Guida introduttiva all'ottimizzazione di costi e performance su BigQuery
Riprendiamo il discorso
Nella prima parte di questa serie ho illustrato alcune nozioni preliminari e le attività operative necessarie per eseguire le query e avviare il processo di ottimizzazione.
In questa parte affronterò gli errori di scrittura delle query più comuni che finiscono per costare di più ai nostri clienti o che causano problemi di performance. Consideratela una guida introduttiva da consultare in seguito per capire come correggere ciò che individuerete nelle prossime parti della serie.

Se non vedete l'ora di mettere in pratica le ottimizzazioni, saltate pure direttamente alla parte 3 della serie, dove fornirò alcune query e spiegherò come utilizzarle.
Errori comuni nelle query che fanno aumentare costi e complessità
Prima di passare alle query che vi forniranno i dati concreti, voglio mostrarvi alcuni esempi degli errori più frequenti che osserviamo nella scrittura delle query BigQuery: errori che possono allungare i tempi di elaborazione e, quasi sempre, far lievitare anche i costi.
Sono tutti documentati online, ma voglio raccogliere qui i più ricorrenti tra quelli che noi di DoiT International riscontriamo regolarmente lavorando con centinaia di clienti.
SELECT \*
Questa è probabilmente la principale causa di costi extra, sia in termini di spesa sia per il numero di clienti che la commettono.
Esistono alcuni scenari in cui è effettivamente necessario selezionare tutte le colonne di una tabella o di una vista, ma nella maggior parte dei casi è superfluo e si traduce solo in una scansione di dati in eccesso. Questi scenari si presentano in genere quando avete già ristretto l'ambito di una vista o utilizzato una Common-Table-Expression (CTE) per ottenere solo i dati necessari, oppure quando avete una tabella piccola, come una fact table, in cui servono tutti i dati: per citarne solo due tra i più comuni.
Al di fuori di questi pochi casi, non dovreste mai eseguire un SELECT * sui vostri dati. Poiché BigQuery fattura in base alla quantità di dati scansionati nelle query, dovete sempre selezionare solo ciò che vi serve per ridurre al minimo il costo.
Per esempio, supponete di avere una tabella da 5 TB con 5 colonne (ipotizzando che ogni colonna contenga la stessa quantità di dati, quindi 1 TB ciascuna) e di doverla scansionare interamente. Eseguire un SELECT * su questa tabella costerà 25 dollari per quella singola query, mentre un SELECT sulle sole 2 colonne necessarie costerà appena 10 dollari. Può sembrare poco, ma se eseguite questa query 100 volte al giorno il conto può davvero salire.
Ecco un esempio di cosa NON fare con un SELECT * (tabella da 1,6 TB):
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
Join inutili o di grandi dimensioni
In BigQuery e negli altri data warehouse orientati a una strategia OLAP, la best practice è denormalizzare gli schemi del database. In sostanza, questa operazione "appiattisce" le strutture dati e riduce il numero di join necessari rispetto a un database relazionale tradizionale.
Il motivo è che un'operazione di join è molto più lenta in BigQuery rispetto a un database tradizionale, per via di come i dati sono memorizzati nel sistema sottostante. Per dare un'idea: leggere la colonna successiva all'interno di una tabella sarà molto più veloce che cercare un'altra tabella su disco, filtrare i dati, recuperare quelli corrispondenti e poi restituire i dati uniti. Si tratta di un numero molto maggiore di letture ed elaborazioni rispetto al semplice avere i dati (o una loro copia) nella stessa tabella.
Va da sé che unire tabelle di grandi dimensioni richiederà più tempo e scansionerà più dati: evitare questa operazione e memorizzare semplicemente la colonna necessaria nella stessa tabella consente di risparmiare un'enorme quantità di tempo di elaborazione e di costi di scansione.
Per chiudere il discorso sui join inutili, c'è il concetto di "self-join", in cui i dati di una tabella devono essere suddivisi in finestre temporali oppure ordinati internamente sulle righe duplicate (operazione chiamata ranking in molti sistemi di database). È un processo MOLTO lento, quindi la raccomandazione generale è di non utilizzarlo e ricorrere invece alle window function o alle funzioni analitiche messe a disposizione da BigQuery.
