモリの一時テーブルのようなものです。サブクエリが何階層にもネストして見通しが悪くなったSQLを分割するのに最適です。
ただし、CTEは主に可読性のためのものであり、パフォーマンス向上のための仕組みではない点に注意してください。CTEはデータをマテリアライズしないため、複数回参照されるたびに再実行されます。本シリーズのGitHubリポジトリにあるクエリはまさに好例で、性能よりも可読性と修正のしやすさを優先して書かれています。
そのうえで、コストとパフォーマンス面で最も多く見られる落とし穴は、1つのクエリ内で定義したCTEを複数回参照し、その都度CTEクエリが実行されてしまうケースです。結果として、同じデータの読み取りに対して何度も課金されることになります。
この点でもBigQueryのクエリアナライザーは進化を続けており、こうした挙動を検出して実行プランを修正し、CTEを1回だけ実行するように調整することもあります。本記事の執筆中に最終確認したところ、複数回の実行のうちCTEが1回しか走らないケースもあれば、複数回走るケースもありました。
WHERE句でパーティションを使わない
パーティションは、コスト削減と読み取り性能の最適化において、BigQueryの最も重要な機能の1つです。にもかかわらず活用されていないことが多く、本来不要なはずのコストがクエリに費やされています。
パーティションは、特定の列の整数値またはタイムスタンプ/日時/日付値に基づいて、テーブルをディスク上で複数の物理パーティションに分割します。パーティション化されたテーブルから読み取る際にその列で範囲指定すれば、対象範囲を含むパーティションのみがスキャンされ、テーブル全体のスキャン(いわゆるテーブルスキャン)を避けられます。
例えば以下のクエリは、過去14日間の全クエリの合計課金バイト数を取得しています。JOBS_BY_PROJECTはcreation_time列でパーティション化されており(スキーマのドキュメントはこちら)、合計サイズ約17GBのサンプルテーブルに対して実行すると、処理データ量は884MBで済みます。
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
対照的に、以下のクエリはstart_time列を使っています。これはパーティション化されていない列ですが、通常creation_timeとは1秒未満の差しかありません。同じサンプルデータセットに対して実行すると、処理データ量は15GBになります。テーブル全体をスキャンして該当値を取り出しているためです。
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
このように、小さなデータセットでも差は歴然です。1つ目のクエリは約0.004ドル、2つ目は約0.75ドルなので、パーティション列を適切に使わないだけで約21倍のコストになります。
パフォーマンス面でも、1つ目は約2秒、2つ目は約5秒で完了しました。これだけ小さなテーブルなら大した差ではありませんが、数TB級のテーブルにスケールすれば、1回の実行で数分単位の差が生じることも珍しくありません。
複雑すぎるビューの利用
これはBigQueryに限らず広く見られる問題で、複雑なビューを作成してパフォーマンスを劣化させてしまうケースです。BigQueryも他の擬似的・本格的なリレーショナルデータベースと同様に、ビューという仕組みをサポートしています。ビューとは要するに、結果をテーブルのように見せかけて扱いやすくするクエリのことです。
ビューはロジックを抽象化したり、見せたくない列をユーザーから隠したりと、用途は数えきれないほどあります。一方で、結果がマテリアライズされない、つまりディスクに保存されないため、参照されるたびにクエリエンジンが結果を再計算して呼び出し元に返す必要があるという欠点もあります。