Per fare un esempio, dato che molti clienti non utilizzano mai questa funzionalità, ecco come effettuare il ranking dei job ID duplicati nella vostra view INFORMATION_SCHEMA:
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
Cross Join
Chi proviene da un RDBMS e ha un background da software engineer potrebbe leggere questa sezione con un sopracciglio alzato e chiedersi: ma c'è davvero qualcuno che usa i cross join????
Che ci crediate o no, hanno effettivamente delle applicazioni (per lo più in scenari puramente set-based) e su BigQuery in alcuni casi sono persino indispensabili. L'esempio principale è l'unnesting degli array in righe, un'operazione piuttosto comune quando si lavora con dati analitici.
Ecco un esempio tratto da alcune query usate più avanti nella serie, che mostra l'unnesting di una colonna di tipo RECORD tramite un CROSS JOIN:
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
Il problema è che spesso, quando si utilizza un cross join, lo si colloca come operazione più interna della query, finendo così per recuperare MOLTI più dati di quelli che verranno poi passati all'output. In pratica vi viene fatturata la lettura di una grande quantità di dati che con ogni probabilità verrà scartata in una fase successiva, ma anche se viene scartata in seguito BigQuery ve la addebiterà comunque, perché ha dovuto scansionarla e leggerla.
Detto questo, l'analizzatore di query di BigQuery sta migliorando nel rilevare questi casi e nel correggere i piani di esecuzione per mitigare il problema. Durante la stesura di questi articoli e nelle demo ai clienti ho notato miglioramenti nel corso del 2022, con alcuni casi rilevati e riordinati per evitare lo scenario descritto, ma come sempre non date mai per scontato che il sistema correggerà comportamenti scorretti nelle query.
La regola d'oro è eseguire sempre i cross join nel punto più esterno possibile della query. In questo modo si riduce la quantità di dati letti prima del cross join, abbattendo il numero di slot utilizzati e la quantità di dati che BigQuery vi addebiterà.
Common Table Expression (CTE)
Le Common Table Expression, o CTE in breve, sono strumenti straordinari che semplificano enormemente il codice SQL.
Per chi non le conoscesse, sono in pratica tabelle temporanee in memoria che esistono solo per il job corrente. Un ottimo modo per spezzare codice SQL che si sta avventurando in più livelli di sottoquery.
Tenete presente che si usano principalmente per la leggibilità e non per le performance, dato che non materializzano i dati e vengono rieseguite ogni volta che le si richiama. Esempi emblematici sono tutte le query nel repository GitHub di questa serie, scritte molto più per leggibilità e facilità di modifica che per performance.
Detto questo, il principale problema di costi e performance che riscontriamo è l'utilizzo di una CTE in una query con successivi richiami multipli, che fanno sì che la query della CTE venga eseguita più volte. Significa che vi verrà fatturata la lettura dei dati più volte.
Anche in questo caso l'analizzatore di query di BigQuery sta migliorando e talvolta rileva questo comportamento, correggendo il piano di esecuzione in modo da eseguire la CTE una sola volta. Un controllo finale durante la stesura di questo caso d'uso ha mostrato che, in più esecuzioni delle stesse query, alcune eseguivano le CTE una sola volta e altre più volte.
Mancato utilizzo delle partizioni nelle clausole WHERE
Le partizioni sono una delle funzionalità più importanti di BigQuery per ridurre i costi e ottimizzare le performance di lettura. In molti casi, però, non vengono sfruttate e si finisce per spendere molto in query che non dovrebbero costare così tanto.
Una partizione suddivide una tabella su disco in diverse partizioni fisiche, basate su un valore intero o di tipo timestamp/datetime/date in una colonna specifica. Quando leggete dati da una tabella partizionata e specificate un intervallo su quella colonna, dovrete scansionare solo le partizioni che contengono i dati di quell'intervallo, e non l'intera tabella, operazione nota nel mondo dei database come table scan.