そのため、ビューに重い計算が含まれていて、ビューが参照されるたびにその計算が走ると、呼び出し元のクエリの性能に無視できない影響が出ます。各ビューに含まれるロジックの量を見直し、複雑すぎるようであれば別のテーブルに事前計算しておくか、マテリアライズドビューに置き換えてパフォーマンスを改善するのが賢明です。
小さなインサートの繰り返し
特にストリーミング系のアプリケーションでは、1件または少数のレコードをテーブルに挿入したい場面が頻繁にあります。問題は、BigQueryはその名のとおり「Big」、つまり大きなデータの塊をまとめて処理するのが得意だということです。
小さなインサートは、1KBでも10MBでも、ほぼ同じ時間とスロットを消費します。つまり1KBの行を1,000回挿入すると、10MB分の行を1回で挿入する場合と比べて最大1,000倍ものスロット消費時間がかかる可能性があります。
データはバッチにまとめて一括で挿入するのがベストです。これはストリーミング処理にも当てはまります。Streaming Insertsの利用は避け、データをバッチ化して到着期限を設けたうえでまとめてインサートするのが望ましいでしょう。
DMLステートメントの多用
これは、BigQueryを従来型のRDBMSと同じ感覚で扱い、データを気軽に作り直してしまう人がよく陥る大きな問題です。
比較的よく見かける代表的なパターンは次のようなものです。
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
SQL ServerやMySQLなどのRDBMSであれば、これらは比較的低コストな操作で、データウェアハウス用途でなければ日常的に行われている処理でしょう。
一方、BigQueryではこれらは非常に重いクエリで、日常的な利用は避けるべきです。BigQueryのDMLステートメントは「遅い」ことで知られており、DMLに最適化されている従来型RDBMSとは違い、BigQueryはこの種の処理に最適化されていません。
このような処理の代わりに、新しい行に最新であることを示すタイムスタンプを付けて挿入し、履歴が不要であれば古い行を定期的に削除する「追記モデル(additive model)」を検討してください。BigQueryは分析向けにチューニングされたデータウェアハウスであり、トランザクション的にデータを変更するよりも、既存データを扱うことに最適化されている点を忘れないでください。
これを体感するには、同じテーブルをRDBMSとBigQueryに作成し、大量のサンプルデータを挿入して、MERGEまたはUPDATEステートメントの実行プラン(BigQueryではクエリプラン)を比較してみるのが効果的です。クエリプランを見ると、BigQueryではDDLやJOIN(MERGEの場合)の部分にかかる時間が圧倒的に長く、ステートメントによっては複数のステップに分かれていることに気づくはずです。
具体例として、crypto_bitcoinパブリックデータセットのtransactionsテーブルに対し、一致しない場合に挿入する非常にシンプルなマージステートメントを実行しています。1年分のトランザクションのサブセットを、トランザクション全体とマージしています(それぞれ約400GBと1.54TB)。下図のとおり、フェーズ間でデータの再パーティション化が大量に発生し、処理時間の大半がJOIN操作に費やされていることがわかります。これがより複雑なマージであれば、フェーズはさらに増え、再パーティション化の段階も多くなるでしょう。
このときに出力された実行プランは以下のとおりです(規模が大きいことを示すため、2枚のスクリーンショットに分割しています)。
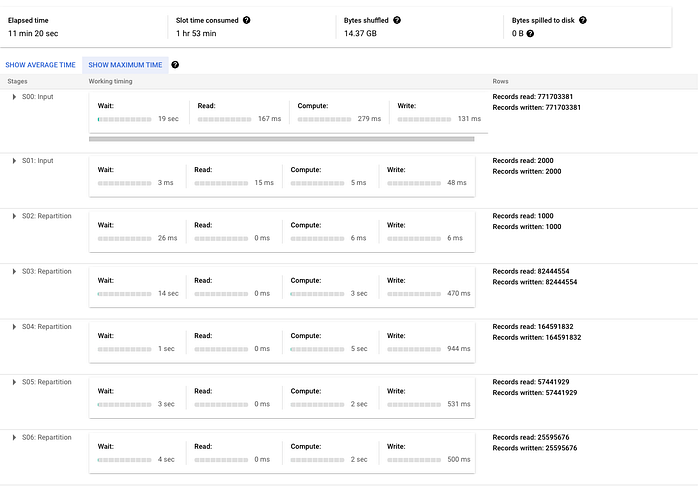
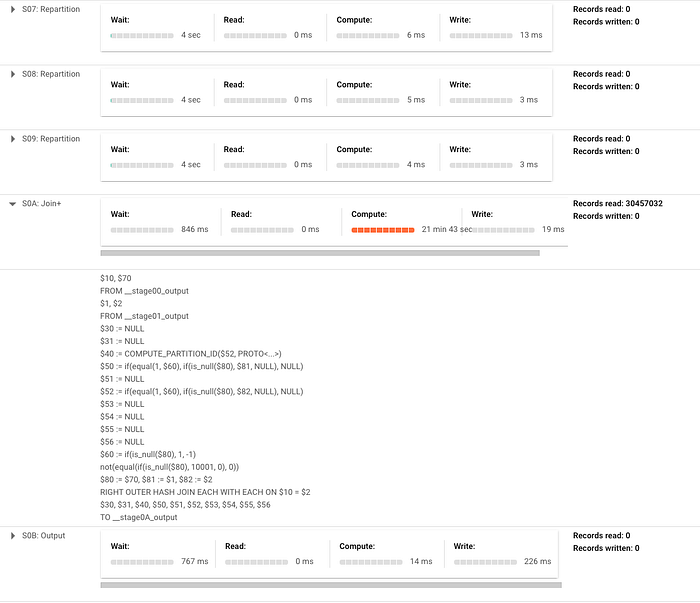
次回予告
以上で本シリーズの第2回は終了です。主に理論的な内容を扱う最後のパートでもありました。次回はいよいよ、実際にBigQueryのメタデータを参照しながら分析を進めていきます。