Per esempio, nella query seguente sto recuperando il totale dei byte fatturati per tutte le query degli ultimi 14 giorni. La JOBS_BY_PROJECT è partizionata sulla colonna creation_time (la documentazione dello schema è qui) e, eseguita su una tabella di esempio di circa 17 GB totali, elabora 884 MB di dati.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Per contro, la query seguente utilizza la colonna start_time, che non è partizionata ma di solito si discosta solo di frazioni di secondo dal valore di creation_time: eseguita sullo stesso dataset di esempio, elabora 15 GB di dati. Il motivo è che scansiona l'intera tabella per estrarre i valori richiesti.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Come si vede, la differenza è notevole anche su un dataset più piccolo: la prima query costa circa 0,004 USD e la seconda circa 0,75 USD, quindi in questo caso non sfruttare correttamente una colonna partizionata risulta circa 21 volte più costoso.
Sul fronte performance, la prima query ha richiesto circa 2 secondi e la seconda circa 5. Non è molto su una tabella così piccola, ma scalando a una tabella da diversi TB la differenza potrebbe facilmente essere di vari minuti per ogni esecuzione.
Utilizzo di view eccessivamente complesse
Si tratta di un problema molto diffuso, ben oltre i sacri confini di BigQuery: la creazione di view complesse che degradano le performance. BigQuery, come la maggior parte dei suoi parenti pseudo e veramente relazionali, supporta un costrutto chiamato view, che è in sostanza una query che presenta i propri risultati come se fossero una tabella, per facilitarne l'interrogazione.
Le view sono estremamente utili per astrarre la logica, nascondere colonne agli utenti che non hanno bisogno di vederle e per innumerevoli altri motivi. Ai pregi si accompagna però un rovescio della medaglia: i risultati di una query non vengono materializzati, ovvero non vengono memorizzati su disco, quindi a ogni interrogazione il motore della query potrebbe dover ricalcolare i risultati da restituire alla query chiamante.
Di conseguenza, se la view contiene calcoli piuttosto pesanti che vengono eseguiti ogni volta che la view viene interrogata, ciò comporta un impatto significativo sulle performance della query chiamante. Conviene quindi valutare quanta logica c'è in ogni view e, se è troppo complessa, potrebbe essere preferibile pre-calcolarla in un'altra tabella o spostarla in una materialized view per migliorare le performance.
Inserimenti piccoli
Capita spesso di dover inserire un singolo record o un piccolo gruppo di record in una tabella, soprattutto in alcune applicazioni di tipo streaming. Il problema è che BigQuery porta nel nome stesso la sua natura: Big, ed è progettato per elaborare grandi blocchi di dati alla volta.
Gli inserimenti piccoli richiedono in genere lo stesso tempo e lo stesso utilizzo di slot per inserire 1 KB o 10 MB. Quindi 1.000 inserimenti di una riga da 1 KB possono arrivare a consumare fino a 1.000 volte gli slot di un singolo inserimento di 10 MB di righe.
Conviene raggruppare i dati e inserirli in batch invece di effettuare numerosi inserimenti piccoli. Questo vale anche per le operazioni di streaming: evitate gli Streaming Insert, raggruppate i dati e inseriteli con una scadenza di arrivo.
Uso eccessivo di istruzioni DML
Si tratta di un problema rilevante che si presenta tipicamente quando si tratta BigQuery come un sistema RDBMS tradizionale e si ricreano i dati a piacimento.
Tre esempi emblematici che si vedono con relativa frequenza sono strutturati così:
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
Eseguire queste operazioni su un RDBMS come SQL Server o MySQL sarebbe relativamente poco costoso ed è una pratica abbastanza diffusa quando non si lavora in un contesto di data warehouse.
Per contro, in BigQuery sono query con performance pessime e andrebbero evitate nell'uso ordinario. Le istruzioni DML di BigQuery sono notoriamente lente perché il sistema non è affatto ottimizzato per esse, a differenza di un RDBMS tradizionale dove invece lo è.
Invece di procedere così, considerate l'uso di un "modello additivo", in cui le nuove righe vengono inserite con un timestamp che ne segnala l'attualità, rimuovendo poi periodicamente le righe più vecchie se la cronologia non serve. Ricordate che BigQuery è un data warehouse ottimizzato per l'analitica: è quindi più adatto a lavorare con dati esistenti che a modificarli in modo transazionale.
Un buon modo per illustrare questo concetto è creare la stessa tabella nel vostro RDBMS e in BigQuery, inserire una grande quantità di dati di esempio e osservare il piano di esecuzione di un'istruzione MERGE o UPDATE (in BigQuery sarà il query plan). Confrontando i query plan, noterete che BigQuery impiega molto più tempo nella sezione DDL o JOIN (per le istruzioni MERGE) della query e, a seconda dell'istruzione, potrebbe avere persino più passaggi.
Per illustrare il punto, sto eseguendo un'istruzione merge molto semplice che inserisce i record quando non c'è corrispondenza, sulla tabella delle transazioni del dataset pubblico crypto_bitcoin. Sto facendo il merge di un sottoinsieme della tabella composto da un anno di transazioni con l'intero set di transazioni (rispettivamente circa 400 GB e 1,54 TB). Nell'esempio mostrato di seguito noterete che il sistema deve effettuare molto repartitioning di dati tra le fasi e che la maggior parte del tempo è impiegata in un'operazione di JOIN. Tenete presente che, se si trattasse di un merge più complesso, queste fasi diventerebbero ancora più ampie e con più fasi di repartitioning.
Ecco il piano di esecuzione prodotto (suddiviso in due screenshot perché è piuttosto grande, a riprova del concetto):
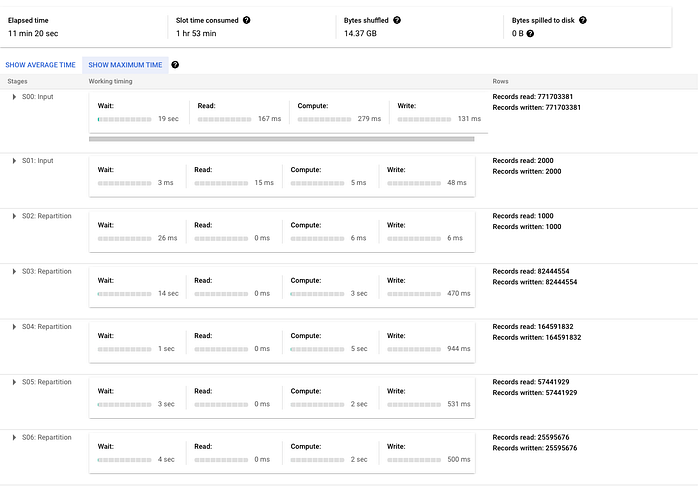
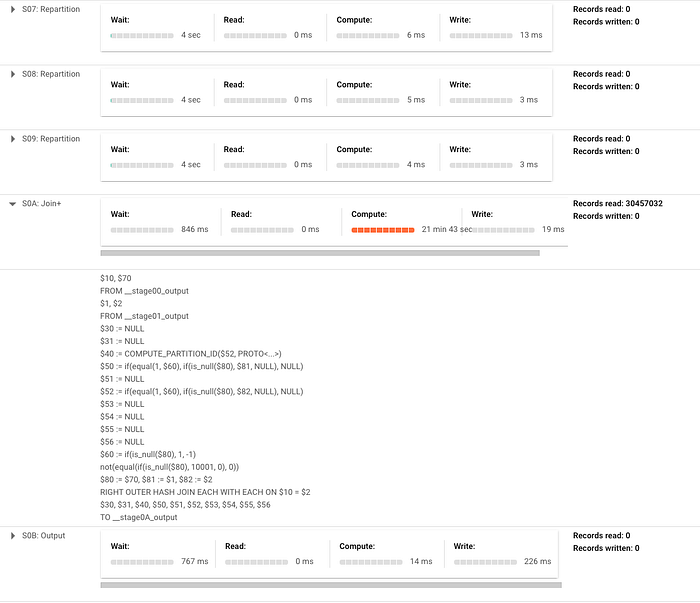
Prossimamente
Si conclude così la seconda parte di questa serie, l'ultima sezione di taglio prevalentemente teorico. Nella prossima passeremo all'analisi concreta dei vostri metadati BigQuery.